 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRA-SSU: Towards Fine-Grained Audio-Visual Learning with Region-Aware Sound Source Understanding
Mar 10, 2026Audio-Visual Learning (AVL) is one fundamental task of multi-modality learning and embodied intelligence, displaying the vital role in scene understanding and interaction. However, previous researchers mostly focus on exploring downstream tasks from a coarse-grained perspective (e.g., audio-visual correspondence, sound source localization, and audio-visual event localization). Considering providing more specific scene perception details, we newly define a fine-grained Audio-Visual Learning task, termed Region-Aware Sound Source Understanding (RA-SSU), which aims to achieve region-aware, frame-level, and high-quality sound source understanding. To support this goal, we innovatively construct two corresponding datasets, i.e. fine-grained Music (f-Music) and fine-grained Lifescene (f-Lifescene), each containing annotated sound source masks and frame-by-frame textual descriptions. The f-Music dataset includes 3,976 samples across 22 scene types related to specific application scenarios, focusing on music scenes with complex instrument mixing. The f-Lifescene dataset contains 6,156 samples across 61 types representing diverse sounding objects in life scenarios. Moreover, we propose SSUFormer, a Sound-Source Understanding TransFormer benchmark that facilitates both the sound source segmentation and sound region description with a multi-modal input and multi-modal output architecture. Specifically, we design two modules for this framework, Mask Collaboration Module (MCM) and Mixture of Hierarchical-prompted Experts (MoHE), to respectively enhance the accuracy and enrich the elaboration of the sound source description. Extensive experiments are conducted on our two datasets to verify the feasibility of the task, evaluate the availability of the datasets, and demonstrate the superiority of the SSUFormer, which achieves SOTA performance on the Sound Source Understanding benchmark.
Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models
Jan 29, 2026Text-to-image (T2I) models have achieved remarkable success in generating high-fidelity images, but they often fail in handling complex spatial relationships, e.g., spatial perception, reasoning, or interaction. These critical aspects are largely overlooked by current benchmarks due to their short or information-sparse prompt design. In this paper, we introduce SpatialGenEval, a new benchmark designed to systematically evaluate the spatial intelligence of T2I models, covering two key aspects: (1) SpatialGenEval involves 1,230 long, information-dense prompts across 25 real-world scenes. Each prompt integrates 10 spatial sub-domains and corresponding 10 multi-choice question-answer pairs, ranging from object position and layout to occlusion and causality. Our extensive evaluation of 21 state-of-the-art models reveals that higher-order spatial reasoning remains a primary bottleneck. (2) To demonstrate that the utility of our information-dense design goes beyond simple evaluation, we also construct the SpatialT2I dataset. It contains 15,400 text-image pairs with rewritten prompts to ensure image consistency while preserving information density. Fine-tuned results on current foundation models (i.e., Stable Diffusion-XL, Uniworld-V1, OmniGen2) yield consistent performance gains (+4.2%, +5.7%, +4.4%) and more realistic effects in spatial relations, highlighting a data-centric paradigm to achieve spatial intelligence in T2I models.
Learning Geometric Invariance for Gait Recognition
Jan 09, 2026The goal of gait recognition is to extract identity-invariant features of an individual under various gait conditions, e.g., cross-view and cross-clothing. Most gait models strive to implicitly learn the common traits across different gait conditions in a data-driven manner to pull different gait conditions closer for recognition. However, relatively few studies have explicitly explored the inherent relations between different gait conditions. For this purpose, we attempt to establish connections among different gait conditions and propose a new perspective to achieve gait recognition: variations in different gait conditions can be approximately viewed as a combination of geometric transformations. In this case, all we need is to determine the types of geometric transformations and achieve geometric invariance, then identity invariance naturally follows. As an initial attempt, we explore three common geometric transformations (i.e., Reflect, Rotate, and Scale) and design a $\mathcal{R}$eflect-$\mathcal{R}$otate-$\mathcal{S}$cale invariance learning framework, named ${\mathcal{RRS}}$-Gait. Specifically, it first flexibly adjusts the convolution kernel based on the specific geometric transformations to achieve approximate feature equivariance. Then these three equivariant-aware features are respectively fed into a global pooling operation for final invariance-aware learning. Extensive experiments on four popular gait datasets (Gait3D, GREW, CCPG, SUSTech1K) show superior performance across various gait conditions.
