 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Feature Alignment in Generalist Graph Anomaly Detection: A Relational Fingerprint-based Approach
May 25, 2026Generalist graph anomaly detection (GAD) aims to detect anomalies on unseen graphs without graph-specific retraining. Nevertheless, existing approaches primarily focus on aligning heterogeneous features across different data domains via PCA-based projection, which harmonizes feature dimensions ignores feature semantics. As a result, GAD models fail to learn transferable semantic knowledge, and even exhibit negative transfer on unseen graphs. To address this issue, we propose a Relational Fingerprint-based generalist GAD approach (ReFi-GAD for short), aligning heterogeneous raw features with a universal and semantics-aware Relational Fingerprint (ReFi) that encodes anomaly-indicative cues from both contextual and structural perspectives. Building on ReFi, we design a fingerprint-grounded generalist GAD model, which combines a transformer-based encoder to capture domain-invariant knowledge with an SNR-guided refinement module for domain-specific adaptation. Extensive experiments on 14 datasets demonstrate that ReFi-GAD significantly outperforms state-of-the-art methods.
Towards One-for-All Anomaly Detection for Tabular Data
Mar 15, 2026Tabular anomaly detection (TAD) aims to identify samples that deviate from the majority in tabular data and is critical in many real-world applications. However, existing methods follow a ``one model for one dataset (OFO)'' paradigm, which relies on dataset-specific training and thus incurs high computational cost and yields limited generalization to unseen domains. To address these limitations, we propose OFA-TAD, a generalist one-for-all (OFA) TAD framework that only requires one-time training on multiple source datasets and can generalize to unseen datasets from diverse domains on-the-fly. To realize one-for-all tabular anomaly detection, OFA-TAD extracts neighbor-distance patterns as transferable cues, and introduces multi-view neighbor-distance representations from multiple transformation-induced metric spaces to mitigate the transformation sensitivity of distance profiles. To adaptively combine multi-view distance evidence, a Mixture-of-Experts (MoE) scoring network is employed for view-specific anomaly scoring and entropy-regularized gated fusion, with a multi-strategy anomaly synthesis mechanism to support training under the one-class constraint. Extensive experiments on 34 datasets from 14 domains demonstrate that OFA-TAD achieves superior anomaly detection performance and strong cross-domain generalizability under the strict OFA setting.
Revealing Combinatorial Reasoning of GNNs via Graph Concept Bottleneck Layer
Mar 02, 2026Despite their success in various domains, the growing dependence on GNNs raises a critical concern about the nature of the combinatorial reasoning underlying their predictions, which is often hidden within their black-box architectures. Addressing this challenge requires understanding how GNNs translate topological patterns into logical rules. However, current works only uncover the hard logical rules over graph concepts, which cannot quantify the contribution of each concept to prediction. Moreover, they are post-hoc interpretable methods that generate explanations after model training and may not accurately reflect the true combinatorial reasoning of GNNs, since they approximate it with a surrogate. In this work, we develop a graph concept bottleneck layer that can be integrated into any GNN architectures to guide them to predict the selected discriminative global graph concepts. The predicted concept scores are further projected to class labels by a sparse linear layer. It enforces the combinatorial reasoning of GNNs' predictions to fit the soft logical rule over graph concepts and thus can quantify the contribution of each concept. To further improve the quality of the concept bottleneck, we treat concepts as "graph words" and graphs as "graph sentences", and leverage language models to learn graph concept embeddings. Extensive experiments on multiple datasets show that our method GCBMs achieve state-of-the-art performance both in classification and interpretability.
