 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Autism Spectrum Disorder Early Detection with the Parent-Child Dyads Block-Play Protocol and an Attention-enhanced GCN-xLSTM Hybrid Deep Learning Framework
Aug 29, 2024
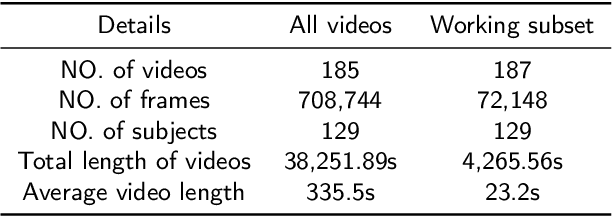

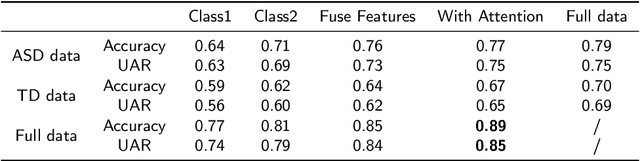
Autism Spectrum Disorder (ASD) is a rapidly growing neurodevelopmental disorder. Performing a timely intervention is crucial for the growth of young children with ASD, but traditional clinical screening methods lack objectivity. This study introduces an innovative approach to early detection of ASD. The contributions are threefold. First, this work proposes a novel Parent-Child Dyads Block-Play (PCB) protocol, grounded in kinesiological and neuroscientific research, to identify behavioral patterns distinguishing ASD from typically developing (TD) toddlers. Second, we have compiled a substantial video dataset, featuring 40 ASD and 89 TD toddlers engaged in block play with parents. This dataset exceeds previous efforts on both the scale of participants and the length of individual sessions. Third, our approach to action analysis in videos employs a hybrid deep learning framework, integrating a two-stream graph convolution network with attention-enhanced xLSTM (2sGCN-AxLSTM). This framework is adept at capturing dynamic interactions between toddlers and parents by extracting spatial features correlated with upper body and head movements and focusing on global contextual information of action sequences over time. By learning these global features with spatio-temporal correlations, our 2sGCN-AxLSTM effectively analyzes dynamic human behavior patterns and demonstrates an unprecedented accuracy of 89.6\% in early detection of ASD. Our approach shows strong potential for enhancing early ASD diagnosis by accurately analyzing parent-child interactions, providing a critical tool to support timely and informed clinical decision-making.
Inter-object Discriminative Graph Modeling for Indoor Scene Recognition
Nov 13, 2023Variable scene layouts and coexisting objects across scenes make indoor scene recognition still a challenging task. Leveraging object information within scenes to enhance the distinguishability of feature representations has emerged as a key approach in this domain. Currently, most object-assisted methods use a separate branch to process object information, combining object and scene features heuristically. However, few of them pay attention to interpretably handle the hidden discriminative knowledge within object information. In this paper, we propose to leverage discriminative object knowledge to enhance scene feature representations. Initially, we capture the object-scene discriminative relationships from a probabilistic perspective, which are transformed into an Inter-Object Discriminative Prototype (IODP). Given the abundant prior knowledge from IODP, we subsequently construct a Discriminative Graph Network (DGN), in which pixel-level scene features are defined as nodes and the discriminative relationships between node features are encoded as edges. DGN aims to incorporate inter-object discriminative knowledge into the image representation through graph convolution. With the proposed IODP and DGN, we obtain state-of-the-art results on several widely used scene datasets, demonstrating the effectiveness of the proposed approach.
Semantic-embedded Similarity Prototype for Scene Recognition
Aug 11, 2023Due to the high inter-class similarity caused by the complex composition within scenes and the co-existing objects across scenes, various studies have explored object semantic knowledge within scenes to improve scene recognition. However, a resulting issue arises as semantic segmentation or object detection techniques demand heavy computational power, thereby burdening the network considerably. This limitation often renders object-assisted approaches incompatible with edge devices. In contrast, this paper proposes a semantic-based similarity prototype that assists the scene recognition network to achieve higher accuracy without increasing network parameters. It is simple and can be plug-and-played into existing pipelines. More specifically, a statistical strategy is introduced to depict semantic knowledge in scenes as class-level semantic representations. These representations are utilized to explore inter-class correlations, ultimately constructing a similarity prototype. Furthermore, we propose two ways to use the similarity prototype to support network training from the perspective of gradient label softening and batch-level contrastive loss, respectively. Comprehensive evaluations on multiple benchmarks show that our similarity prototype enhances the performance of existing networks without adding any computational burden. Code and the statistical similarity prototype will be available soon.
Semantic-guided context modeling for indoor scene recognition
May 22, 2023Exploring the semantic context in scene images is essential for indoor scene recognition. However, due to the diverse intra-class spatial layouts and the coexisting inter-class objects, modeling contextual relationships to adapt various image characteristics is a great challenge. Existing contextual modeling methods for indoor scene recognition exhibit two limitations: 1) During training, space-independent information, such as color, may hinder optimizing the network's capacity to represent the spatial context. 2) These methods often overlook the differences in coexisting objects across different scenes, suppressing the performance of scene recognition. To address these limitations, we propose SpaCoNet, a novel approach that simultaneously models the Spatial relation and Co-occurrence of objects based on semantic segmentation. Firstly, the semantic spatial relation module (SSRM) is designed to explore the spatial relations among objects within a scene. With the help of semantic segmentation, this module decouples the spatial information from the image, effectively avoiding the influence of irrelevant features. Secondly, both spatial context features from SSRM and deep features from RGB feature extractor are used to distinguish the coexisting object across different scenes. Finally, utilizing the discriminative features mentioned above, we employ the self-attention mechanism to explore the long-range co-occurrence relationships among objects, and further generate a semantic-guided feature representation for indoor scene recognition. Experimental results on three publicly available datasets demonstrate the effectiveness and generality of the proposed method. The code will be made publicly available after the blind-review process is completed.