 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMRFT: Fusion Mamba and DETR for Query Time Sequence Intersection Fish Tracking
Sep 02, 2024Growth, abnormal behavior, and diseases of fish can be early detected by monitoring fish tracking through the method of image processing, which is of great significance for factory aquaculture. However, underwater reflections and some reasons with fish, such as the high similarity , rapid swimming caused by stimuli and multi-object occlusion bring challenges to multi-target tracking of fish. To address these challenges, this paper establishes a complex multi-scene sturgeon tracking dataset and proposes a real-time end-to-end fish tracking model, FMRFT. In this model, the Mamba In Mamba (MIM) architecture with low memory consumption is introduced into the tracking algorithm to realize multi-frame video timing memory and fast feature extraction, which improves the efficiency of correlation analysis for contiguous frames in multi-fish video. Additionally, the superior feature interaction and a priori frame processing capabilities of RT-DETR are leveraged to provide an effective tracking algorithm. By incorporating the QTSI query interaction processing module, the model effectively handles occluded objects and redundant tracking frames, resulting in more accurate and stable fish tracking. Trained and tested on the dataset, the model achieves an IDF1 score of 90.3% and a MOTA accuracy of 94.3%. Experimental results demonstrate that the proposed FMRFT model effectively addresses the challenges of high similarity and mutual occlusion in fish populations, enabling accurate tracking in factory farming environments.
FA-YOLO: Research On Efficient Feature Selection YOLO Improved Algorithm Based On FMDS and AGMF Modules
Aug 29, 2024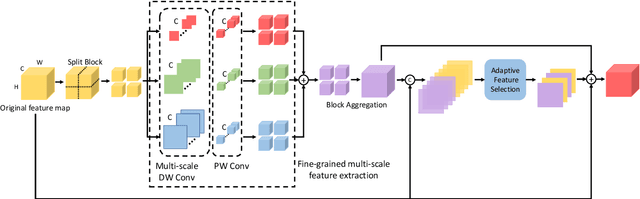
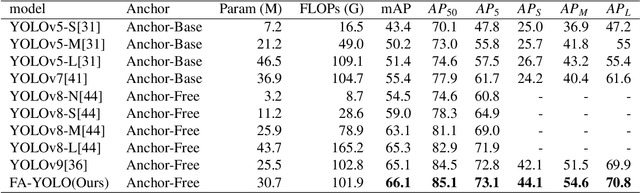
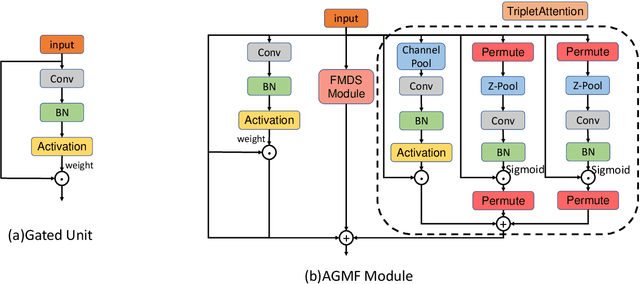
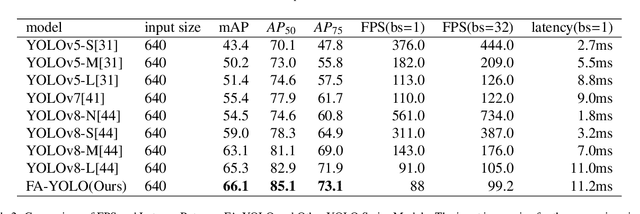
Over the past few years, the YOLO series of models has emerged as one of the dominant methodologies in the realm of object detection. Many studies have advanced these baseline models by modifying their architectures, enhancing data quality, and developing new loss functions. However, current models still exhibit deficiencies in processing feature maps, such as overlooking the fusion of cross-scale features and a static fusion approach that lacks the capability for dynamic feature adjustment. To address these issues, this paper introduces an efficient Fine-grained Multi-scale Dynamic Selection Module (FMDS Module), which applies a more effective dynamic feature selection and fusion method on fine-grained multi-scale feature maps, significantly enhancing the detection accuracy of small, medium, and large-sized targets in complex environments. Furthermore, this paper proposes an Adaptive Gated Multi-branch Focus Fusion Module (AGMF Module), which utilizes multiple parallel branches to perform complementary fusion of various features captured by the gated unit branch, FMDS Module branch, and TripletAttention branch. This approach further enhances the comprehensiveness, diversity, and integrity of feature fusion. This paper has integrated the FMDS Module, AGMF Module, into Yolov9 to develop a novel object detection model named FA-YOLO. Extensive experimental results show that under identical experimental conditions, FA-YOLO achieves an outstanding 66.1% mean Average Precision (mAP) on the PASCAL VOC 2007 dataset, representing 1.0% improvement over YOLOv9's 65.1%. Additionally, the detection accuracies of FA-YOLO for small, medium, and large targets are 44.1%, 54.6%, and 70.8%, respectively, showing improvements of 2.0%, 3.1%, and 0.9% compared to YOLOv9's 42.1%, 51.5%, and 69.9%.
