 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing-Based Knowledge Graph Construction for Drug Side Effects Using Large Language Models with an Application on Semaglutide
Apr 08, 2025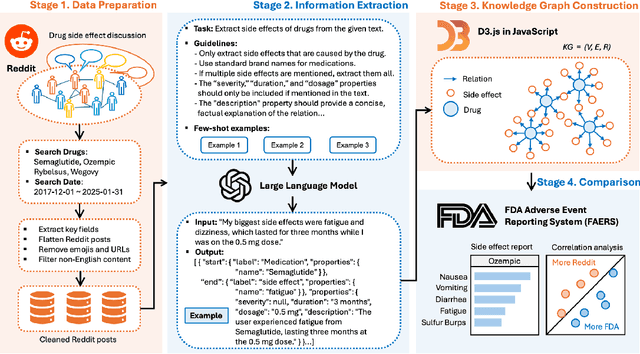

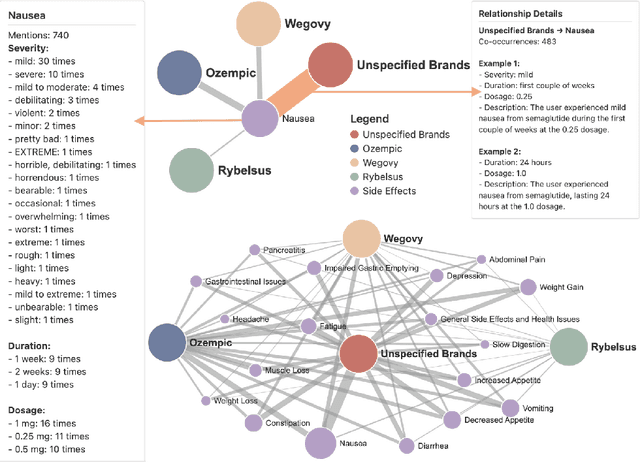
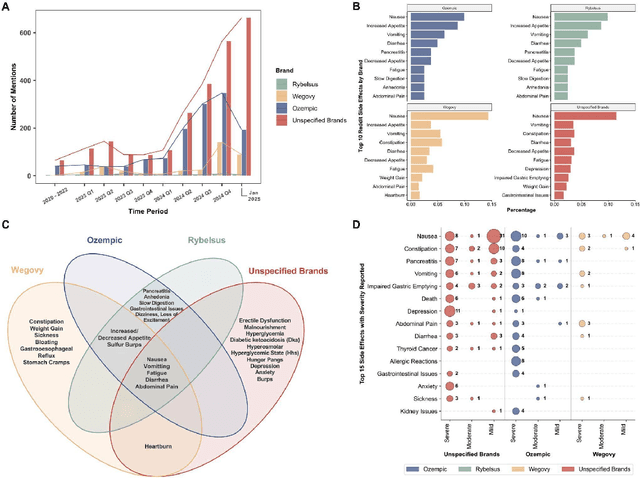
Social media is a rich source of real-world data that captures valuable patient experience information for pharmacovigilance. However, mining data from unstructured and noisy social media content remains a challenging task. We present a systematic framework that leverages large language models (LLMs) to extract medication side effects from social media and organize them into a knowledge graph (KG). We apply this framework to semaglutide for weight loss using data from Reddit. Using the constructed knowledge graph, we perform comprehensive analyses to investigate reported side effects across different semaglutide brands over time. These findings are further validated through comparison with adverse events reported in the FAERS database, providing important patient-centered insights into semaglutide's side effects that complement its safety profile and current knowledge base of semaglutide for both healthcare professionals and patients. Our work demonstrates the feasibility of using LLMs to transform social media data into structured KGs for pharmacovigilance.
Patients Speak, AI Listens: LLM-based Analysis of Online Reviews Uncovers Key Drivers for Urgent Care Satisfaction
Mar 26, 2025Investigating the public experience of urgent care facilities is essential for promoting community healthcare development. Traditional survey methods often fall short due to limited scope, time, and spatial coverage. Crowdsourcing through online reviews or social media offers a valuable approach to gaining such insights. With recent advancements in large language models (LLMs), extracting nuanced perceptions from reviews has become feasible. This study collects Google Maps reviews across the DMV and Florida areas and conducts prompt engineering with the GPT model to analyze the aspect-based sentiment of urgent care. We first analyze the geospatial patterns of various aspects, including interpersonal factors, operational efficiency, technical quality, finances, and facilities. Next, we determine Census Block Group(CBG)-level characteristics underpinning differences in public perception, including population density, median income, GINI Index, rent-to-income ratio, household below poverty rate, no insurance rate, and unemployment rate. Our results show that interpersonal factors and operational efficiency emerge as the strongest determinants of patient satisfaction in urgent care, while technical quality, finances, and facilities show no significant independent effects when adjusted for in multivariate models. Among socioeconomic and demographic factors, only population density demonstrates a significant but modest association with patient ratings, while the remaining factors exhibit no significant correlations. Overall, this study highlights the potential of crowdsourcing to uncover the key factors that matter to residents and provide valuable insights for stakeholders to improve public satisfaction with urgent care.
