 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniArray: Unified Spectral-Spatial Modeling for Array-Geometry-Agnostic Speech Separation
Mar 07, 2025

Array-geometry-agnostic speech separation (AGA-SS) aims to develop an effective separation method regardless of the microphone array geometry. Conventional methods rely on permutation-free operations, such as summation or attention mechanisms, to capture spatial information. However, these approaches often incur high computational costs or disrupt the effective use of spatial information during intra- and inter-channel interactions, leading to suboptimal performance. To address these issues, we propose UniArray, a novel approach that abandons the conventional interleaving manner. UniArray consists of three key components: a virtual microphone estimation (VME) module, a feature extraction and fusion module, and a hierarchical dual-path separator. The VME ensures robust performance across arrays with varying channel numbers. The feature extraction and fusion module leverages a spectral feature extraction module and a spatial dictionary learning (SDL) module to extract and fuse frequency-bin-level features, allowing the separator to focus on using the fused features. The hierarchical dual-path separator models feature dependencies along the time and frequency axes while maintaining computational efficiency. Experimental results show that UniArray outperforms state-of-the-art methods in SI-SDRi, WB-PESQ, NB-PESQ, and STOI across both seen and unseen array geometries.
Towards a Reward-Free Reinforcement Learning Framework for Vehicle Control
Feb 21, 2025



Reinforcement learning plays a crucial role in vehicle control by guiding agents to learn optimal control strategies through designing or learning appropriate reward signals. However, in vehicle control applications, rewards typically need to be manually designed while considering multiple implicit factors, which easily introduces human biases. Although imitation learning methods does not rely on explicit reward signals, they necessitate high-quality expert actions, which are often challenging to acquire. To address these issues, we propose a reward-free reinforcement learning framework (RFRLF). This framework directly learns the target states to optimize agent behavior through a target state prediction network (TSPN) and a reward-free state-guided policy network (RFSGPN), avoiding the dependence on manually designed reward signals. Specifically, the policy network is learned via minimizing the differences between the predicted state and the expert state. Experimental results demonstrate the effectiveness of the proposed RFRLF in controlling vehicle driving, showing its advantages in improving learning efficiency and adapting to reward-free environments.
Control the GNN: Utilizing Neural Controller with Lyapunov Stability for Test-Time Feature Reconstruction
Oct 13, 2024



The performance of graph neural networks (GNNs) is susceptible to discrepancies between training and testing sample distributions. Prior studies have attempted to enhance GNN performance by reconstructing node features during the testing phase without modifying the model parameters. However, these approaches lack theoretical analysis of the proximity between predictions and ground truth at test time. In this paper, we propose a novel node feature reconstruction method grounded in Lyapunov stability theory. Specifically, we model the GNN as a control system during the testing phase, considering node features as control variables. A neural controller that adheres to the Lyapunov stability criterion is then employed to reconstruct these node features, ensuring that the predictions progressively approach the ground truth at test time. We validate the effectiveness of our approach through extensive experiments across multiple datasets, demonstrating significant performance improvements.
Distribution shift mitigation at test time with performance guarantees
Aug 18, 2023


Due to inappropriate sample selection and limited training data, a distribution shift often exists between the training and test sets. This shift can adversely affect the test performance of Graph Neural Networks (GNNs). Existing approaches mitigate this issue by either enhancing the robustness of GNNs to distribution shift or reducing the shift itself. However, both approaches necessitate retraining the model, which becomes unfeasible when the model structure and parameters are inaccessible. To address this challenge, we propose FR-GNN, a general framework for GNNs to conduct feature reconstruction. FRGNN constructs a mapping relationship between the output and input of a well-trained GNN to obtain class representative embeddings and then uses these embeddings to reconstruct the features of labeled nodes. These reconstructed features are then incorporated into the message passing mechanism of GNNs to influence the predictions of unlabeled nodes at test time. Notably, the reconstructed node features can be directly utilized for testing the well-trained model, effectively reducing the distribution shift and leading to improved test performance. This remarkable achievement is attained without any modifications to the model structure or parameters. We provide theoretical guarantees for the effectiveness of our framework. Furthermore, we conduct comprehensive experiments on various public datasets. The experimental results demonstrate the superior performance of FRGNN in comparison to mainstream methods.
Leveraging Label Non-Uniformity for Node Classification in Graph Neural Networks
Apr 29, 2023



