 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShowFace: Coordinated Face Inpainting with Memory-Disentangled Refinement Networks
Paper and Code
Apr 16, 2022


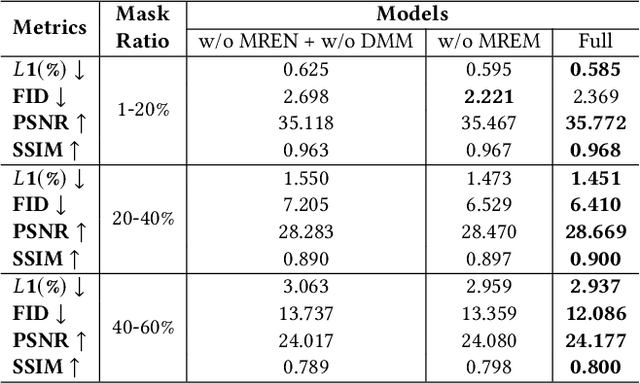
Face inpainting aims to complete the corrupted regions of the face images, which requires coordination between the completed areas and the non-corrupted areas. Recently, memory-oriented methods illustrate great prospects in the generation related tasks by introducing an external memory module to improve image coordination. However, such methods still have limitations in restoring the consistency and continuity for specificfacial semantic parts. In this paper, we propose the coarse-to-fine Memory-Disentangled Refinement Networks (MDRNets) for coordinated face inpainting, in which two collaborative modules are integrated, Disentangled Memory Module (DMM) and Mask-Region Enhanced Module (MREM). Specifically, the DMM establishes a group of disentangled memory blocks to store the semantic-decoupled face representations, which could provide the most relevant information to refine the semantic-level coordination. The MREM involves a masked correlation mining mechanism to enhance the feature relationships into the corrupted regions, which could also make up for the correlation loss caused by memory disentanglement. Furthermore, to better improve the inter-coordination between the corrupted and non-corrupted regions and enhance the intra-coordination in corrupted regions, we design InCo2 Loss, a pair of similarity based losses to constrain the feature consistency. Eventually, extensive experiments conducted on CelebA-HQ and FFHQ datasets demonstrate the superiority of our MDRNets compared with previous State-Of-The-Art methods.