 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMamba: Learned Image Compression with State Space Models
Feb 07, 2025Learned Image Compression (LIC) has explored various architectures, such as Convolutional Neural Networks (CNNs) and transformers, in modeling image content distributions in order to achieve compression effectiveness. However, achieving high rate-distortion performance while maintaining low computational complexity (\ie, parameters, FLOPs, and latency) remains challenging. In this paper, we propose a hybrid Convolution and State Space Models (SSMs) based image compression framework, termed \textit{CMamba}, to achieve superior rate-distortion performance with low computational complexity. Specifically, CMamba introduces two key components: a Content-Adaptive SSM (CA-SSM) module and a Context-Aware Entropy (CAE) module. First, we observed that SSMs excel in modeling overall content but tend to lose high-frequency details. In contrast, CNNs are proficient at capturing local details. Motivated by this, we propose the CA-SSM module that can dynamically fuse global content extracted by SSM blocks and local details captured by CNN blocks in both encoding and decoding stages. As a result, important image content is well preserved during compression. Second, our proposed CAE module is designed to reduce spatial and channel redundancies in latent representations after encoding. Specifically, our CAE leverages SSMs to parameterize the spatial content in latent representations. Benefiting from SSMs, CAE significantly improves spatial compression efficiency while reducing spatial content redundancies. Moreover, along the channel dimension, CAE reduces inter-channel redundancies of latent representations via an autoregressive manner, which can fully exploit prior knowledge from previous channels without sacrificing efficiency. Experimental results demonstrate that CMamba achieves superior rate-distortion performance.
Trust-Aware Diversion for Data-Effective Distillation
Feb 07, 2025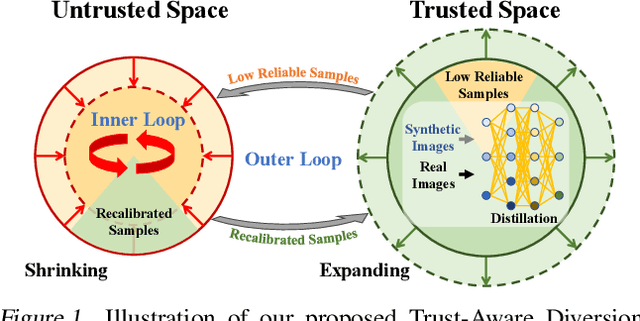
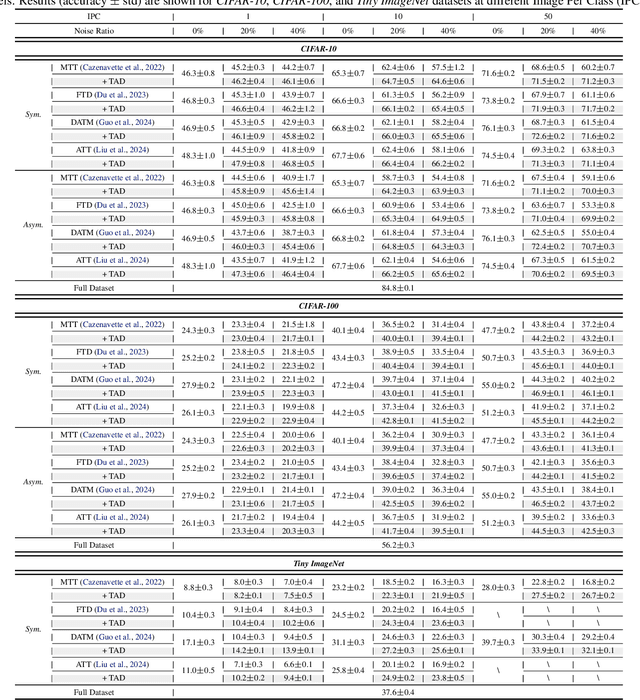
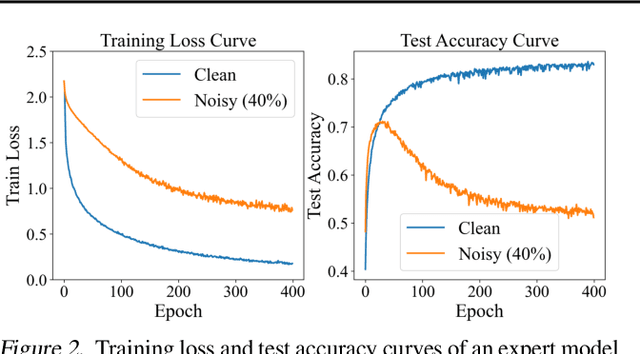
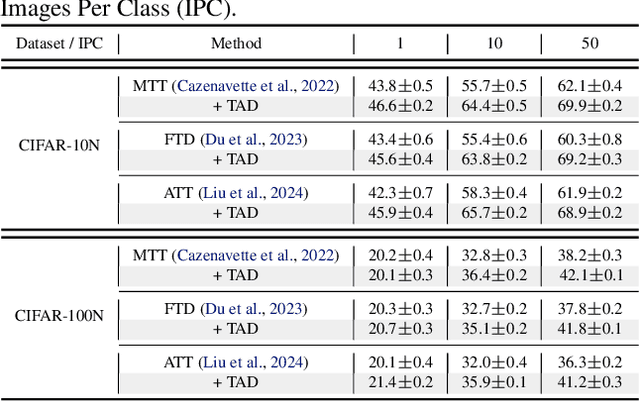
