 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Facial Expressions Analysis Based Parkinson's Disease Auxiliary Diagnosis
Dec 10, 2025Parkinson's disease (PD), a prevalent neurodegenerative disorder, significantly affects patients' daily functioning and social interactions. To facilitate a more efficient and accessible diagnostic approach for PD, we propose a dynamic facial expression analysis-based PD auxiliary diagnosis method. This method targets hypomimia, a characteristic clinical symptom of PD, by analyzing two manifestations: reduced facial expressivity and facial rigidity, thereby facilitating the diagnosis process. We develop a multimodal facial expression analysis network to extract expression intensity features during patients' performance of various facial expressions. This network leverages the CLIP architecture to integrate visual and textual features while preserving the temporal dynamics of facial expressions. Subsequently, the expression intensity features are processed and input into an LSTM-based classification network for PD diagnosis. Our method achieves an accuracy of 93.1%, outperforming other in-vitro PD diagnostic approaches. This technique offers a more convenient detection method for potential PD patients, improving their diagnostic experience.
ROLO-SLAM: Rotation-Optimized LiDAR-Only SLAM in Uneven Terrain with Ground Vehicle
Jan 04, 2025LiDAR-based SLAM is recognized as one effective method to offer localization guidance in rough environments. However, off-the-shelf LiDAR-based SLAM methods suffer from significant pose estimation drifts, particularly components relevant to the vertical direction, when passing to uneven terrains. This deficiency typically leads to a conspicuously distorted global map. In this article, a LiDAR-based SLAM method is presented to improve the accuracy of pose estimations for ground vehicles in rough terrains, which is termed Rotation-Optimized LiDAR-Only (ROLO) SLAM. The method exploits a forward location prediction to coarsely eliminate the location difference of consecutive scans, thereby enabling separate and accurate determination of the location and orientation at the front-end. Furthermore, we adopt a parallel-capable spatial voxelization for correspondence-matching. We develop a spherical alignment-guided rotation registration within each voxel to estimate the rotation of vehicle. By incorporating geometric alignment, we introduce the motion constraint into the optimization formulation to enhance the rapid and effective estimation of LiDAR's translation. Subsequently, we extract several keyframes to construct the submap and exploit an alignment from the current scan to the submap for precise pose estimation. Meanwhile, a global-scale factor graph is established to aid in the reduction of cumulative errors. In various scenes, diverse experiments have been conducted to evaluate our method. The results demonstrate that ROLO-SLAM excels in pose estimation of ground vehicles and outperforms existing state-of-the-art LiDAR SLAM frameworks.
Learning Instruction-Guided Manipulation Affordance via Large Models for Embodied Robotic Tasks
Aug 20, 2024



We study the task of language instruction-guided robotic manipulation, in which an embodied robot is supposed to manipulate the target objects based on the language instructions. In previous studies, the predicted manipulation regions of the target object typically do not change with specification from the language instructions, which means that the language perception and manipulation prediction are separate. However, in human behavioral patterns, the manipulation regions of the same object will change for different language instructions. In this paper, we propose Instruction-Guided Affordance Net (IGANet) for predicting affordance maps of instruction-guided robotic manipulation tasks by utilizing powerful priors from vision and language encoders pre-trained on large-scale datasets. We develop a Vison-Language-Models(VLMs)-based data augmentation pipeline, which can generate a large amount of data automatically for model training. Besides, with the help of Large-Language-Models(LLMs), actions can be effectively executed to finish the tasks defined by instructions. A series of real-world experiments revealed that our method can achieve better performance with generated data. Moreover, our model can generalize better to scenarios with unseen objects and language instructions.
Integrating Controllable Motion Skills from Demonstrations
Aug 06, 2024



The expanding applications of legged robots require their mastery of versatile motion skills. Correspondingly, researchers must address the challenge of integrating multiple diverse motion skills into controllers. While existing reinforcement learning (RL)-based approaches have achieved notable success in multi-skill integration for legged robots, these methods often require intricate reward engineering or are restricted to integrating a predefined set of motion skills constrained by specific task objectives, resulting in limited flexibility. In this work, we introduce a flexible multi-skill integration framework named Controllable Skills Integration (CSI). CSI enables the integration of a diverse set of motion skills with varying styles into a single policy without the need for complex reward tuning. Furthermore, in a hierarchical control manner, the trained low-level policy can be coupled with a high-level Natural Language Inference (NLI) module to enable preliminary language-directed skill control. Our experiments demonstrate that CSI can flexibly integrate a diverse array of motion skills more comprehensively and facilitate the transitions between different skills. Additionally, CSI exhibits good scalability as the number of motion skills to be integrated increases significantly.
