 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame-theoretic LLM: Agent Workflow for Negotiation Games
Nov 12, 2024



This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LLMs across a spectrum of complete-information and incomplete-information games. Our findings reveal that LLMs frequently deviate from rational strategies, particularly as the complexity of the game increases with larger payoff matrices or deeper sequential trees. To address these limitations, we design multiple game-theoretic workflows that guide the reasoning and decision-making processes of LLMs. These workflows aim to enhance the models' ability to compute Nash Equilibria and make rational choices, even under conditions of uncertainty and incomplete information. Experimental results demonstrate that the adoption of these workflows significantly improves the rationality and robustness of LLMs in game-theoretic tasks. Specifically, with the workflow, LLMs exhibit marked improvements in identifying optimal strategies, achieving near-optimal allocations in negotiation scenarios, and reducing susceptibility to exploitation during negotiations. Furthermore, we explore the meta-strategic considerations of whether it is rational for agents to adopt such workflows, recognizing that the decision to use or forgo the workflow constitutes a game-theoretic issue in itself. Our research contributes to a deeper understanding of LLMs' decision-making capabilities in strategic contexts and provides insights into enhancing their rationality through structured workflows. The findings have implications for the development of more robust and strategically sound AI agents capable of navigating complex interactive environments. Code and data supporting this study are available at \url{https://github.com/Wenyueh/game_theory}.
Wait, but Tylenol is Acetaminophen... Investigating and Improving Language Models' Ability to Resist Requests for Misinformation
Sep 30, 2024Background: Large language models (LLMs) are trained to follow directions, but this introduces a vulnerability to blindly comply with user requests even if they generate wrong information. In medicine, this could accelerate the generation of misinformation that impacts human well-being. Objectives/Methods: We analyzed compliance to requests to generate misleading content about medications in settings where models know the request is illogical. We investigated whether in-context directions and instruction-tuning of LLMs to prioritize logical reasoning over compliance reduced misinformation risk. Results: While all frontier LLMs complied with misinformation requests, both prompt-based and parameter-based approaches can improve the detection of logic flaws in requests and prevent the dissemination of medical misinformation. Conclusion: Shifting LLMs to prioritize logic over compliance could reduce risks of exploitation for medical misinformation.
AIPatient: Simulating Patients with EHRs and LLM Powered Agentic Workflow
Sep 27, 2024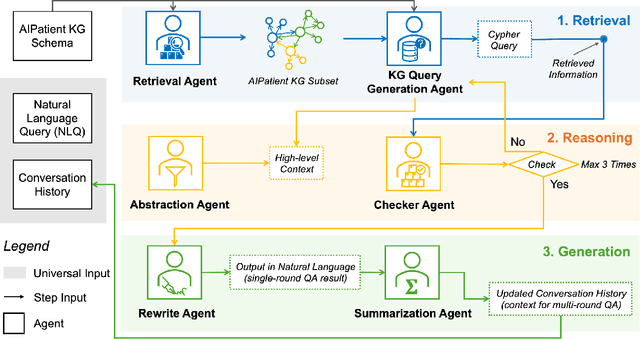
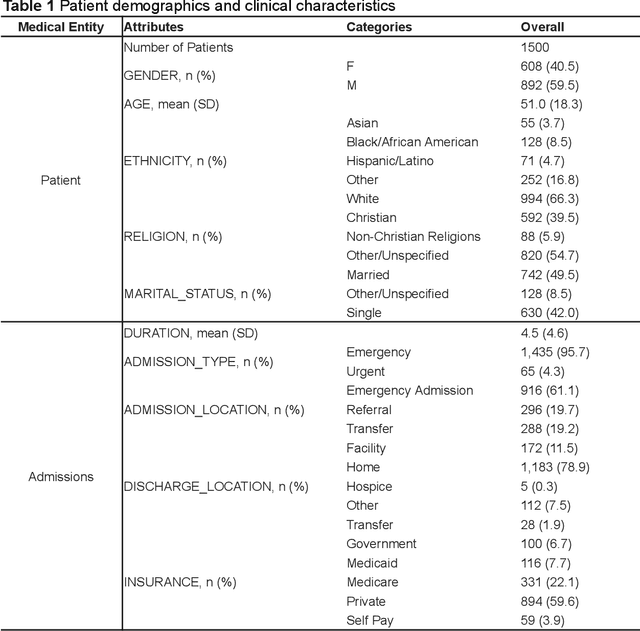
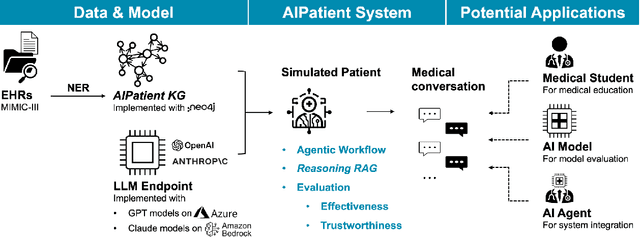
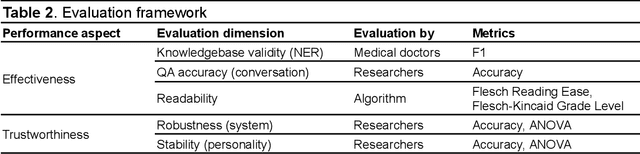