PMCE: Probabilistic Multi-Granularity Semantics with Caption-Guided Enhancement for Few-Shot Learning
Jan 20, 2026Few-shot learning aims to identify novel categories from only a handful of labeled samples, where prototypes estimated from scarce data are often biased and generalize poorly. Semantic-based methods alleviate this by introducing coarse class-level information, but they are mostly applied on the support side, leaving query representations unchanged. In this paper, we present PMCE, a Probabilistic few-shot framework that leverages Multi-granularity semantics with Caption-guided Enhancement. PMCE constructs a nonparametric knowledge bank that stores visual statistics for each category as well as CLIP-encoded class name embeddings of the base classes. At meta-test time, the most relevant base classes are retrieved based on the similarities of class name embeddings for each novel category. These statistics are then aggregated into category-specific prior information and fused with the support set prototypes via a simple MAP update. Simultaneously, a frozen BLIP captioner provides label-free instance-level image descriptions, and a lightweight enhancer trained on base classes optimizes both support prototypes and query features under an inductive protocol with a consistency regularization to stabilize noisy captions. Experiments on four benchmarks show that PMCE consistently improves over strong baselines, achieving up to 7.71% absolute gain over the strongest semantic competitor on MiniImageNet in the 1-shot setting. Our code is available at https://anonymous.4open.science/r/PMCE-275D
Hybrid Quantum-Classical Neural Networks for Few-Shot Credit Risk Assessment
Sep 17, 2025Quantum Machine Learning (QML) offers a new paradigm for addressing complex financial problems intractable for classical methods. This work specifically tackles the challenge of few-shot credit risk assessment, a critical issue in inclusive finance where data scarcity and imbalance limit the effectiveness of conventional models. To address this, we design and implement a novel hybrid quantum-classical workflow. The methodology first employs an ensemble of classical machine learning models (Logistic Regression, Random Forest, XGBoost) for intelligent feature engineering and dimensionality reduction. Subsequently, a Quantum Neural Network (QNN), trained via the parameter-shift rule, serves as the core classifier. This framework was evaluated through numerical simulations and deployed on the Quafu Quantum Cloud Platform's ScQ-P21 superconducting processor. On a real-world credit dataset of 279 samples, our QNN achieved a robust average AUC of 0.852 +/- 0.027 in simulations and yielded an impressive AUC of 0.88 in the hardware experiment. This performance surpasses a suite of classical benchmarks, with a particularly strong result on the recall metric. This study provides a pragmatic blueprint for applying quantum computing to data-constrained financial scenarios in the NISQ era and offers valuable empirical evidence supporting its potential in high-stakes applications like inclusive finance.
FOCUS: Frequency-Optimized Conditioning of DiffUSion Models for mitigating catastrophic forgetting during Test-Time Adaptation
Aug 20, 2025Test-time adaptation enables models to adapt to evolving domains. However, balancing the tradeoff between preserving knowledge and adapting to domain shifts remains challenging for model adaptation methods, since adapting to domain shifts can induce forgetting of task-relevant knowledge. To address this problem, we propose FOCUS, a novel frequency-based conditioning approach within a diffusion-driven input-adaptation framework. Utilising learned, spatially adaptive frequency priors, our approach conditions the reverse steps during diffusion-driven denoising to preserve task-relevant semantic information for dense prediction. FOCUS leverages a trained, lightweight, Y-shaped Frequency Prediction Network (Y-FPN) that disentangles high and low frequency information from noisy images. This minimizes the computational costs involved in implementing our approach in a diffusion-driven framework. We train Y-FPN with FrequencyMix, a novel data augmentation method that perturbs the images across diverse frequency bands, which improves the robustness of our approach to diverse corruptions. We demonstrate the effectiveness of FOCUS for semantic segmentation and monocular depth estimation across 15 corruption types and three datasets, achieving state-of-the-art averaged performance. In addition to improving standalone performance, FOCUS complements existing model adaptation methods since we can derive pseudo labels from FOCUS-denoised images for additional supervision. Even under limited, intermittent supervision with the pseudo labels derived from the FOCUS denoised images, we show that FOCUS mitigates catastrophic forgetting for recent model adaptation methods.