Nowhere to Go: Benchmarking Multi-robot Collaboration in Target Trapping Environment
Aug 17, 2023Collaboration is one of the most important factors in multi-robot systems. Considering certain real-world applications and to further promote its development, we propose a new benchmark to evaluate multi-robot collaboration in Target Trapping Environment (T2E). In T2E, two kinds of robots (called captor robot and target robot) share the same space. The captors aim to catch the target collaboratively, while the target will try to escape from the trap. Both the trapping and escaping process can use the environment layout to help achieve the corresponding objective, which requires high collaboration between robots and the utilization of the environment. For the benchmark, we present and evaluate multiple learning-based baselines in T2E, and provide insights into regimes of multi-robot collaboration. We also make our benchmark publicly available and encourage researchers from related robotics disciplines to propose, evaluate, and compare their solutions in this benchmark. Our project is released at https://github.com/Dr-Xiaogaren/T2E.
Semantic-guided context modeling for indoor scene recognition
May 22, 2023Exploring the semantic context in scene images is essential for indoor scene recognition. However, due to the diverse intra-class spatial layouts and the coexisting inter-class objects, modeling contextual relationships to adapt various image characteristics is a great challenge. Existing contextual modeling methods for indoor scene recognition exhibit two limitations: 1) During training, space-independent information, such as color, may hinder optimizing the network's capacity to represent the spatial context. 2) These methods often overlook the differences in coexisting objects across different scenes, suppressing the performance of scene recognition. To address these limitations, we propose SpaCoNet, a novel approach that simultaneously models the Spatial relation and Co-occurrence of objects based on semantic segmentation. Firstly, the semantic spatial relation module (SSRM) is designed to explore the spatial relations among objects within a scene. With the help of semantic segmentation, this module decouples the spatial information from the image, effectively avoiding the influence of irrelevant features. Secondly, both spatial context features from SSRM and deep features from RGB feature extractor are used to distinguish the coexisting object across different scenes. Finally, utilizing the discriminative features mentioned above, we employ the self-attention mechanism to explore the long-range co-occurrence relationships among objects, and further generate a semantic-guided feature representation for indoor scene recognition. Experimental results on three publicly available datasets demonstrate the effectiveness and generality of the proposed method. The code will be made publicly available after the blind-review process is completed.
Circular Accessible Depth: A Robust Traversability Representation for UGV Navigation