Simulated patient systems play a crucial role in modern medical education and research, providing safe, integrative learning environments and enabling clinical decision-making simulations. Large Language Models (LLM) could advance simulated patient systems by replicating medical conditions and patient-doctor interactions with high fidelity and low cost. However, ensuring the effectiveness and trustworthiness of these systems remains a challenge, as they require a large, diverse, and precise patient knowledgebase, along with a robust and stable knowledge diffusion to users. Here, we developed AIPatient, an advanced simulated patient system with AIPatient Knowledge Graph (AIPatient KG) as the input and the Reasoning Retrieval-Augmented Generation (Reasoning RAG) agentic workflow as the generation backbone. AIPatient KG samples data from Electronic Health Records (EHRs) in the Medical Information Mart for Intensive Care (MIMIC)-III database, producing a clinically diverse and relevant cohort of 1,495 patients with high knowledgebase validity (F1 0.89). Reasoning RAG leverages six LLM powered agents spanning tasks including retrieval, KG query generation, abstraction, checker, rewrite, and summarization. This agentic framework reaches an overall accuracy of 94.15% in EHR-based medical Question Answering (QA), outperforming benchmarks that use either no agent or only partial agent integration. Our system also presents high readability (median Flesch Reading Ease 77.23; median Flesch Kincaid Grade 5.6), robustness (ANOVA F-value 0.6126, p<0.1), and stability (ANOVA F-value 0.782, p<0.1). The promising performance of the AIPatient system highlights its potential to support a wide range of applications, including medical education, model evaluation, and system integration.
Enhancing Autism Spectrum Disorder Early Detection with the Parent-Child Dyads Block-Play Protocol and an Attention-enhanced GCN-xLSTM Hybrid Deep Learning Framework
Aug 29, 2024
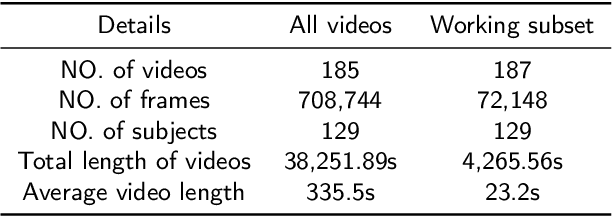

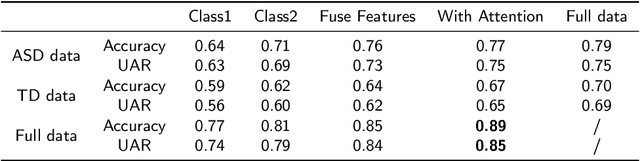
Autism Spectrum Disorder (ASD) is a rapidly growing neurodevelopmental disorder. Performing a timely intervention is crucial for the growth of young children with ASD, but traditional clinical screening methods lack objectivity. This study introduces an innovative approach to early detection of ASD. The contributions are threefold. First, this work proposes a novel Parent-Child Dyads Block-Play (PCB) protocol, grounded in kinesiological and neuroscientific research, to identify behavioral patterns distinguishing ASD from typically developing (TD) toddlers. Second, we have compiled a substantial video dataset, featuring 40 ASD and 89 TD toddlers engaged in block play with parents. This dataset exceeds previous efforts on both the scale of participants and the length of individual sessions. Third, our approach to action analysis in videos employs a hybrid deep learning framework, integrating a two-stream graph convolution network with attention-enhanced xLSTM (2sGCN-AxLSTM). This framework is adept at capturing dynamic interactions between toddlers and parents by extracting spatial features correlated with upper body and head movements and focusing on global contextual information of action sequences over time. By learning these global features with spatio-temporal correlations, our 2sGCN-AxLSTM effectively analyzes dynamic human behavior patterns and demonstrates an unprecedented accuracy of 89.6\% in early detection of ASD. Our approach shows strong potential for enhancing early ASD diagnosis by accurately analyzing parent-child interactions, providing a critical tool to support timely and informed clinical decision-making.