Trust-Aware Diversion for Data-Effective Distillation
Feb 07, 2025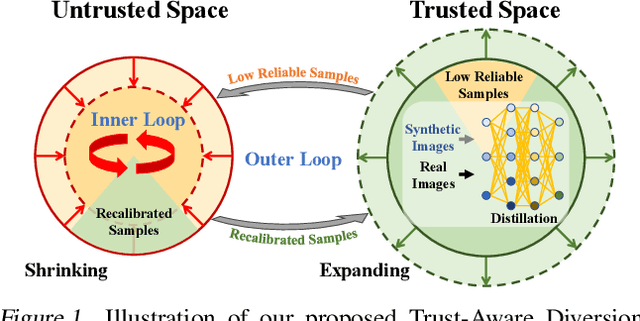
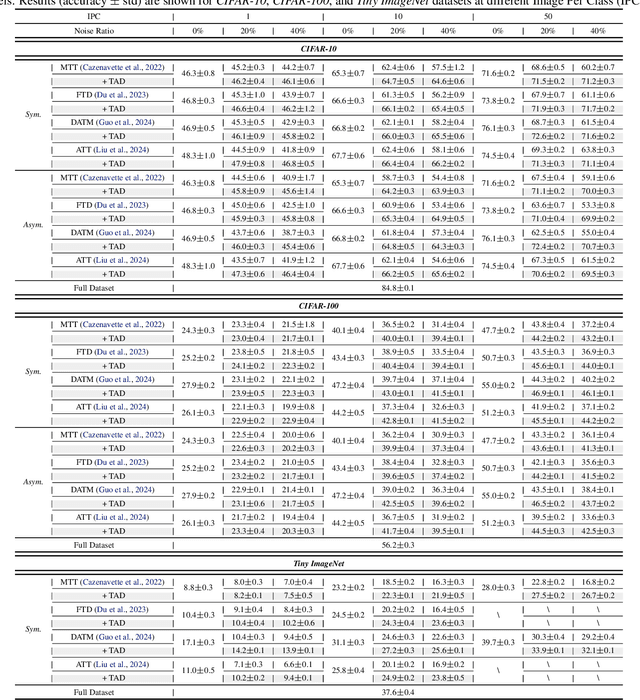
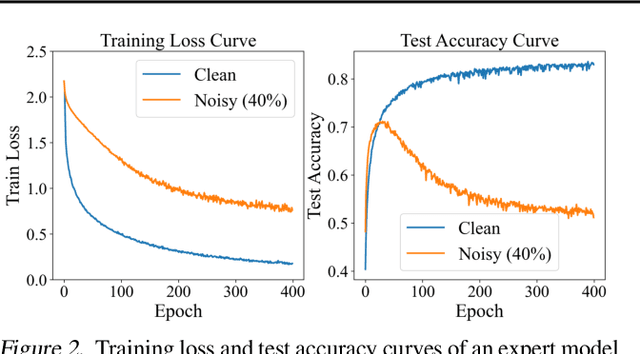
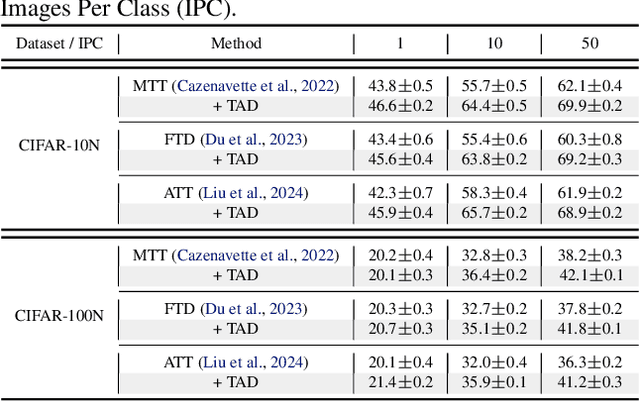
Dataset distillation compresses a large dataset into a small synthetic subset that retains essential information. Existing methods assume that all samples are perfectly labeled, limiting their real-world applications where incorrect labels are ubiquitous. These mislabeled samples introduce untrustworthy information into the dataset, which misleads model optimization in dataset distillation. To tackle this issue, we propose a Trust-Aware Diversion (TAD) dataset distillation method. Our proposed TAD introduces an iterative dual-loop optimization framework for data-effective distillation. Specifically, the outer loop divides data into trusted and untrusted spaces, redirecting distillation toward trusted samples to guarantee trust in the distillation process. This step minimizes the impact of mislabeled samples on dataset distillation. The inner loop maximizes the distillation objective by recalibrating untrusted samples, thus transforming them into valuable ones for distillation. This dual-loop iteratively refines and compensates for each other, gradually expanding the trusted space and shrinking the untrusted space. Experiments demonstrate that our method can significantly improve the performance of existing dataset distillation methods on three widely used benchmarks (CIFAR10, CIFAR100, and Tiny ImageNet) in three challenging mislabeled settings (symmetric, asymmetric, and real-world).
