 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Instruction-Guided Manipulation Affordance via Large Models for Embodied Robotic Tasks
Aug 20, 2024



We study the task of language instruction-guided robotic manipulation, in which an embodied robot is supposed to manipulate the target objects based on the language instructions. In previous studies, the predicted manipulation regions of the target object typically do not change with specification from the language instructions, which means that the language perception and manipulation prediction are separate. However, in human behavioral patterns, the manipulation regions of the same object will change for different language instructions. In this paper, we propose Instruction-Guided Affordance Net (IGANet) for predicting affordance maps of instruction-guided robotic manipulation tasks by utilizing powerful priors from vision and language encoders pre-trained on large-scale datasets. We develop a Vison-Language-Models(VLMs)-based data augmentation pipeline, which can generate a large amount of data automatically for model training. Besides, with the help of Large-Language-Models(LLMs), actions can be effectively executed to finish the tasks defined by instructions. A series of real-world experiments revealed that our method can achieve better performance with generated data. Moreover, our model can generalize better to scenarios with unseen objects and language instructions.
MPGNet: Learning Move-Push-Grasping Synergy for Target-Oriented Grasping in Occluded Scenes
Aug 20, 2024
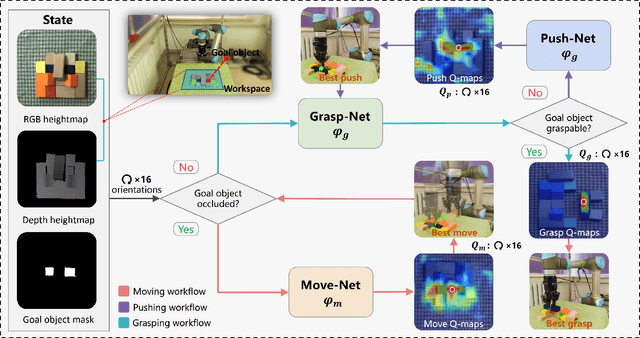
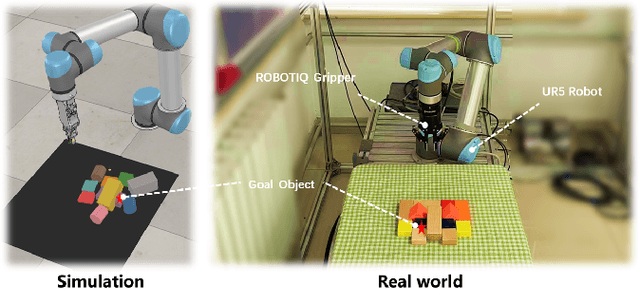
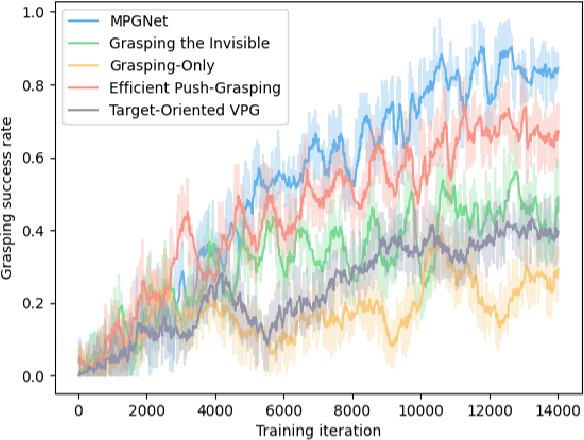
This paper focuses on target-oriented grasping in occluded scenes, where the target object is specified by a binary mask and the goal is to grasp the target object with as few robotic manipulations as possible. Most existing methods rely on a push-grasping synergy to complete this task. To deliver a more powerful target-oriented grasping pipeline, we present MPGNet, a three-branch network for learning a synergy between moving, pushing, and grasping actions. We also propose a multi-stage training strategy to train the MPGNet which contains three policy networks corresponding to the three actions. The effectiveness of our method is demonstrated via both simulated and real-world experiments.
Where to Fetch: Extracting Visual Scene Representation from Large Pre-Trained Models for Robotic Goal Navigation
Aug 20, 2024To complete a complex task where a robot navigates to a goal object and fetches it, the robot needs to have a good understanding of the instructions and the surrounding environment. Large pre-trained models have shown capabilities to interpret tasks defined via language descriptions. However, previous methods attempting to integrate large pre-trained models with daily tasks are not competent in many robotic goal navigation tasks due to poor understanding of the environment. In this work, we present a visual scene representation built with large-scale visual language models to form a feature representation of the environment capable of handling natural language queries. Combined with large language models, this method can parse language instructions into action sequences for a robot to follow, and accomplish goal navigation with querying the scene representation. Experiments demonstrate that our method enables the robot to follow a wide range of instructions and complete complex goal navigation tasks.