Dec 28, 2022In this paper, we present the Circular Accessible Depth (CAD), a robust traversability representation for an unmanned ground vehicle (UGV) to learn traversability in various scenarios containing irregular obstacles. To predict CAD, we propose a neural network, namely CADNet, with an attention-based multi-frame point cloud fusion module, Stability-Attention Module (SAM), to encode the spatial features from point clouds captured by LiDAR. CAD is designed based on the polar coordinate system and focuses on predicting the border of traversable area. Since it encodes the spatial information of the surrounding environment, which enables a semi-supervised learning for the CADNet, and thus desirably avoids annotating a large amount of data. Extensive experiments demonstrate that CAD outperforms baselines in terms of robustness and precision. We also implement our method on a real UGV and show that it performs well in real-world scenarios.
Learn by Observation: Imitation Learning for Drone Patrolling from Videos of A Human Navigator
Aug 30, 2020
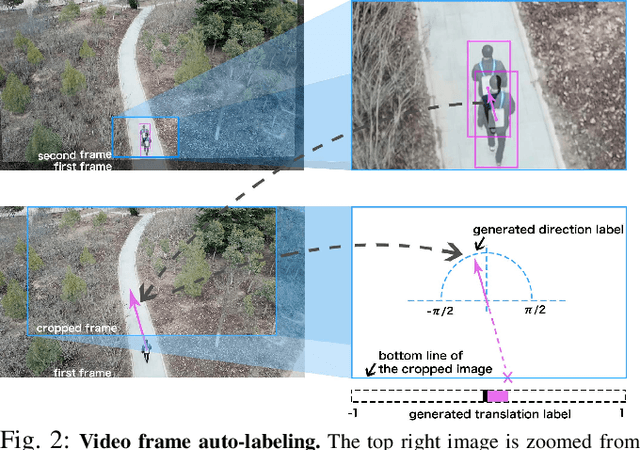
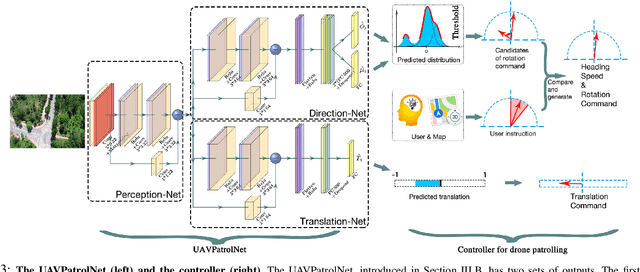
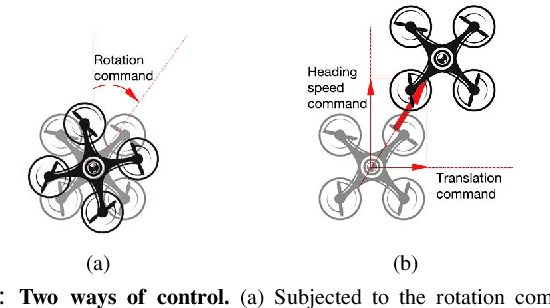
We present an imitation learning method for autonomous drone patrolling based only on raw videos. Different from previous methods, we propose to let the drone learn patrolling in the air by observing and imitating how a human navigator does it on the ground. The observation process enables the automatic collection and annotation of data using inter-frame geometric consistency, resulting in less manual effort and high accuracy. Then a newly designed neural network is trained based on the annotated data to predict appropriate directions and translations for the drone to patrol in a lane-keeping manner as humans. Our method allows the drone to fly at a high altitude with a broad view and low risk. It can also detect all accessible directions at crossroads and further carry out the integration of available user instructions and autonomous patrolling control commands. Extensive experiments are conducted to demonstrate the accuracy of the proposed imitating learning process as well as the reliability of the holistic system for autonomous drone navigation. The codes, datasets as well as video demonstrations are available at https://vsislab.github.io/uavpatrol
Learning Actions from Human Demonstration Video for Robotic Manipulation
Sep 10, 2019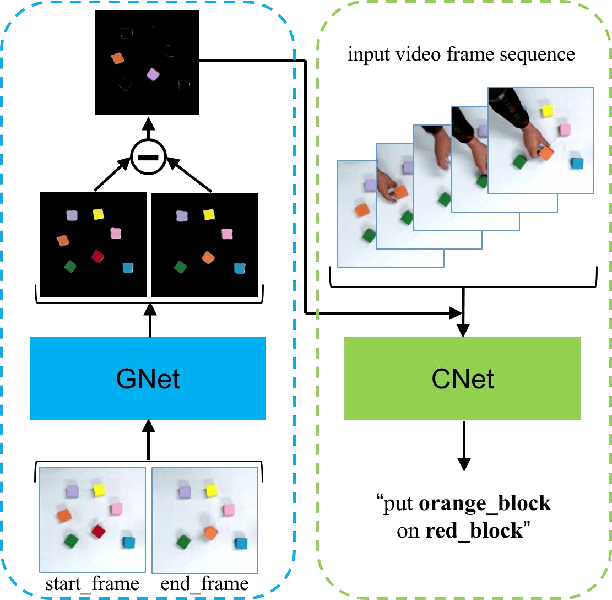
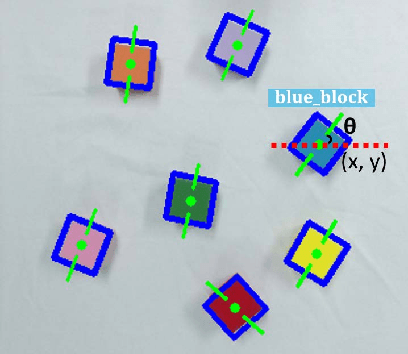
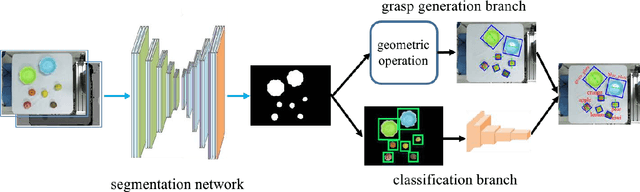
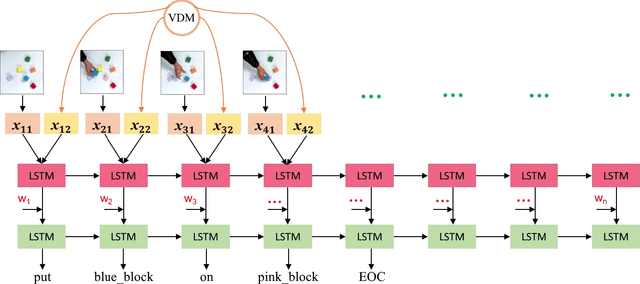
Learning actions from human demonstration is an emerging trend for designing intelligent robotic systems, which can be referred as video to command. The performance of such approach highly relies on the quality of video captioning. However, the general video captioning methods focus more on the understanding of the full frame, lacking of consideration on the specific object of interests in robotic manipulations. We propose a novel deep model to learn actions from human demonstration video for robotic manipulation. It consists of two deep networks, grasp detection network (GNet) and video captioning network (CNet). GNet performs two functions: providing grasp solutions and extracting the local features for the object of interests in robotic manipulation. CNet outputs the captioning results by fusing the features of both full frames and local objects. Experimental results on UR5 robotic arm show that our method could produce more accurate command from video demonstration than state-of-the-art work, thereby leading to more robust grasping performance.