Characterizing Online Toxicity During the 2022 Mpox Outbreak: A Computational Analysis of Topical and Network Dynamics
Aug 21, 2024



Background: Online toxicity, encompassing behaviors such as harassment, bullying, hate speech, and the dissemination of misinformation, has become a pressing social concern in the digital age. The 2022 Mpox outbreak, initially termed "Monkeypox" but subsequently renamed to mitigate associated stigmas and societal concerns, serves as a poignant backdrop to this issue. Objective: In this research, we undertake a comprehensive analysis of the toxic online discourse surrounding the 2022 Mpox outbreak. Our objective is to dissect its origins, characterize its nature and content, trace its dissemination patterns, and assess its broader societal implications, with the goal of providing insights that can inform strategies to mitigate such toxicity in future crises. Methods: We collected more than 1.6 million unique tweets and analyzed them from five dimensions, including context, extent, content, speaker, and intent. Utilizing BERT-based topic modeling and social network community clustering, we delineated the toxic dynamics on Twitter. Results: We identified five high-level topic categories in the toxic online discourse on Twitter, including disease (46.6%), health policy and healthcare (19.3%), homophobia (23.9%), politics (6.0%), and racism (4.1%). Through the toxicity diffusion networks of mentions, retweets, and the top users, we found that retweets of toxic content were widespread, while influential users rarely engaged with or countered this toxicity through retweets. Conclusions: By tracking topical dynamics, we can track the changing popularity of toxic content online, providing a better understanding of societal challenges. Network dynamics spotlight key social media influencers and their intents, indicating that addressing these central figures in toxic discourse can enhance crisis communication and inform policy-making.
Disentangling Logic: The Role of Context in Large Language Model Reasoning Capabilities
Jun 04, 2024This study intends to systematically disentangle pure logic reasoning and text understanding by investigating the contrast across abstract and contextualized logical problems from a comprehensive set of domains. We explore whether LLMs demonstrate genuine reasoning capabilities across various domains when the underlying logical structure remains constant. We focus on two main questions (1) Can abstract logical problems alone accurately benchmark an LLM's reasoning ability in real-world scenarios, disentangled from contextual support in practical settings? (2) Does fine-tuning LLMs on abstract logic problem generalize to contextualized logic problems and vice versa? To investigate these questions, we focus on standard propositional logic, specifically propositional deductive and abductive logic reasoning. In particular, we construct instantiated datasets for deductive and abductive reasoning with 4 levels of difficulty, encompassing 12 distinct categories or domains based on the categorization of Wikipedia. Our experiments aim to provide insights into disentangling context in logical reasoning and the true reasoning capabilities of LLMs and their generalization potential. The code and dataset are available at: https://github.com/agiresearch/ContextHub.
BattleAgent: Multi-modal Dynamic Emulation on Historical Battles to Complement Historical Analysis
Apr 23, 2024



This paper presents BattleAgent, an emulation system that combines the Large Vision-Language Model and Multi-agent System. This novel system aims to simulate complex dynamic interactions among multiple agents, as well as between agents and their environments, over a period of time. It emulates both the decision-making processes of leaders and the viewpoints of ordinary participants, such as soldiers. The emulation showcases the current capabilities of agents, featuring fine-grained multi-modal interactions between agents and landscapes. It develops customizable agent structures to meet specific situational requirements, for example, a variety of battle-related activities like scouting and trench digging. These components collaborate to recreate historical events in a lively and comprehensive manner while offering insights into the thoughts and feelings of individuals from diverse viewpoints. The technological foundations of BattleAgent establish detailed and immersive settings for historical battles, enabling individual agents to partake in, observe, and dynamically respond to evolving battle scenarios. This methodology holds the potential to substantially deepen our understanding of historical events, particularly through individual accounts. Such initiatives can also aid historical research, as conventional historical narratives often lack documentation and prioritize the perspectives of decision-makers, thereby overlooking the experiences of ordinary individuals. BattelAgent illustrates AI's potential to revitalize the human aspect in crucial social events, thereby fostering a more nuanced collective understanding and driving the progressive development of human society.