Where to Fetch: Extracting Visual Scene Representation from Large Pre-Trained Models for Robotic Goal Navigation
Aug 20, 2024To complete a complex task where a robot navigates to a goal object and fetches it, the robot needs to have a good understanding of the instructions and the surrounding environment. Large pre-trained models have shown capabilities to interpret tasks defined via language descriptions. However, previous methods attempting to integrate large pre-trained models with daily tasks are not competent in many robotic goal navigation tasks due to poor understanding of the environment. In this work, we present a visual scene representation built with large-scale visual language models to form a feature representation of the environment capable of handling natural language queries. Combined with large language models, this method can parse language instructions into action sequences for a robot to follow, and accomplish goal navigation with querying the scene representation. Experiments demonstrate that our method enables the robot to follow a wide range of instructions and complete complex goal navigation tasks.
Self-supervised transformer-based pre-training method with General Plant Infection dataset
Jul 20, 2024



Pest and disease classification is a challenging issue in agriculture. The performance of deep learning models is intricately linked to training data diversity and quantity, posing issues for plant pest and disease datasets that remain underdeveloped. This study addresses these challenges by constructing a comprehensive dataset and proposing an advanced network architecture that combines Contrastive Learning and Masked Image Modeling (MIM). The dataset comprises diverse plant species and pest categories, making it one of the largest and most varied in the field. The proposed network architecture demonstrates effectiveness in addressing plant pest and disease recognition tasks, achieving notable detection accuracy. This approach offers a viable solution for rapid, efficient, and cost-effective plant pest and disease detection, thereby reducing agricultural production costs. Our code and dataset will be publicly available to advance research in plant pest and disease recognition the GitHub repository at https://github.com/WASSER2545/GPID-22
Exploring and Evaluating Hallucinations in LLM-Powered Code Generation
Apr 01, 2024



The rise of Large Language Models (LLMs) has significantly advanced many applications on software engineering tasks, particularly in code generation. Despite the promising performance, LLMs are prone to generate hallucinations, which means LLMs might produce outputs that deviate from users' intent, exhibit internal inconsistencies, or misalign with the factual knowledge, making the deployment of LLMs potentially risky in a wide range of applications. Existing work mainly focuses on investing the hallucination in the domain of natural language generation (NLG), leaving a gap in understanding the types and extent of hallucinations in the context of code generation. To bridge the gap, we conducted a thematic analysis of the LLM-generated code to summarize and categorize the hallucinations present in it. Our study established a comprehensive taxonomy of hallucinations in LLM-generated code, encompassing 5 primary categories of hallucinations depending on the conflicting objectives and varying degrees of deviation observed in code generation. Furthermore, we systematically analyzed the distribution of hallucinations, exploring variations among different LLMs and their correlation with code correctness. Based on the results, we proposed HalluCode, a benchmark for evaluating the performance of code LLMs in recognizing hallucinations. Hallucination recognition and mitigation experiments with HalluCode and HumanEval show existing LLMs face great challenges in recognizing hallucinations, particularly in identifying their types, and are hardly able to mitigate hallucinations. We believe our findings will shed light on future research about hallucination evaluation, detection, and mitigation, ultimately paving the way for building more effective and reliable code LLMs in the future.
Neural Radiance Field-based Visual Rendering: A Comprehensive Review
Mar 31, 2024



In recent years, Neural Radiance Fields (NeRF) has made remarkable progress in the field of computer vision and graphics, providing strong technical support for solving key tasks including 3D scene understanding, new perspective synthesis, human body reconstruction, robotics, and so on, the attention of academics to this research result is growing. As a revolutionary neural implicit field representation, NeRF has caused a continuous research boom in the academic community. Therefore, the purpose of this review is to provide an in-depth analysis of the research literature on NeRF within the past two years, to provide a comprehensive academic perspective for budding researchers. In this paper, the core architecture of NeRF is first elaborated in detail, followed by a discussion of various improvement strategies for NeRF, and case studies of NeRF in diverse application scenarios, demonstrating its practical utility in different domains. In terms of datasets and evaluation metrics, This paper details the key resources needed for NeRF model training. Finally, this paper provides a prospective discussion on the future development trends and potential challenges of NeRF, aiming to provide research inspiration for researchers in the field and to promote the further development of related technologies.