Dataset distillation compresses a large dataset into a small synthetic subset that retains essential information. Existing methods assume that all samples are perfectly labeled, limiting their real-world applications where incorrect labels are ubiquitous. These mislabeled samples introduce untrustworthy information into the dataset, which misleads model optimization in dataset distillation. To tackle this issue, we propose a Trust-Aware Diversion (TAD) dataset distillation method. Our proposed TAD introduces an iterative dual-loop optimization framework for data-effective distillation. Specifically, the outer loop divides data into trusted and untrusted spaces, redirecting distillation toward trusted samples to guarantee trust in the distillation process. This step minimizes the impact of mislabeled samples on dataset distillation. The inner loop maximizes the distillation objective by recalibrating untrusted samples, thus transforming them into valuable ones for distillation. This dual-loop iteratively refines and compensates for each other, gradually expanding the trusted space and shrinking the untrusted space. Experiments demonstrate that our method can significantly improve the performance of existing dataset distillation methods on three widely used benchmarks (CIFAR10, CIFAR100, and Tiny ImageNet) in three challenging mislabeled settings (symmetric, asymmetric, and real-world).
MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
Oct 25, 2024



Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) the largest amount of data, (2) the most extensive vocabulary, and (3) the most diverse of multi-modal camera views. Specifically, we record 282K+ sign videos covering 3,215 commonly used Auslan glosses presented by 73 signers in a studio environment. Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the advancement of sign languages worldwide. All datasets and benchmarks are available at MM-WLAuslan.
3DRealCar: An In-the-wild RGB-D Car Dataset with 360-degree Views
Jun 07, 2024

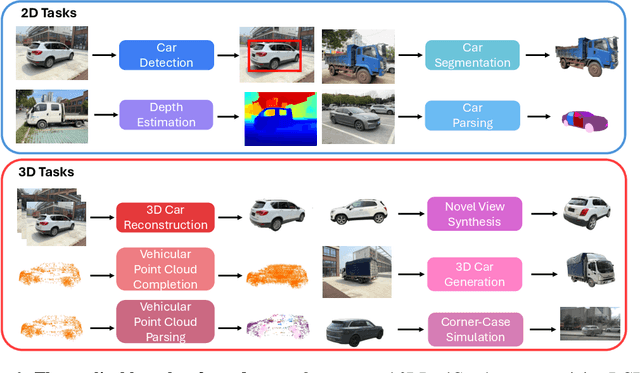
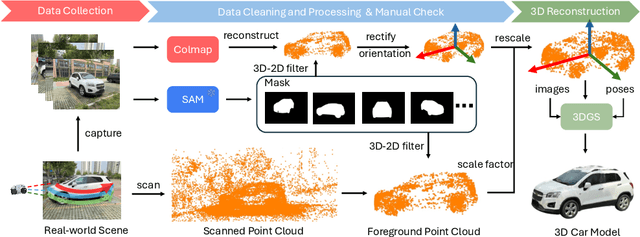
3D cars are commonly used in self-driving systems, virtual/augmented reality, and games. However, existing 3D car datasets are either synthetic or low-quality, presenting a significant gap toward the high-quality real-world 3D car datasets and limiting their applications in practical scenarios. In this paper, we propose the first large-scale 3D real car dataset, termed 3DRealCar, offering three distinctive features. (1) \textbf{High-Volume}: 2,500 cars are meticulously scanned by 3D scanners, obtaining car images and point clouds with real-world dimensions; (2) \textbf{High-Quality}: Each car is captured in an average of 200 dense, high-resolution 360-degree RGB-D views, enabling high-fidelity 3D reconstruction; (3) \textbf{High-Diversity}: The dataset contains various cars from over 100 brands, collected under three distinct lighting conditions, including reflective, standard, and dark. Additionally, we offer detailed car parsing maps for each instance to promote research in car parsing tasks. Moreover, we remove background point clouds and standardize the car orientation to a unified axis for the reconstruction only on cars without background and controllable rendering. We benchmark 3D reconstruction results with state-of-the-art methods across each lighting condition in 3DRealCar. Extensive experiments demonstrate that the standard lighting condition part of 3DRealCar can be used to produce a large number of high-quality 3D cars, improving various 2D and 3D tasks related to cars. Notably, our dataset brings insight into the fact that recent 3D reconstruction methods face challenges in reconstructing high-quality 3D cars under reflective and dark lighting conditions. \textcolor{red}{\href{https://xiaobiaodu.github.io/3drealcar/}{Our dataset is available here.}}
Robust and Efficient Segmentation of Cross-domain Medical Images
Jul 26, 2022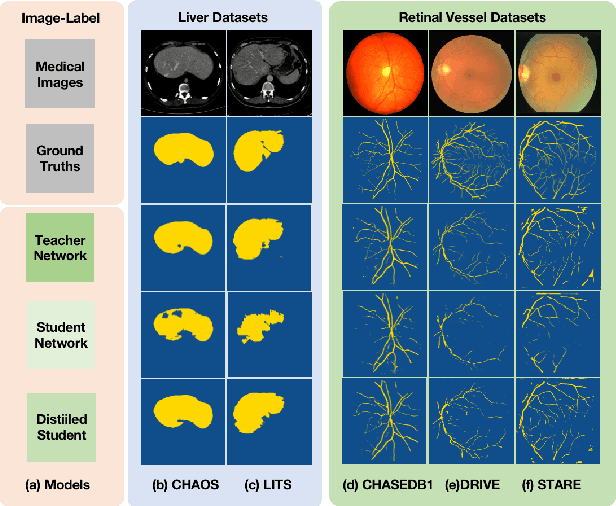
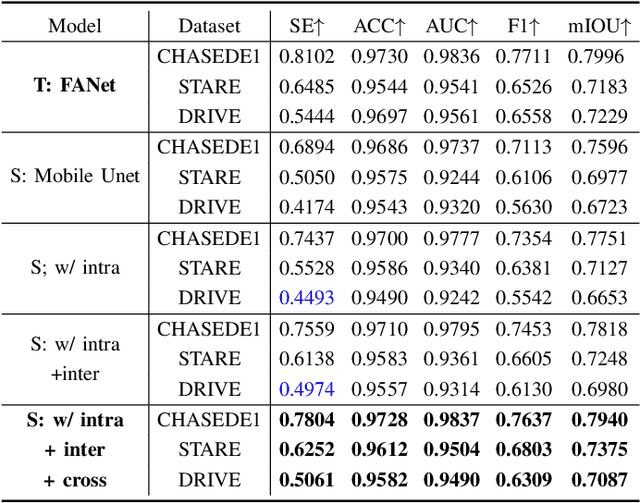
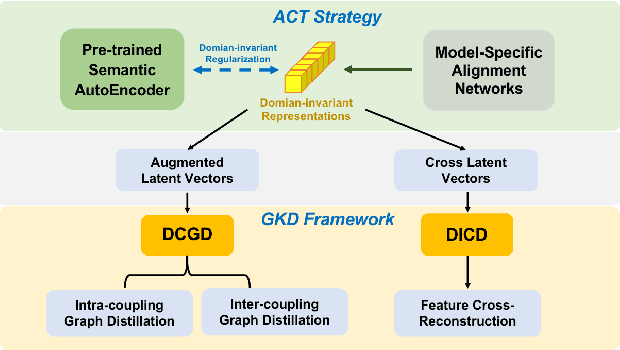
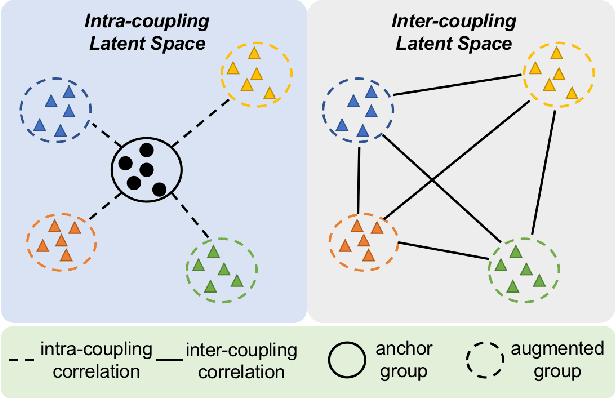
Efficient medical image segmentation aims to provide accurate pixel-wise prediction for the medical images with the lightweight implementation framework. However, lightweight frameworks generally fail to achieve high performance, and suffer from the poor generalizable ability on cross-domain tasks.In this paper, we propose a generalizable knowledge distillation method for robust and efficient segmentation of cross-domain medical images. Primarily, we propose the Model-Specific Alignment Networks (MSAN) to provide the domain-invariant representations which are regularized by a Pre-trained Semantic AutoEncoder (P-SAE). Meanwhile, a customized Alignment Consistency Training (ACT) strategy is designed to promote the MSAN training. With the domain-invariant representative vectors in MSAN, we propose two generalizable knowledge distillation schemes, Dual Contrastive Graph Distillation (DCGD) and Domain-Invariant Cross Distillation (DICD). Specifically, in DCGD, two types of implicit