In node classification using graph neural networks (GNNs), a typical model generates logits for different class labels at each node. A softmax layer often outputs a label prediction based on the largest logit. We demonstrate that it is possible to infer hidden graph structural information from the dataset using these logits. We introduce the key notion of label non-uniformity, which is derived from the Wasserstein distance between the softmax distribution of the logits and the uniform distribution. We demonstrate that nodes with small label non-uniformity are harder to classify correctly. We theoretically analyze how the label non-uniformity varies across the graph, which provides insights into boosting the model performance: increasing training samples with high non-uniformity or dropping edges to reduce the maximal cut size of the node set of small non-uniformity. These mechanisms can be easily added to a base GNN model. Experimental results demonstrate that our approach improves the performance of many benchmark base models.
Distributional Signals for Node Classification in Graph Neural Networks
Apr 07, 2023



In graph neural networks (GNNs), both node features and labels are examples of graph signals, a key notion in graph signal processing (GSP). While it is common in GSP to impose signal smoothness constraints in learning and estimation tasks, it is unclear how this can be done for discrete node labels. We bridge this gap by introducing the concept of distributional graph signals. In our framework, we work with the distributions of node labels instead of their values and propose notions of smoothness and non-uniformity of such distributional graph signals. We then propose a general regularization method for GNNs that allows us to encode distributional smoothness and non-uniformity of the model output in semi-supervised node classification tasks. Numerical experiments demonstrate that our method can significantly improve the performance of most base GNN models in different problem settings.
Policy Dispersion in Non-Markovian Environment
Feb 28, 2023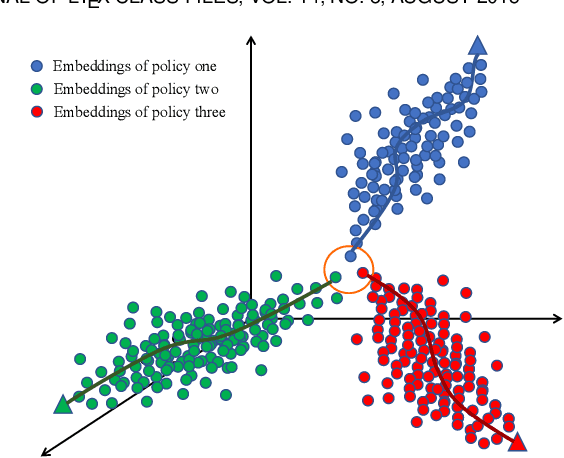

