 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiTooth: a Generalizable Semi-supervised Framework for Multi-Source Tooth Segmentation
Mar 12, 2026With the rapid advancement of artificial intelligence, intelligent dentistry for clinical diagnosis and treatment has become increasingly promising. As the primary clinical dentistry task, tooth structure segmentation for Cone-Beam Computed Tomography (CBCT) has made significant progress in recent years. However, challenges arise from the obtainment difficulty of full-annotated data, and the acquisition variability of multi-source data across different institutions, which have caused low-quality utilization, voxel-level inconsistency, and domain-specific disparity in CBCT slices. Thus, the rational and efficient utilization of multi-source and unlabeled data represents a pivotal problem. In this paper, we propose SemiTooth, a generalizable semi-supervised framework for multi-source tooth segmentation. Specifically, we first compile MS3Toothset, Multi-Source Semi-Supervised Tooth DataSet for clinical dental CBCT, which contains data from three sources with different-level annotations. Then, we design a multi-teacher and multi-student framework, i.e., SemiTooth, which promotes semi-supervised learning for multi-source data. SemiTooth employs distinct student networks that learn from unlabeled data with different sources, supervised by its respective teachers. Furthermore, a Stricter Weighted-Confidence Constraint is introduced for multiple teachers to improve the multi-source accuracy.Extensive experiments are conducted on MS3Toothset to verify the feasibility and superiority of the SemiTooth framework, which achieves SOTA performance on the semi-supervised and multi-source tooth segmentation scenario.
RA-SSU: Towards Fine-Grained Audio-Visual Learning with Region-Aware Sound Source Understanding
Mar 10, 2026Audio-Visual Learning (AVL) is one fundamental task of multi-modality learning and embodied intelligence, displaying the vital role in scene understanding and interaction. However, previous researchers mostly focus on exploring downstream tasks from a coarse-grained perspective (e.g., audio-visual correspondence, sound source localization, and audio-visual event localization). Considering providing more specific scene perception details, we newly define a fine-grained Audio-Visual Learning task, termed Region-Aware Sound Source Understanding (RA-SSU), which aims to achieve region-aware, frame-level, and high-quality sound source understanding. To support this goal, we innovatively construct two corresponding datasets, i.e. fine-grained Music (f-Music) and fine-grained Lifescene (f-Lifescene), each containing annotated sound source masks and frame-by-frame textual descriptions. The f-Music dataset includes 3,976 samples across 22 scene types related to specific application scenarios, focusing on music scenes with complex instrument mixing. The f-Lifescene dataset contains 6,156 samples across 61 types representing diverse sounding objects in life scenarios. Moreover, we propose SSUFormer, a Sound-Source Understanding TransFormer benchmark that facilitates both the sound source segmentation and sound region description with a multi-modal input and multi-modal output architecture. Specifically, we design two modules for this framework, Mask Collaboration Module (MCM) and Mixture of Hierarchical-prompted Experts (MoHE), to respectively enhance the accuracy and enrich the elaboration of the sound source description. Extensive experiments are conducted on our two datasets to verify the feasibility of the task, evaluate the availability of the datasets, and demonstrate the superiority of the SSUFormer, which achieves SOTA performance on the Sound Source Understanding benchmark.
Learning Geometric Invariance for Gait Recognition
Jan 09, 2026The goal of gait recognition is to extract identity-invariant features of an individual under various gait conditions, e.g., cross-view and cross-clothing. Most gait models strive to implicitly learn the common traits across different gait conditions in a data-driven manner to pull different gait conditions closer for recognition. However, relatively few studies have explicitly explored the inherent relations between different gait conditions. For this purpose, we attempt to establish connections among different gait conditions and propose a new perspective to achieve gait recognition: variations in different gait conditions can be approximately viewed as a combination of geometric transformations. In this case, all we need is to determine the types of geometric transformations and achieve geometric invariance, then identity invariance naturally follows. As an initial attempt, we explore three common geometric transformations (i.e., Reflect, Rotate, and Scale) and design a $\mathcal{R}$eflect-$\mathcal{R}$otate-$\mathcal{S}$cale invariance learning framework, named ${\mathcal{RRS}}$-Gait. Specifically, it first flexibly adjusts the convolution kernel based on the specific geometric transformations to achieve approximate feature equivariance. Then these three equivariant-aware features are respectively fed into a global pooling operation for final invariance-aware learning. Extensive experiments on four popular gait datasets (Gait3D, GREW, CCPG, SUSTech1K) show superior performance across various gait conditions.