TsCA: On the Semantic Consistency Alignment via Conditional Transport for Compositional Zero-Shot Learning
Aug 16, 2024



Compositional Zero-Shot Learning (CZSL) aims to recognize novel \textit{state-object} compositions by leveraging the shared knowledge of their primitive components. Despite considerable progress, effectively calibrating the bias between semantically similar multimodal representations, as well as generalizing pre-trained knowledge to novel compositional contexts, remains an enduring challenge. In this paper, our interest is to revisit the conditional transport (CT) theory and its homology to the visual-semantics interaction in CZSL and further, propose a novel Trisets Consistency Alignment framework (dubbed TsCA) that well-addresses these issues. Concretely, we utilize three distinct yet semantically homologous sets, i.e., patches, primitives, and compositions, to construct pairwise CT costs to minimize their semantic discrepancies. To further ensure the consistency transfer within these sets, we implement a cycle-consistency constraint that refines the learning by guaranteeing the feature consistency of the self-mapping during transport flow, regardless of modality. Moreover, we extend the CT plans to an open-world setting, which enables the model to effectively filter out unfeasible pairs, thereby speeding up the inference as well as increasing the accuracy. Extensive experiments are conducted to verify the effectiveness of the proposed method.
Reframing the Relationship in Out-of-Distribution Detection
May 27, 2024The remarkable achievements of Large Language Models (LLMs) have captivated the attention of both academia and industry, transcending their initial role in dialogue generation. The utilization of LLMs as intermediary agents in various tasks has yielded promising results, sparking a wave of innovation in artificial intelligence. Building on these breakthroughs, we introduce a novel approach that integrates the agent paradigm into the Out-of-distribution (OOD) detection task, aiming to enhance its robustness and adaptability. Our proposed method, Concept Matching with Agent (CMA), employs neutral prompts as agents to augment the CLIP-based OOD detection process. These agents function as dynamic observers and communication hubs, interacting with both In-distribution (ID) labels and data inputs to form vector triangle relationships. This triangular framework offers a more nuanced approach than the traditional binary relationship, allowing for better separation and identification of ID and OOD inputs. Our extensive experimental results showcase the superior performance of CMA over both zero-shot and training-required methods in a diverse array of real-world scenarios.
Deep Hierarchical Graph Alignment Kernels
May 09, 2024Typical R-convolution graph kernels invoke the kernel functions that decompose graphs into non-isomorphic substructures and compare them. However, overlooking implicit similarities and topological position information between those substructures limits their performances. In this paper, we introduce Deep Hierarchical Graph Alignment Kernels (DHGAK) to resolve this problem. Specifically, the relational substructures are hierarchically aligned to cluster distributions in their deep embedding space. The substructures belonging to the same cluster are assigned the same feature map in the Reproducing Kernel Hilbert Space (RKHS), where graph feature maps are derived by kernel mean embedding. Theoretical analysis guarantees that DHGAK is positive semi-definite and has linear separability in the RKHS. Comparison with state-of-the-art graph kernels on various benchmark datasets demonstrates the effectiveness and efficiency of DHGAK. The code is available at Github (https://github.com/EWesternRa/DHGAK).