contrastive graphs are designed to represent the intra-coupling and inter-coupling semantic correlations from the perspective of data distribution. In DICD, the domain-invariant semantic vectors from the two models (i.e., teacher and student) are leveraged to cross-reconstruct features by the header exchange of MSAN, which achieves generalizable improvement for both the encoder and decoder in the student model. Furthermore, a metric named Fr\'echet Semantic Distance (FSD) is tailored to verify the effectiveness of the regularized domain-invariant features. Extensive experiments conducted on the Liver and Retinal Vessel Segmentation datasets demonstrate the priority of our method, in terms of performance and generalization on lightweight frameworks.
ShowFace: Coordinated Face Inpainting with Memory-Disentangled Refinement Networks
Apr 16, 2022


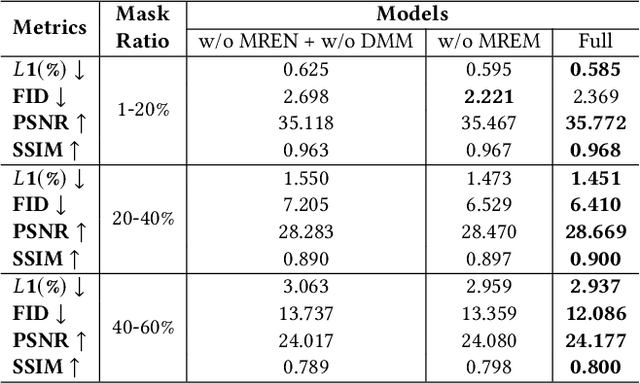
Face inpainting aims to complete the corrupted regions of the face images, which requires coordination between the completed areas and the non-corrupted areas. Recently, memory-oriented methods illustrate great prospects in the generation related tasks by introducing an external memory module to improve image coordination. However, such methods still have limitations in restoring the consistency and continuity for specificfacial semantic parts. In this paper, we propose the coarse-to-fine Memory-Disentangled Refinement Networks (MDRNets) for coordinated face inpainting, in which two collaborative modules are integrated, Disentangled Memory Module (DMM) and Mask-Region Enhanced Module (MREM). Specifically, the DMM establishes a group of disentangled memory blocks to store the semantic-decoupled face representations, which could provide the most relevant information to refine the semantic-level coordination. The MREM involves a masked correlation mining mechanism to enhance the feature relationships into the corrupted regions, which could also make up for the correlation loss caused by memory disentanglement. Furthermore, to better improve the inter-coordination between the corrupted and non-corrupted regions and enhance the intra-coordination in corrupted regions, we design InCo2 Loss, a pair of similarity based losses to constrain the feature consistency. Eventually, extensive experiments conducted on CelebA-HQ and FFHQ datasets demonstrate the superiority of our MDRNets compared with previous State-Of-The-Art methods.