DanceEditor: Towards Iterative Editable Music-driven Dance Generation with Open-Vocabulary Descriptions
Aug 24, 2025



Generating coherent and diverse human dances from music signals has gained tremendous progress in animating virtual avatars. While existing methods support direct dance synthesis, they fail to recognize that enabling users to edit dance movements is far more practical in real-world choreography scenarios. Moreover, the lack of high-quality dance datasets incorporating iterative editing also limits addressing this challenge. To achieve this goal, we first construct DanceRemix, a large-scale multi-turn editable dance dataset comprising the prompt featuring over 25.3M dance frames and 84.5K pairs. In addition, we propose a novel framework for iterative and editable dance generation coherently aligned with given music signals, namely DanceEditor. Considering the dance motion should be both musical rhythmic and enable iterative editing by user descriptions, our framework is built upon a prediction-then-editing paradigm unifying multi-modal conditions. At the initial prediction stage, our framework improves the authority of generated results by directly modeling dance movements from tailored, aligned music. Moreover, at the subsequent iterative editing stages, we incorporate text descriptions as conditioning information to draw the editable results through a specifically designed Cross-modality Editing Module (CEM). Specifically, CEM adaptively integrates the initial prediction with music and text prompts as temporal motion cues to guide the synthesized sequences. Thereby, the results display music harmonics while preserving fine-grained semantic alignment with text descriptions. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected DanceRemix dataset. Code is available at https://lzvsdy.github.io/DanceEditor/.
ReMeREC: Relation-aware and Multi-entity Referring Expression Comprehension
Jul 22, 2025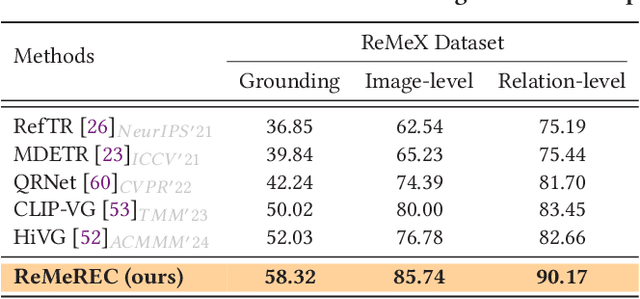

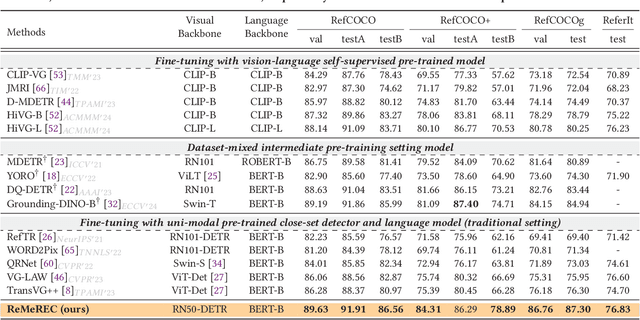
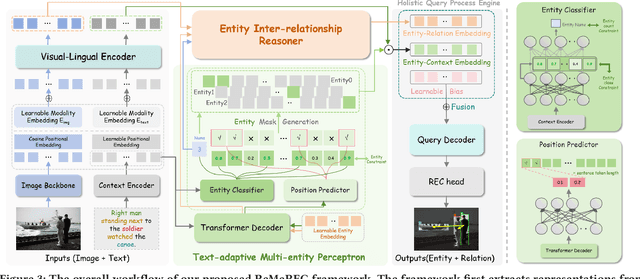
Referring Expression Comprehension (REC) aims to localize specified entities or regions in an image based on natural language descriptions. While existing methods handle single-entity localization, they often ignore complex inter-entity relationships in multi-entity scenes, limiting their accuracy and reliability. Additionally, the lack of high-quality datasets with fine-grained, paired image-text-relation annotations hinders further progress. To address this challenge, we first construct a relation-aware, multi-entity REC dataset called ReMeX, which includes detailed relationship and textual annotations. We then propose ReMeREC, a novel framework that jointly leverages visual and textual cues to localize multiple entities while modeling their inter-relations. To address the semantic ambiguity caused by implicit entity boundaries in language, we introduce the Text-adaptive Multi-entity Perceptron (TMP), which dynamically infers both the quantity and span of entities from fine-grained textual cues, producing distinctive representations. Additionally, our Entity Inter-relationship Reasoner (EIR) enhances relational reasoning and global scene understanding. To further improve language comprehension for fine-grained prompts, we also construct a small-scale auxiliary dataset, EntityText, generated using large language models. Experiments on four benchmark datasets show that ReMeREC achieves state-of-the-art performance in multi-entity grounding and relation prediction, outperforming existing approaches by a large margin.