A Thermoplastic Elastomer Belt Based Robotic Gripper
Jun 24, 2020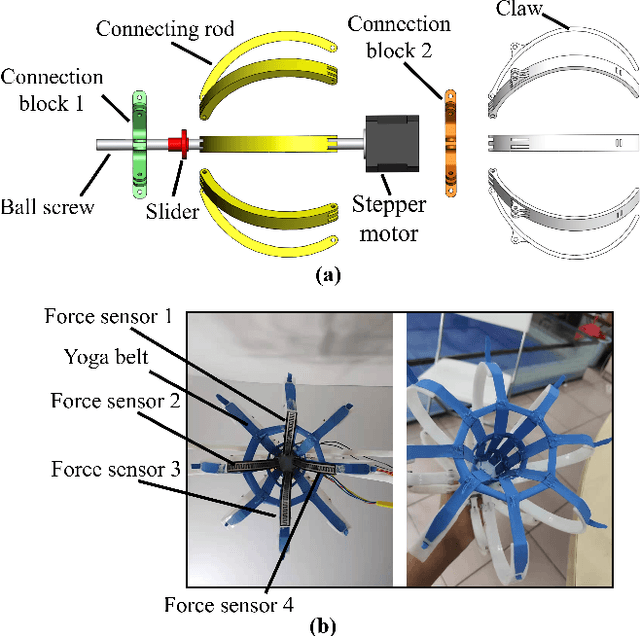
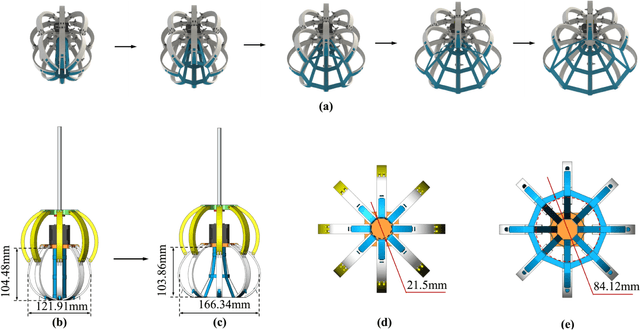
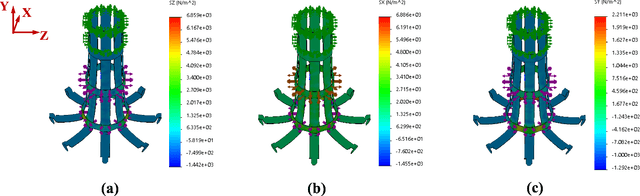
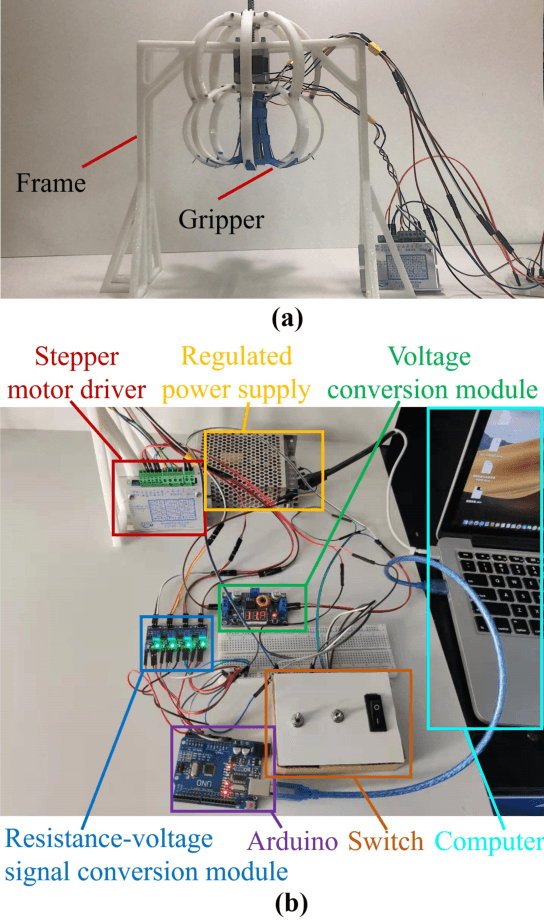
Novel robotic grippers have captured increasing interests recently because of their abilities to adapt to varieties of circumstances and their powerful functionalities. Differing from traditional gripper with mechanical components-made fingers, novel robotic grippers are typically made of novel structures and materials, using a novel manufacturing process. In this paper, a novel robotic gripper with external frame and internal thermoplastic elastomer belt-made net is proposed. The gripper grasps objects using the friction between the net and objects. It has the ability of adaptive gripping through flexible contact surface. Stress simulation has been used to explore the regularity between the normal stress on the net and the deformation of the net. Experiments are conducted on a variety of objects to measure the force needed to reliably grip and hold the object. Test results show that the gripper can successfully grip objects with varying shape, dimensions, and textures. It is promising that the gripper can be used for grasping fragile objects in the industry or out in the field, and also grasping the marine organisms without hurting them.