DanceEditor: Towards Iterative Editable Music-driven Dance Generation with Open-Vocabulary Descriptions
Aug 24, 2025



Generating coherent and diverse human dances from music signals has gained tremendous progress in animating virtual avatars. While existing methods support direct dance synthesis, they fail to recognize that enabling users to edit dance movements is far more practical in real-world choreography scenarios. Moreover, the lack of high-quality dance datasets incorporating iterative editing also limits addressing this challenge. To achieve this goal, we first construct DanceRemix, a large-scale multi-turn editable dance dataset comprising the prompt featuring over 25.3M dance frames and 84.5K pairs. In addition, we propose a novel framework for iterative and editable dance generation coherently aligned with given music signals, namely DanceEditor. Considering the dance motion should be both musical rhythmic and enable iterative editing by user descriptions, our framework is built upon a prediction-then-editing paradigm unifying multi-modal conditions. At the initial prediction stage, our framework improves the authority of generated results by directly modeling dance movements from tailored, aligned music. Moreover, at the subsequent iterative editing stages, we incorporate text descriptions as conditioning information to draw the editable results through a specifically designed Cross-modality Editing Module (CEM). Specifically, CEM adaptively integrates the initial prediction with music and text prompts as temporal motion cues to guide the synthesized sequences. Thereby, the results display music harmonics while preserving fine-grained semantic alignment with text descriptions. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected DanceRemix dataset. Code is available at https://lzvsdy.github.io/DanceEditor/.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
ReMeREC: Relation-aware and Multi-entity Referring Expression Comprehension
Jul 22, 2025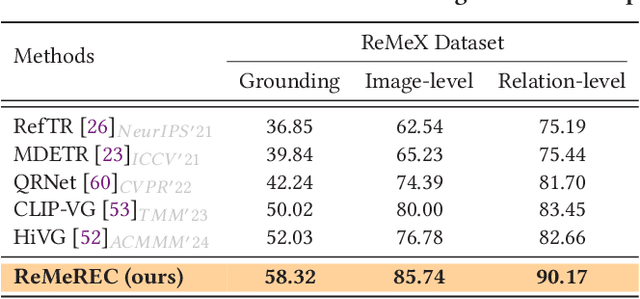

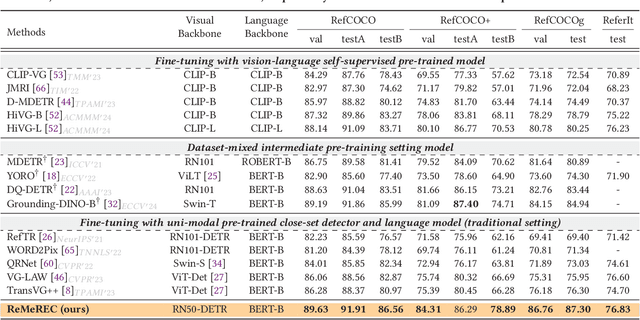
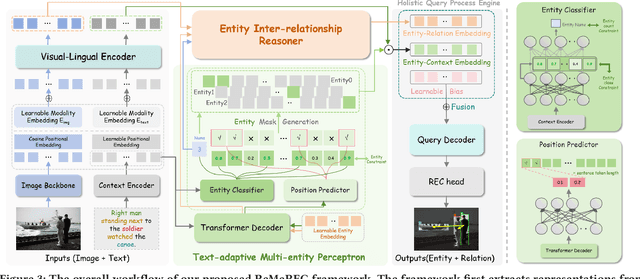
Referring Expression Comprehension (REC) aims to localize specified entities or regions in an image based on natural language descriptions. While existing methods handle single-entity localization, they often ignore complex inter-entity relationships in multi-entity scenes, limiting their accuracy and reliability. Additionally, the lack of high-quality datasets with fine-grained, paired image-text-relation annotations hinders further progress. To address this challenge, we first construct a relation-aware, multi-entity REC dataset called ReMeX, which includes detailed relationship and textual annotations. We then propose ReMeREC, a novel framework that jointly leverages visual and textual cues to localize multiple entities while modeling their inter-relations. To address the semantic ambiguity caused by implicit entity boundaries in language, we introduce the Text-adaptive Multi-entity Perceptron (TMP), which dynamically infers both the quantity and span of entities from fine-grained textual cues, producing distinctive representations. Additionally, our Entity Inter-relationship Reasoner (EIR) enhances relational reasoning and global scene understanding. To further improve language comprehension for fine-grained prompts, we also construct a small-scale auxiliary dataset, EntityText, generated using large language models. Experiments on four benchmark datasets show that ReMeREC achieves state-of-the-art performance in multi-entity grounding and relation prediction, outperforming existing approaches by a large margin.