AIPatient: Simulating Patients with EHRs and LLM Powered Agentic Workflow
Sep 27, 2024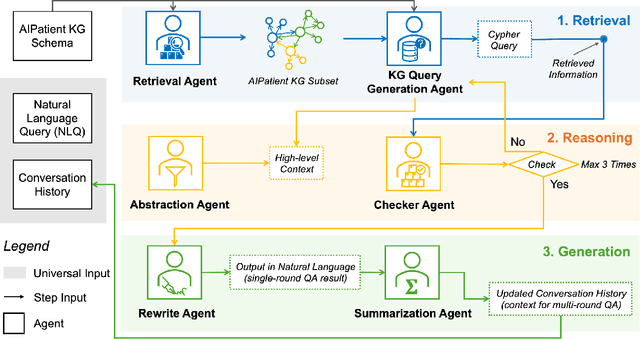
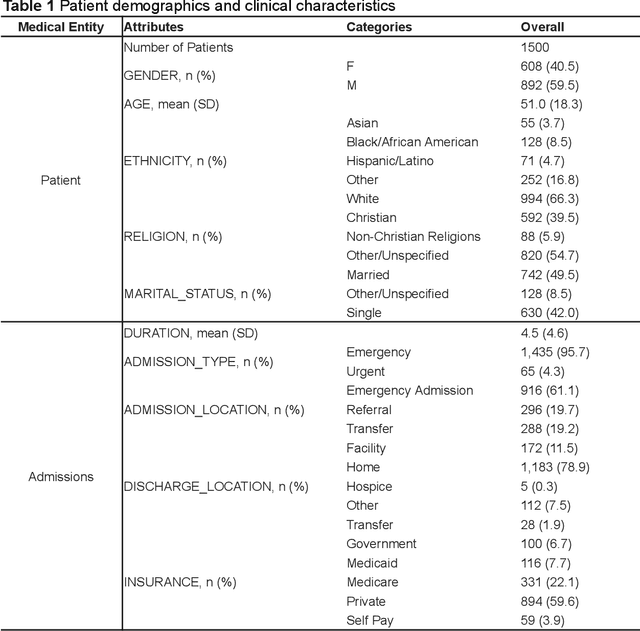
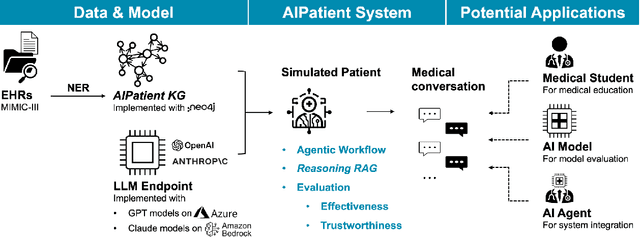
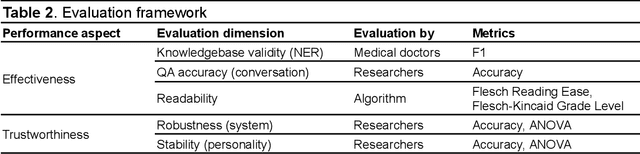
Simulated patient systems play a crucial role in modern medical education and research, providing safe, integrative learning environments and enabling clinical decision-making simulations. Large Language Models (LLM) could advance simulated patient systems by replicating medical conditions and patient-doctor interactions with high fidelity and low cost. However, ensuring the effectiveness and trustworthiness of these systems remains a challenge, as they require a large, diverse, and precise patient knowledgebase, along with a robust and stable knowledge diffusion to users. Here, we developed AIPatient, an advanced simulated patient system with AIPatient Knowledge Graph (AIPatient KG) as the input and the Reasoning Retrieval-Augmented Generation (Reasoning RAG) agentic workflow as the generation backbone. AIPatient KG samples data from Electronic Health Records (EHRs) in the Medical Information Mart for Intensive Care (MIMIC)-III database, producing a clinically diverse and relevant cohort of 1,495 patients with high knowledgebase validity (F1 0.89). Reasoning RAG leverages six LLM powered agents spanning tasks including retrieval, KG query generation, abstraction, checker, rewrite, and summarization. This agentic framework reaches an overall accuracy of 94.15% in EHR-based medical Question Answering (QA), outperforming benchmarks that use either no agent or only partial agent integration. Our system also presents high readability (median Flesch Reading Ease 77.23; median Flesch Kincaid Grade 5.6), robustness (ANOVA F-value 0.6126, p<0.1), and stability (ANOVA F-value 0.782, p<0.1). The promising performance of the AIPatient system highlights its potential to support a wide range of applications, including medical education, model evaluation, and system integration.
Large Language Models in Biomedical and Health Informatics: A Bibliometric Review
Mar 26, 2024Large Language Models (LLMs) have rapidly become important tools in Biomedical and Health Informatics (BHI), enabling new ways to analyze data, treat patients, and conduct research. This bibliometric review aims to provide a panoramic view of how LLMs have been used in BHI by examining research articles and collaboration networks from 2022 to 2023. It further explores how LLMs can improve Natural Language Processing (NLP) applications in various BHI areas like medical diagnosis, patient engagement, electronic health record management, and personalized medicine. To do this, our bibliometric review identifies key trends, maps out research networks, and highlights major developments in this fast-moving field. Lastly, it discusses the ethical concerns and practical challenges of using LLMs in BHI, such as data privacy and reliable medical recommendations. Looking ahead, we consider how LLMs could further transform biomedical research as well as healthcare delivery and patient outcomes. This bibliometric review serves as a resource for stakeholders in healthcare, including researchers, clinicians, and policymakers, to understand the current state and future potential of LLMs in BHI.