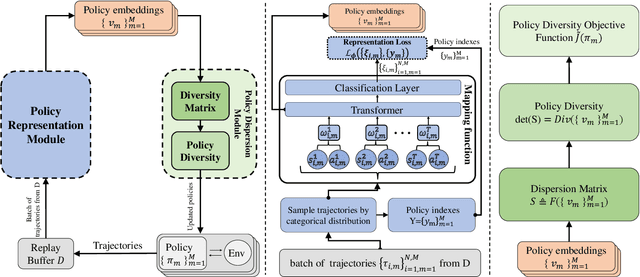

Markov Decision Process (MDP) presents a mathematical framework to formulate the learning processes of agents in reinforcement learning. MDP is limited by the Markovian assumption that a reward only depends on the immediate state and action. However, a reward sometimes depends on the history of states and actions, which may result in the decision process in a non-Markovian environment. In such environments, agents receive rewards via temporally-extended behaviors sparsely, and the learned policies may be similar. This leads the agents acquired with similar policies generally overfit to the given task and can not quickly adapt to perturbations of environments. To resolve this problem, this paper tries to learn the diverse policies from the history of state-action pairs under a non-Markovian environment, in which a policy dispersion scheme is designed for seeking diverse policy representation. Specifically, we first adopt a transformer-based method to learn policy embeddings. Then, we stack the policy embeddings to construct a dispersion matrix to induce a set of diverse policies. Finally, we prove that if the dispersion matrix is positive definite, the dispersed embeddings can effectively enlarge the disagreements across policies, yielding a diverse expression for the original policy embedding distribution. Experimental results show that this dispersion scheme can obtain more expressive diverse policies, which then derive more robust performance than recent learning baselines under various learning environments.
Learning the Network of Graphs for Graph Neural Networks
Oct 08, 2022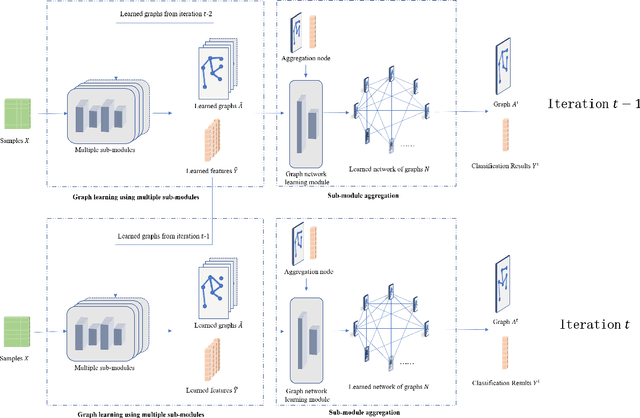
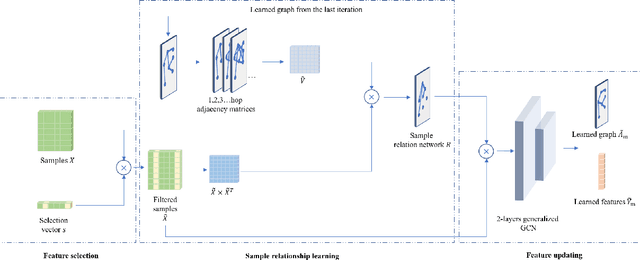
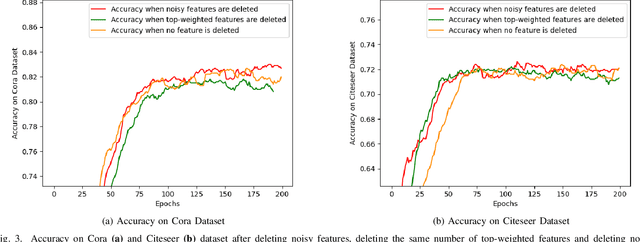
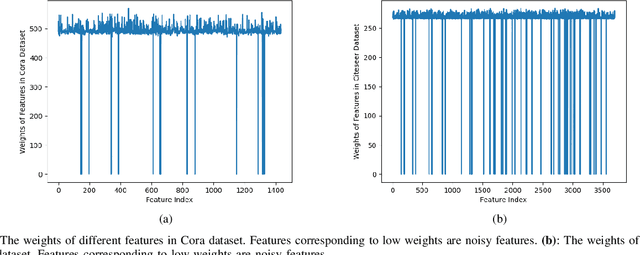
Graph neural networks (GNNs) have achieved great success in many scenarios with graph-structured data. However, in many real applications, there are three issues when applying GNNs: graphs are unknown, nodes have noisy features, and graphs contain noisy connections. Aiming at solving these problems, we propose a new graph neural network named as GL-GNN. Our model includes multiple sub-modules, each sub-module selects important data features and learn the corresponding key relation graph of data samples when graphs are unknown. GL-GNN further obtains the network of graphs by learning the network of sub-modules. The learned graphs are further fused using an aggregation method over the network of graphs. Our model solves the first issue by simultaneously learning multiple relation graphs of data samples as well as a relation network of graphs, and solves the second and the third issue by selecting important data features as well as important data sample relations. We compare our method with 14 baseline methods on seven datasets when the graph is unknown and 11 baseline methods on two datasets when the graph is known. The results show that our method achieves better accuracies than the baseline methods and is capable of selecting important features and graph edges from the dataset. Our code will be publicly available at \url{https://github.com/Looomo/GL-GNN}.
Sigmoidally Preconditioned Off-policy Learning:a new exploration method for reinforcement learning
May 20, 2022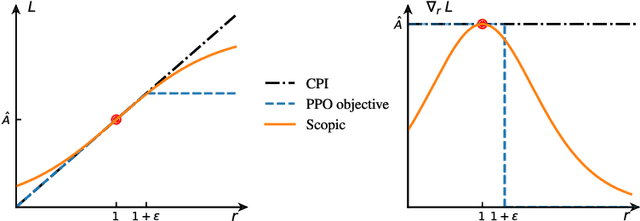
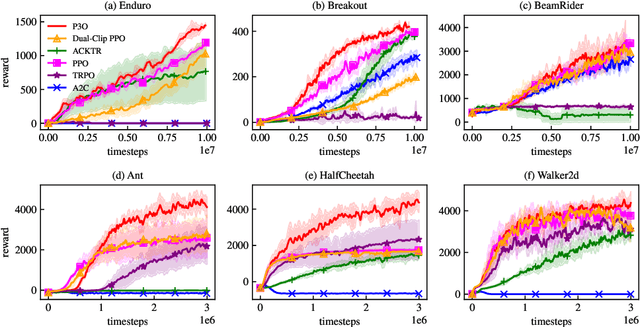