VividListener: Expressive and Controllable Listener Dynamics Modeling for Multi-Modal Responsive Interaction
Apr 30, 2025



Generating responsive listener head dynamics with nuanced emotions and expressive reactions is crucial for practical dialogue modeling in various virtual avatar animations. Previous studies mainly focus on the direct short-term production of listener behavior. They overlook the fine-grained control over motion variations and emotional intensity, especially in long-sequence modeling. Moreover, the lack of long-term and large-scale paired speaker-listener corpora including head dynamics and fine-grained multi-modality annotations (e.g., text-based expression descriptions, emotional intensity) also limits the application of dialogue modeling.Therefore, we first newly collect a large-scale multi-turn dataset of 3D dyadic conversation containing more than 1.4M valid frames for multi-modal responsive interaction, dubbed ListenerX. Additionally, we propose VividListener, a novel framework enabling fine-grained, expressive and controllable listener dynamics modeling. This framework leverages multi-modal conditions as guiding principles for fostering coherent interactions between speakers and listeners.Specifically, we design the Responsive Interaction Module (RIM) to adaptively represent the multi-modal interactive embeddings. RIM ensures the listener dynamics achieve fine-grained semantic coordination with textual descriptions and adjustments, while preserving expressive reaction with speaker behavior. Meanwhile, we design the Emotional Intensity Tags (EIT) for emotion intensity editing with multi-modal information integration, applying to both text descriptions and listener motion amplitude.Extensive experiments conducted on our newly collected ListenerX dataset demonstrate that VividListener achieves state-of-the-art performance, realizing expressive and controllable listener dynamics.
Self-supervised transformer-based pre-training method with General Plant Infection dataset
Jul 20, 2024



Pest and disease classification is a challenging issue in agriculture. The performance of deep learning models is intricately linked to training data diversity and quantity, posing issues for plant pest and disease datasets that remain underdeveloped. This study addresses these challenges by constructing a comprehensive dataset and proposing an advanced network architecture that combines Contrastive Learning and Masked Image Modeling (MIM). The dataset comprises diverse plant species and pest categories, making it one of the largest