 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Like Humans: Use Meta-cognitive Reflection for Efficient Self-Improvement
Jan 17, 2026While Large Language Models (LLMs) enable complex autonomous behavior, current agents remain constrained by static, human-designed prompts that limit adaptability. Existing self-improving frameworks attempt to bridge this gap but typically rely on inefficient, multi-turn recursive loops that incur high computational costs. To address this, we propose Metacognitive Agent Reflective Self-improvement (MARS), a framework that achieves efficient self-evolution within a single recurrence cycle. Inspired by educational psychology, MARS mimics human learning by integrating principle-based reflection (abstracting normative rules to avoid errors) and procedural reflection (deriving step-by-step strategies for success). By synthesizing these insights into optimized instructions, MARS allows agents to systematically refine their reasoning logic without continuous online feedback. Extensive experiments on six benchmarks demonstrate that MARS outperforms state-of-the-art self-evolving systems while significantly reducing computational overhead.
Transductive Reward Inference on Graph
Feb 06, 2024



In this study, we present a transductive inference approach on that reward information propagation graph, which enables the effective estimation of rewards for unlabelled data in offline reinforcement learning. Reward inference is the key to learning effective policies in practical scenarios, while direct environmental interactions are either too costly or unethical and the reward functions are rarely accessible, such as in healthcare and robotics. Our research focuses on developing a reward inference method based on the contextual properties of information propagation on graphs that capitalizes on a constrained number of human reward annotations to infer rewards for unlabelled data. We leverage both the available data and limited reward annotations to construct a reward propagation graph, wherein the edge weights incorporate various influential factors pertaining to the rewards. Subsequently, we employ the constructed graph for transductive reward inference, thereby estimating rewards for unlabelled data. Furthermore, we establish the existence of a fixed point during several iterations of the transductive inference process and demonstrate its at least convergence to a local optimum. Empirical evaluations on locomotion and robotic manipulation tasks validate the effectiveness of our approach. The application of our inferred rewards improves the performance in offline reinforcement learning tasks.
Policy Dispersion in Non-Markovian Environment
Feb 28, 2023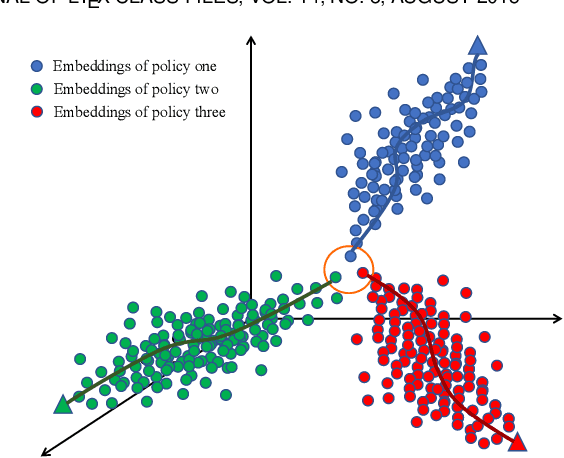

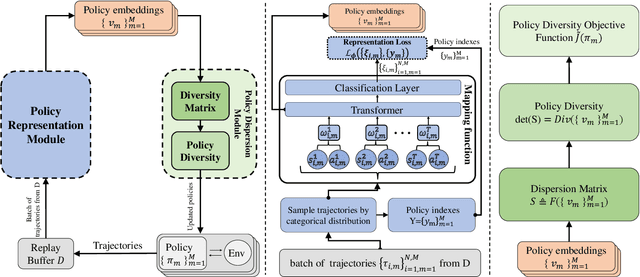

Markov Decision Process (MDP) presents a mathematical framework to formulate the learning processes of agents in reinforcement learning. MDP is limited by the Markovian assumption that a reward only depends on the immediate state and action. However, a reward sometimes depends on the history of states and actions, which may result in the decision process in a non-Markovian environment. In such environments, agents receive rewards via temporally-extended behaviors sparsely, and the learned policies may be similar. This leads the agents acquired with similar policies generally overfit to the given task and can not quickly adapt to perturbations of environments. To resolve this problem, this paper tries to learn the diverse policies from the history of state-action pairs under a non-Markovian environment, in which a policy dispersion scheme is designed for seeking diverse policy representation. Specifically, we first adopt a transformer-based method to learn policy embeddings. Then, we stack the policy embeddings to construct a dispersion matrix to induce a set of diverse policies. Finally, we prove that if the dispersion matrix is positive definite, the dispersed embeddings can effectively enlarge the disagreements across policies, yielding a diverse expression for the original policy embedding distribution. Experimental results show that this dispersion scheme can obtain more expressive diverse policies, which then derive more robust performance than recent learning baselines under various learning environments.