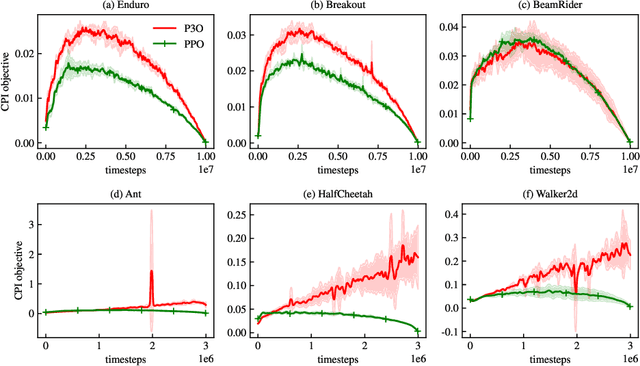
One of the major difficulties of reinforcement learning is learning from {\em off-policy} samples, which are collected by a different policy (behavior policy) from what the algorithm evaluates (the target policy). Off-policy learning needs to correct the distribution of the samples from the behavior policy towards that of the target policy. Unfortunately, important sampling has an inherent high variance issue which leads to poor gradient estimation in policy gradient methods. We focus on an off-policy Actor-Critic architecture, and propose a novel method, called Preconditioned Proximal Policy Optimization (P3O), which can control the high variance of importance sampling by applying a preconditioner to the Conservative Policy Iteration (CPI) objective. {\em This preconditioning uses the sigmoid function in a special way that when there is no policy change, the gradient is maximal and hence policy gradient will drive a big parameter update for an efficient exploration of the parameter space}. This is a novel exploration method that has not been studied before given that existing exploration methods are based on the novelty of states and actions. We compare with several best-performing algorithms on both discrete and continuous tasks and the results confirmed that {\em P3O is more off-policy than PPO} according to the "off-policyness" measured by the DEON metric, and P3O explores in a larger policy space than PPO. Results also show that our P3O maximizes the CPI objective better than PPO during the training process.