PAENet: A Progressive Attention-Enhanced Network for 3D to 2D Retinal Vessel Segmentation
Aug 26, 2021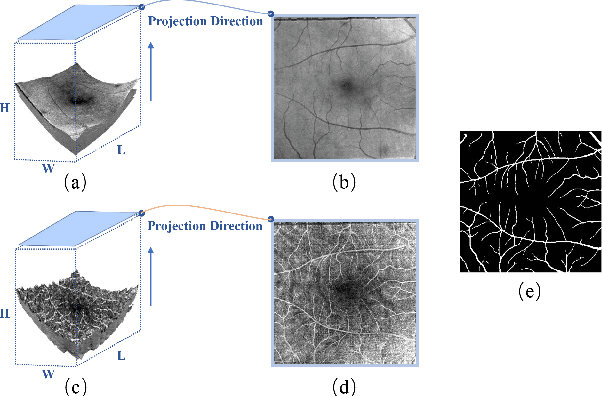
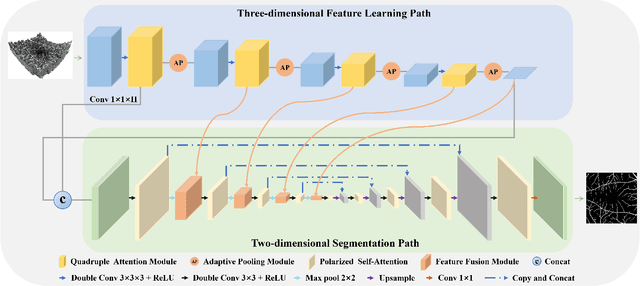
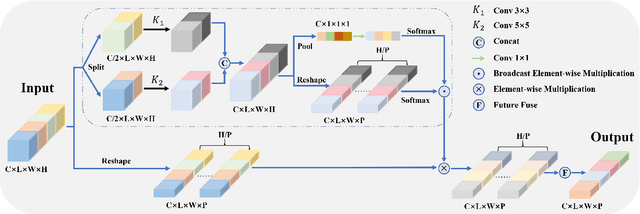

3D to 2D retinal vessel segmentation is a challenging problem in Optical Coherence Tomography Angiography (OCTA) images. Accurate retinal vessel segmentation is important for the diagnosis and prevention of ophthalmic diseases. However, making full use of the 3D data of OCTA volumes is a vital factor for obtaining satisfactory segmentation results. In this paper, we propose a Progressive Attention-Enhanced Network (PAENet) based on attention mechanisms to extract rich feature representation. Specifically, the framework consists of two main parts, the three-dimensional feature learning path and the two-dimensional segmentation path. In the three-dimensional feature learning path, we design a novel Adaptive Pooling Module (APM) and propose a new Quadruple Attention Module (QAM). The APM captures dependencies along the projection direction of volumes and learns a series of pooling coefficients for feature fusion, which efficiently reduces feature dimension. In addition, the QAM reweights the features by capturing four-group cross-dimension dependencies, which makes maximum use of 4D feature tensors. In the two-dimensional segmentation path, to acquire more detailed information, we propose a Feature Fusion Module (FFM) to inject 3D information into the 2D path. Meanwhile, we adopt the Polarized Self-Attention (PSA) block to model the semantic interdependencies in spatial and channel dimensions respectively. Experimentally, our extensive experiments on the OCTA-500 dataset show that our proposed algorithm achieves state-of-the-art performance compared with previous methods.