and most varied in the field. The proposed network architecture demonstrates effectiveness in addressing plant pest and disease recognition tasks, achieving notable detection accuracy. This approach offers a viable solution for rapid, efficient, and cost-effective plant pest and disease detection, thereby reducing agricultural production costs. Our code and dataset will be publicly available to advance research in plant pest and disease recognition the GitHub repository at https://github.com/WASSER2545/GPID-22
StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
May 09, 2024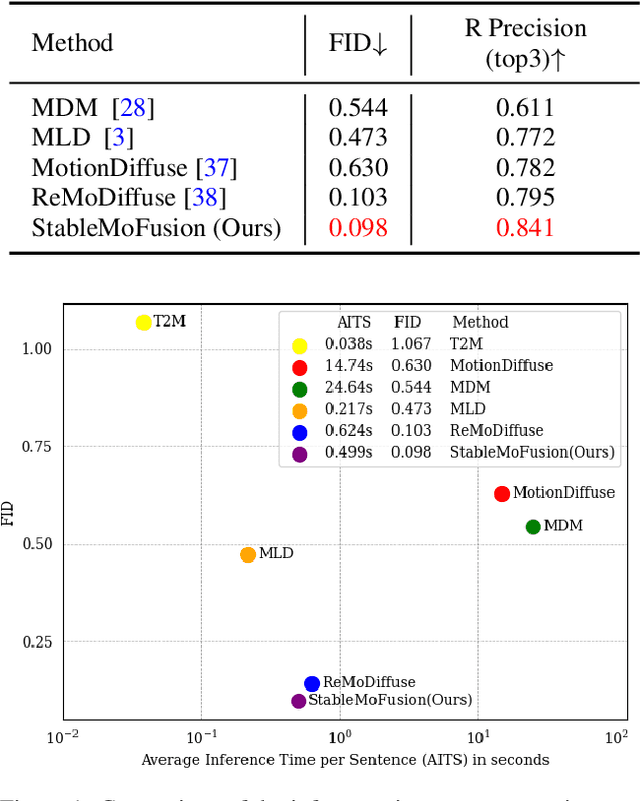
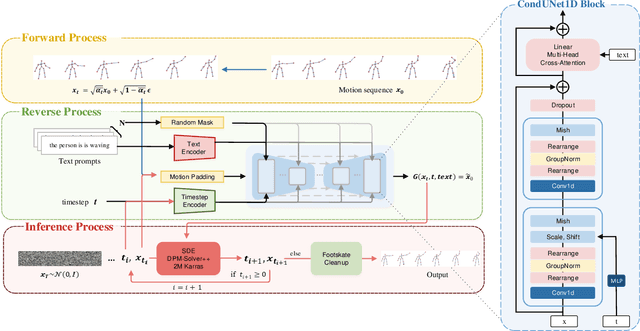
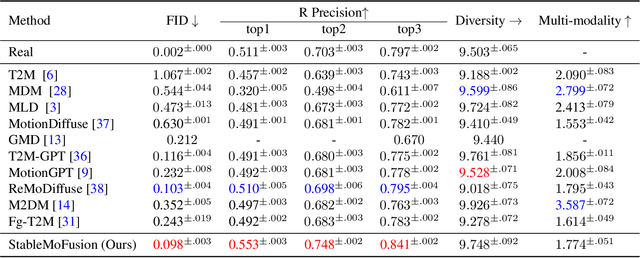
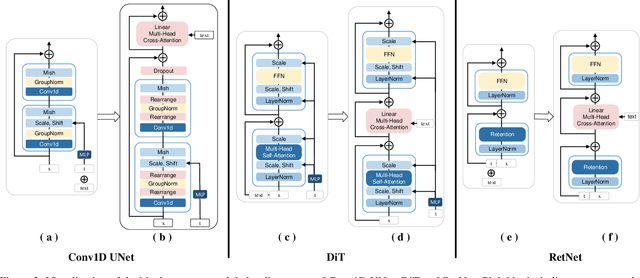
Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: https://h-y1heng.github.io/StableMoFusion-page/
QAGait: Revisit Gait Recognition from a Quality Perspective
Jan 24, 2024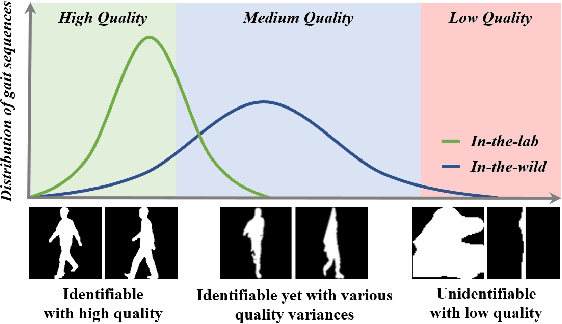
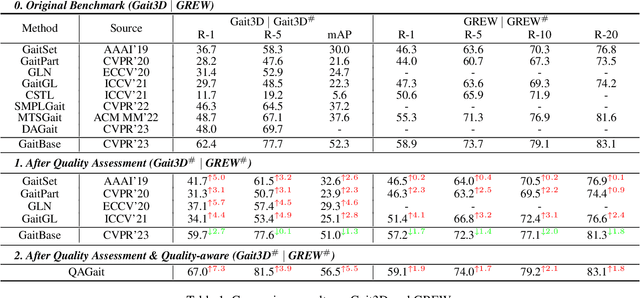
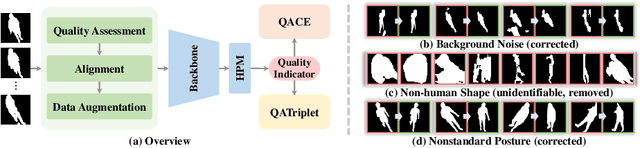
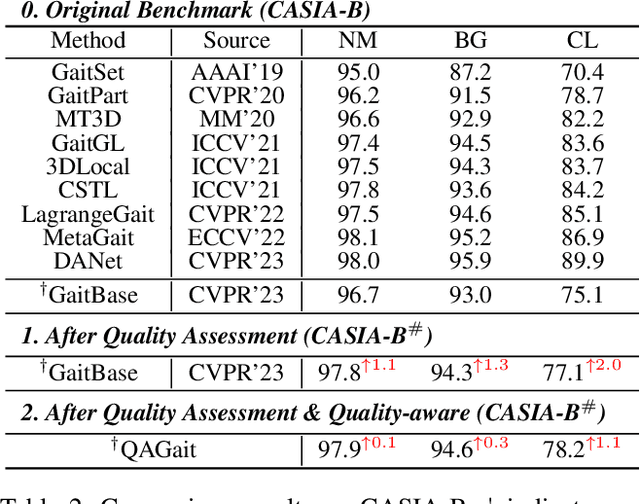
Gait recognition is a promising biometric method that aims to identify pedestrians from their unique walking patterns. Silhouette modality, renowned for its easy acquisition, simple structure, sparse representation, and convenient modeling, has been widely employed in controlled in-the-lab research. However, as gait recognition rapidly advances from in-the-lab to in-the-wild scenarios, various conditions raise significant challenges for silhouette modality, including 1) unidentifiable low-quality silhouettes (abnormal segmentation, severe occlusion, or even non-human shape), and 2) identifiable but challenging silhouettes (background noise, non-standard posture, slight occlusion). To address these challenges, we revisit gait recognition pipeline and approach gait recognition from a quality perspective, namely QAGait. Specifically, we propose a series of cost-effective quality assessment strategies, including Maxmial Connect Area and Template Match to eliminate background noises and unidentifiable silhouettes, Alignment strategy to handle non-standard postures. We also propose two quality-aware loss functions to integrate silhouette quality into optimization within the embedding space. Extensive experiments demonstrate our QAGait can guarantee both gait reliability and performance enhancement. Furthermore, our quality assessment strategies can seamlessly integrate with existing gait datasets, showcasing our superiority. Code is available at https://github.com/wzb-bupt/QAGait.