An Unsupervised Bayesian Neural Network for Truth Discovery
Jun 25, 2019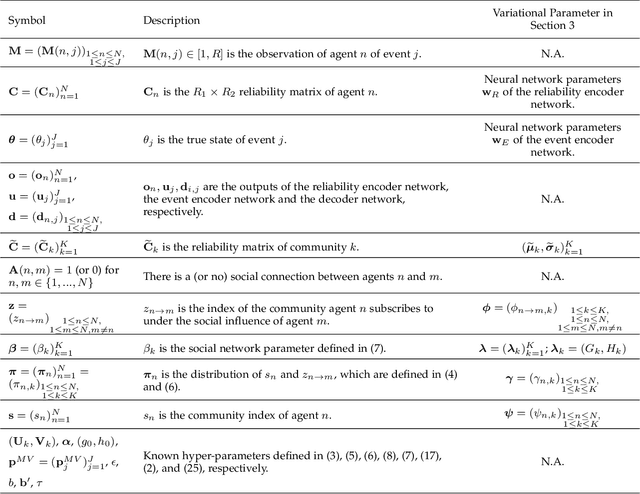
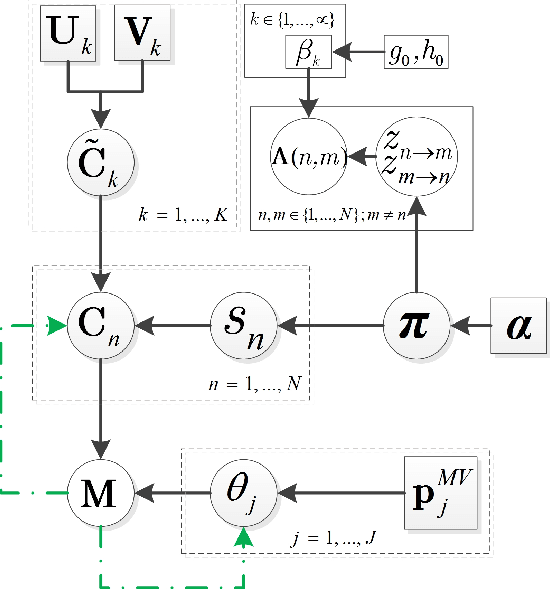
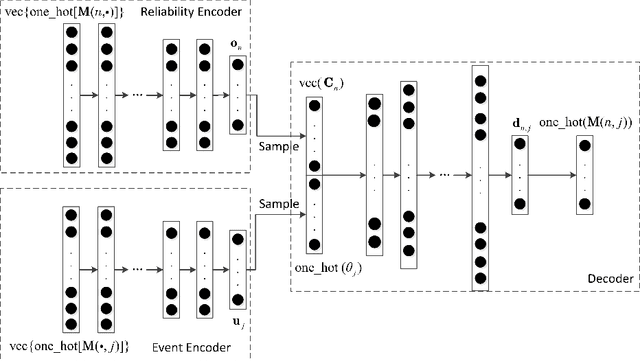
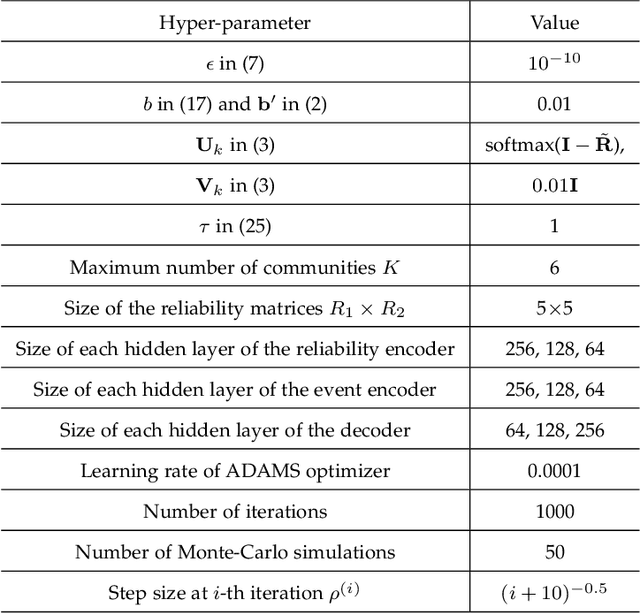
The problem of estimating event truths from conflicting agent opinions is investigated. An autoencoder learns the complex relationships between event truths, agent reliabilities and agent observations. A Bayesian network model is proposed to guide the learning of the autoencoder by modeling the dependence of agent reliabilities corresponding to different data samples. At the same time, it also models the social relationships between agents in the network. The proposed approach is unsupervised and is applicable when ground truth labels of events are unavailable. A variational inference method is used to jointly estimate the hidden variables in the Bayesian network and the parameters in the autoencoder. Simulations and experiments on real data suggest that the proposed method performs better than several other inference methods, including majority voting, the Bayesian Classifier Combination (BCC) method, the Community BCC method, and the recently proposed VISIT method.