VividListener: Expressive and Controllable Listener Dynamics Modeling for Multi-Modal Responsive Interaction
Apr 30, 2025



Generating responsive listener head dynamics with nuanced emotions and expressive reactions is crucial for practical dialogue modeling in various virtual avatar animations. Previous studies mainly focus on the direct short-term production of listener behavior. They overlook the fine-grained control over motion variations and emotional intensity, especially in long-sequence modeling. Moreover, the lack of long-term and large-scale paired speaker-listener corpora including head dynamics and fine-grained multi-modality annotations (e.g., text-based expression descriptions, emotional intensity) also limits the application of dialogue modeling.Therefore, we first newly collect a large-scale multi-turn dataset of 3D dyadic conversation containing more than 1.4M valid frames for multi-modal responsive interaction, dubbed ListenerX. Additionally, we propose VividListener, a novel framework enabling fine-grained, expressive and controllable listener dynamics modeling. This framework leverages multi-modal conditions as guiding principles for fostering coherent interactions between speakers and listeners.Specifically, we design the Responsive Interaction Module (RIM) to adaptively represent the multi-modal interactive embeddings. RIM ensures the listener dynamics achieve fine-grained semantic coordination with textual descriptions and adjustments, while preserving expressive reaction with speaker behavior. Meanwhile, we design the Emotional Intensity Tags (EIT) for emotion intensity editing with multi-modal information integration, applying to both text descriptions and listener motion amplitude.Extensive experiments conducted on our newly collected ListenerX dataset demonstrate that VividListener achieves state-of-the-art performance, realizing expressive and controllable listener dynamics.
PTM-VQA: Efficient Video Quality Assessment Leveraging Diverse PreTrained Models from the Wild
May 28, 2024

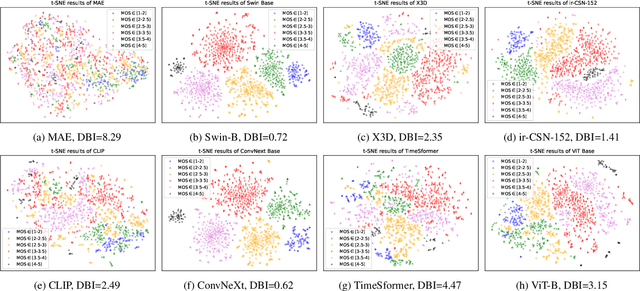

Video quality assessment (VQA) is a challenging problem due to the numerous factors that can affect the perceptual quality of a video, \eg, content attractiveness, distortion type, motion pattern, and level. However, annotating the Mean opinion score (MOS) for videos is expensive and time-consuming, which limits the scale of VQA datasets, and poses a significant obstacle for deep learning-based methods. In this paper, we propose a VQA method named PTM-VQA, which leverages PreTrained Models to transfer knowledge from models pretrained on various pre-tasks, enabling benefits for VQA from different aspects. Specifically, we extract features of videos from different pretrained models with frozen weights and integrate them to generate representation. Since these models possess various fields of knowledge and are often trained with labels irrelevant to quality, we propose an Intra-Consistency and Inter-Divisibility (ICID) loss to impose constraints on features extracted by multiple pretrained models. The intra-consistency constraint ensures that features extracted by different pretrained models are in the same unified quality-aware latent space, while the inter-divisibility introduces pseudo clusters based on the annotation of samples and tries to separate features of samples from different clusters. Furthermore, with a constantly growing number of pretrained models, it is crucial to determine which models to use and how to use them. To address this problem, we propose an efficient scheme to select suitable candidates. Models with better clustering performance on VQA datasets are chosen to be our candidates. Extensive experiments demonstrate the effectiveness of the proposed method.
MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
Mar 12, 2024Vision-language pre-trained models have achieved impressive performance on various downstream tasks. However, their large model sizes hinder their utilization on platforms with limited computational resources. We find that directly using smaller pre-trained models and applying magnitude-based pruning on CLIP models leads to inflexibility and inferior performance. Recent efforts for VLP compression either adopt uni-modal compression metrics resulting in limited performance or involve costly mask-search processes with learnable masks. In this paper, we first propose the Module-wise Pruning Error (MoPE) metric, accurately assessing CLIP module importance by performance decline on cross-modal tasks. Using the MoPE metric, we introduce a unified pruning framework applicable to both pre-training and task-specific fine-tuning compression stages. For pre-training, MoPE-CLIP effectively leverages knowledge from the teacher model, significantly reducing pre-training costs while maintaining strong zero-shot capabilities. For fine-tuning, consecutive pruning from width to depth yields highly competitive task-specific models. Extensive experiments in two stages demonstrate the effectiveness of the MoPE metric, and MoPE-CLIP outperforms previous state-of-the-art VLP compression methods.