Large Language Models in Biomedical and Health Informatics: A Bibliometric Review
Mar 26, 2024Large Language Models (LLMs) have rapidly become important tools in Biomedical and Health Informatics (BHI), enabling new ways to analyze data, treat patients, and conduct research. This bibliometric review aims to provide a panoramic view of how LLMs have been used in BHI by examining research articles and collaboration networks from 2022 to 2023. It further explores how LLMs can improve Natural Language Processing (NLP) applications in various BHI areas like medical diagnosis, patient engagement, electronic health record management, and personalized medicine. To do this, our bibliometric review identifies key trends, maps out research networks, and highlights major developments in this fast-moving field. Lastly, it discusses the ethical concerns and practical challenges of using LLMs in BHI, such as data privacy and reliable medical recommendations. Looking ahead, we consider how LLMs could further transform biomedical research as well as healthcare delivery and patient outcomes. This bibliometric review serves as a resource for stakeholders in healthcare, including researchers, clinicians, and policymakers, to understand the current state and future potential of LLMs in BHI.
NPHardEval4V: A Dynamic Reasoning Benchmark of Multimodal Large Language Models
Mar 05, 2024



Understanding the reasoning capabilities of Multimodal Large Language Models (MLLMs) is an important area of research. In this study, we introduce a dynamic benchmark, NPHardEval4V, aimed at addressing the existing gaps in evaluating the pure reasoning abilities of MLLMs. Our benchmark aims to provide a venue to disentangle the effect of various factors such as image recognition and instruction following, from the overall performance of the models, allowing us to focus solely on evaluating their reasoning abilities. It is built by converting textual description of questions from NPHardEval to image representations. Our findings reveal significant discrepancies in reasoning abilities across different models and highlight the relatively weak performance of MLLMs compared to LLMs in terms of reasoning. We also investigate the impact of different prompting styles, including visual, text, and combined visual and text prompts, on the reasoning abilities of MLLMs, demonstrating the different impacts of multimodal inputs in model performance. Unlike traditional benchmarks, which focus primarily on static evaluations, our benchmark will be updated monthly to prevent overfitting and ensure a more authentic and fine-grained evaluation of the models. We believe that this benchmark can aid in understanding and guide the further development of reasoning abilities in MLLMs. The benchmark dataset and code are available at https://github.com/lizhouf/NPHardEval4V
NPHardEval: Dynamic Benchmark on Reasoning Ability of Large Language Models via Complexity Classes
Jan 12, 2024



Complex reasoning ability is one of the most important features of current LLMs, which has also been leveraged to play an integral role in complex decision-making tasks. Therefore, the investigation into the reasoning capabilities of Large Language Models (LLMs) is critical: numerous benchmarks have been established to assess the reasoning abilities of LLMs. However, current benchmarks are inadequate in offering a rigorous evaluation of the full extent of reasoning abilities that LLMs are capable of achieving. They are also prone to the risk of overfitting, as these benchmarks, being publicly accessible and static, allow models to potentially tailor their responses to specific benchmark metrics, thereby inflating their performance. Addressing these limitations, our research introduces a new benchmark, named NPHardEval. This benchmark is designed to evaluate the reasoning abilities of LLMs across a broad spectrum of 900 algorithmic questions, extending up to the NP-Hard complexity class. These questions are meticulously chosen to represent a wide range of complexity class below the NP-hard complexity class, offering a rigorous measure of the reasoning ability of LLMs. Through this study, we shed light on the current state of reasoning in LLMs, providing an objective and rigorous perspective through the comparison of LLMs' performance across complex classes. Moreover, this benchmark is designed with a dynamic update mechanism, where the datapoints are refreshed on a monthly basis. Such regular updates play a crucial role in mitigating the risk of LLMs overfitting to the benchmark, promoting a more accurate and reliable assessment of their reasoning capabilities. The benchmark dataset and code of NPHardEval are available at https://github.com/casmlab/NPHardEval.