 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised transformer-based pre-training method with General Plant Infection dataset
Jul 20, 2024



Pest and disease classification is a challenging issue in agriculture. The performance of deep learning models is intricately linked to training data diversity and quantity, posing issues for plant pest and disease datasets that remain underdeveloped. This study addresses these challenges by constructing a comprehensive dataset and proposing an advanced network architecture that combines Contrastive Learning and Masked Image Modeling (MIM). The dataset comprises diverse plant species and pest categories, making it one of the largest and most varied in the field. The proposed network architecture demonstrates effectiveness in addressing plant pest and disease recognition tasks, achieving notable detection accuracy. This approach offers a viable solution for rapid, efficient, and cost-effective plant pest and disease detection, thereby reducing agricultural production costs. Our code and dataset will be publicly available to advance research in plant pest and disease recognition the GitHub repository at https://github.com/WASSER2545/GPID-22
Stable and Interpretable Deep Learning for Tabular Data: Introducing InterpreTabNet with the Novel InterpreStability Metric
Oct 04, 2023



As Artificial Intelligence (AI) integrates deeper into diverse sectors, the quest for powerful models has intensified. While significant strides have been made in boosting model capabilities and their applicability across domains, a glaring challenge persists: many of these state-of-the-art models remain as black boxes. This opacity not only complicates the explanation of model decisions to end-users but also obstructs insights into intermediate processes for model designers. To address these challenges, we introduce InterpreTabNet, a model designed to enhance both classification accuracy and interpretability by leveraging the TabNet architecture with an improved attentive module. This design ensures robust gradient propagation and computational stability. Additionally, we present a novel evaluation metric, InterpreStability, which quantifies the stability of a model's interpretability. The proposed model and metric mark a significant stride forward in explainable models' research, setting a standard for transparency and interpretability in AI model design and application across diverse sectors. InterpreTabNet surpasses other leading solutions in tabular data analysis across varied application scenarios, paving the way for further research into creating deep-learning models that are both highly accurate and inherently explainable. The introduction of the InterpreStability metric ensures that the interpretability of future models can be measured and compared in a consistent and rigorous manner. Collectively, these contributions have the potential to promote the design principles and development of next-generation interpretable AI models, widening the adoption of interpretable AI solutions in critical decision-making environments.
Transfer Learning from Synthetic In-vitro Soybean Pods Dataset for In-situ Segmentation of On-branch Soybean Pod
Apr 22, 2022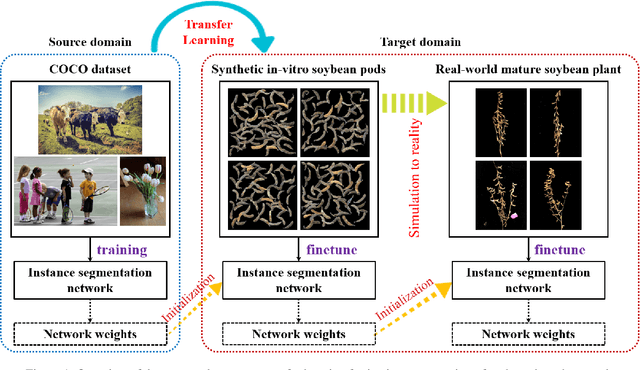

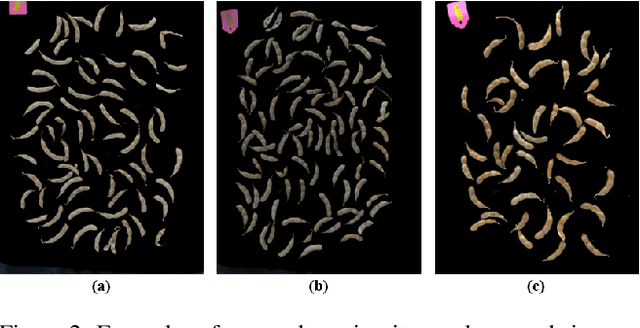

The mature soybean plants are of complex architecture with pods frequently touching each other, posing a challenge for in-situ segmentation of on-branch soybean pods. Deep learning-based methods can achieve accurate training and strong generalization capabilities, but it demands massive labeled data, which is often a limitation, especially for agricultural applications. As lacking the labeled data to train an in-situ segmentation model for on-branch soybean pods, we propose a transfer learning from synthetic in-vitro soybean pods. First, we present a novel automated image generation method to rapidly generate a synthetic in-vitro soybean pods dataset with plenty of annotated samples. The in-vitro soybean pods samples are overlapped to simulate the frequently physically touching of on-branch soybean pods. Then, we design a two-step transfer learning. In the first step, we finetune an instance segmentation network pretrained by a source domain (MS COCO dataset) with a synthetic target domain (in-vitro soybean pods dataset). In the second step, transferring from simulation to reality is performed by finetuning on a few real-world mature soybean plant samples. The experimental results show the effectiveness of the proposed two-step transfer learning method, such that AP$_{50}$ was 0.80 for the real-world mature soybean plant test dataset, which is higher than that of direct adaptation and its AP$_{50}$ was 0.77. Furthermore, the visualizations of in-situ segmentation results of on-branch soybean pods show that our method performs better than other methods, especially when soybean pods overlap densely.