* 18 pages, 8 figures, Published in CVPR2024
Diverse 3D Hand Gesture Prediction from Body Dynamics by Bilateral Hand Disentanglement
Mar 21, 2023Predicting natural and diverse 3D hand gestures from the upper body dynamics is a practical yet challenging task in virtual avatar creation. Previous works usually overlook the asymmetric motions between two hands and generate two hands in a holistic manner, leading to unnatural results. In this work, we introduce a novel bilateral hand disentanglement based two-stage 3D hand generation method to achieve natural and diverse 3D hand prediction from body dynamics. In the first stage, we intend to generate natural hand gestures by two hand-disentanglement branches. Considering the asymmetric gestures and motions of two hands, we introduce a Spatial-Residual Memory (SRM) module to model spatial interaction between the body and each hand by residual learning. To enhance the coordination of two hand motions wrt. body dynamics holistically, we then present a Temporal-Motion Memory (TMM) module. TMM can effectively model the temporal association between body dynamics and two hand motions. The second stage is built upon the insight that 3D hand predictions should be non-deterministic given the sequential body postures. Thus, we further diversify our 3D hand predictions based on the initial output from the stage one. Concretely, we propose a Prototypical-Memory Sampling Strategy (PSS) to generate the non-deterministic hand gestures by gradient-based Markov Chain Monte Carlo (MCMC) sampling. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on the B2H dataset and our newly collected TED Hands dataset. The dataset and code are available at https://github.com/XingqunQi-lab/Diverse-3D-Hand-Gesture-Prediction.
HumanDiffusion: a Coarse-to-Fine Alignment Diffusion Framework for Controllable Text-Driven Person Image Generation
Nov 11, 2022
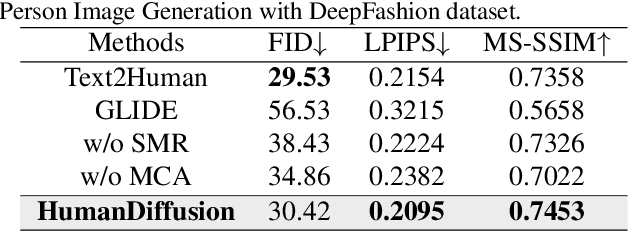
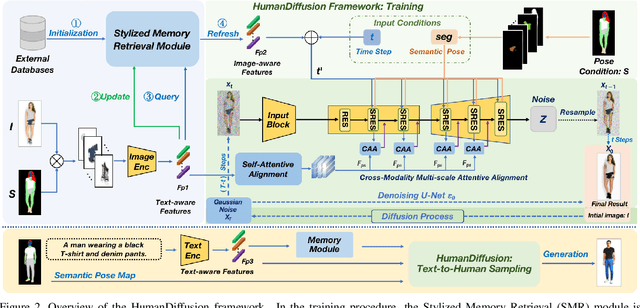

Text-driven person image generation is an emerging and challenging task in cross-modality image generation. Controllable person image generation promotes a wide range of applications such as digital human interaction and virtual try-on. However, previous methods mostly employ single-modality information as the prior condition (e.g. pose-guided person image generation), or utilize the preset words for text-driven human synthesis. Introducing a sentence composed of free words with an editable semantic pose map to describe person appearance is a more user-friendly way. In this paper, we propose HumanDiffusion, a coarse-to-fine alignment diffusion framework, for text-driven person image generation. Specifically, two collaborative modules are proposed, the Stylized Memory Retrieval (SMR) module for fine-grained feature distillation in data processing and the Multi-scale Cross-modality Alignment (MCA) module for coarse-to-fine feature alignment in diffusion. These two modules guarantee the alignment quality of the text and image, from image-level to feature-level, from low-resolution to high-resolution. As a result, HumanDiffusion realizes open-vocabulary person image generation with desired semantic poses. Extensive experiments conducted on DeepFashion demonstrate the superiority of our method compared with previous approaches. Moreover, better results could be obtained for complicated person images with various details and uncommon poses.