 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniArray: Unified Spectral-Spatial Modeling for Array-Geometry-Agnostic Speech Separation
Mar 07, 2025

Array-geometry-agnostic speech separation (AGA-SS) aims to develop an effective separation method regardless of the microphone array geometry. Conventional methods rely on permutation-free operations, such as summation or attention mechanisms, to capture spatial information. However, these approaches often incur high computational costs or disrupt the effective use of spatial information during intra- and inter-channel interactions, leading to suboptimal performance. To address these issues, we propose UniArray, a novel approach that abandons the conventional interleaving manner. UniArray consists of three key components: a virtual microphone estimation (VME) module, a feature extraction and fusion module, and a hierarchical dual-path separator. The VME ensures robust performance across arrays with varying channel numbers. The feature extraction and fusion module leverages a spectral feature extraction module and a spatial dictionary learning (SDL) module to extract and fuse frequency-bin-level features, allowing the separator to focus on using the fused features. The hierarchical dual-path separator models feature dependencies along the time and frequency axes while maintaining computational efficiency. Experimental results show that UniArray outperforms state-of-the-art methods in SI-SDRi, WB-PESQ, NB-PESQ, and STOI across both seen and unseen array geometries.
Bridging Speech and Text: Enhancing ASR with Pinyin-to-Character Pre-training in LLMs
Sep 24, 2024The integration of large language models (LLMs) with pre-trained speech models has opened up new avenues in automatic speech recognition (ASR). While LLMs excel in multimodal understanding tasks, effectively leveraging their capabilities for ASR remains a significant challenge. This paper presents a novel training approach to enhance LLM performance in ASR tasks. We propose pre-training LLMs on Pinyin embedding sequences, which represent pronunciation features, to generate corresponding Chinese characters. This step enables the LLM to adapt to generating text from pronunciation features before encountering real speech data. Furthermore, we fine-tune the LoRA parameters to enhance the LLM's understanding of speech modality information. In AISHELL-1 corpus, our approach yields a 9.5% relative improvement in ASR tasks compared to the baseline without Pinyi-to-Character pre-training. Additionally, incorporating auxiliary text data for Pinyi-to-Character pre-training further boosts performance, achieving a 19.0% relative improvement.
Adapting OpenAI's Whisper for Speech Recognition on Code-Switch Mandarin-English SEAME and ASRU2019 Datasets
Nov 29, 2023

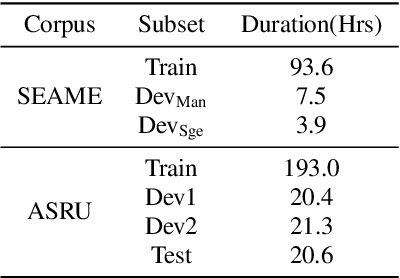

This paper details the experimental results of adapting the OpenAI's Whisper model for Code-Switch Mandarin-English Speech Recognition (ASR) on the SEAME and ASRU2019 corpora. We conducted 2 experiments: a) using adaptation data from 1 to 100/200 hours to demonstrate effectiveness of adaptation, b) examining different language ID setup on Whisper prompt. The Mixed Error Rate results show that the amount of adaptation data may be as low as $1\sim10$ hours to achieve saturation in performance gain (SEAME) while the ASRU task continued to show performance with more adaptation data ($>$100 hours). For the language prompt, the results show that although various prompting strategies initially produce different outcomes, adapting the Whisper model with code-switch data uniformly improves its performance. These results may be relevant also to the community when applying Whisper for related tasks of adapting to new target domains.
Distribution shift mitigation at test time with performance guarantees
Aug 18, 2023


Due to inappropriate sample selection and limited training data, a distribution shift often exists between the training and test sets. This shift can adversely affect the test performance of Graph Neural Networks (GNNs). Existing approaches mitigate this issue by either enhancing the robustness of GNNs to distribution shift or reducing the shift itself. However, both approaches necessitate retraining the model, which becomes unfeasible when the model structure and parameters are inaccessible. To address this challenge, we propose FR-GNN, a general framework for GNNs to conduct feature reconstruction. FRGNN constructs a mapping relationship between the output and input of a well-trained GNN to obtain class representative embeddings and then uses these embeddings to reconstruct the features of labeled nodes. These reconstructed features are then incorporated into the message passing mechanism of GNNs to influence the predictions of unlabeled nodes at test time. Notably, the reconstructed node features can be directly utilized for testing the well-trained model, effectively reducing the distribution shift and leading to improved test performance. This remarkable achievement is attained without any modifications to the model structure or parameters. We provide theoretical guarantees for the effectiveness of our framework. Furthermore, we conduct comprehensive experiments on various public datasets. The experimental results demonstrate the superior performance of FRGNN in comparison to mainstream methods.
Unifying Speech Enhancement and Separation with Gradient Modulation for End-to-End Noise-Robust Speech Separation
Feb 22, 2023



Recent studies in neural network-based monaural speech separation (SS) have achieved a remarkable success thanks to increasing ability of long sequence modeling. However, they would degrade significantly when put under realistic noisy conditions, as the background noise could be mistaken for speaker's speech and thus interfere with the separated sources. To alleviate this problem, we propose a novel network to unify speech enhancement and separation with gradient modulation to improve noise-robustness. Specifically, we first build a unified network by combining speech enhancement (SE) and separation modules, with multi-task learning for optimization, where SE is supervised by parallel clean mixture to reduce noise for downstream speech separation. Furthermore, in order to avoid suppressing valid speaker information when reducing noise, we propose a gradient modulation (GM) strategy to harmonize the SE and SS tasks from optimization view. Experimental results show that our approach achieves the state-of-the-art on large-scale Libri2Mix- and Libri3Mix-noisy datasets, with SI-SNRi results of 16.0 dB and 15.8 dB respectively. Our code is available at GitHub.
Uncertainty-Aware Model Adaptation for Unsupervised Cross-Domain Object Detection
Aug 28, 2021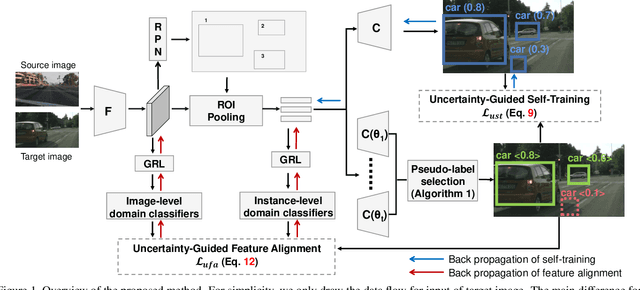
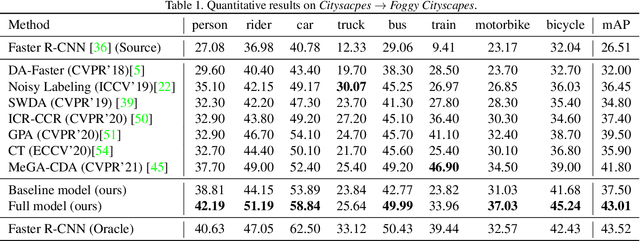
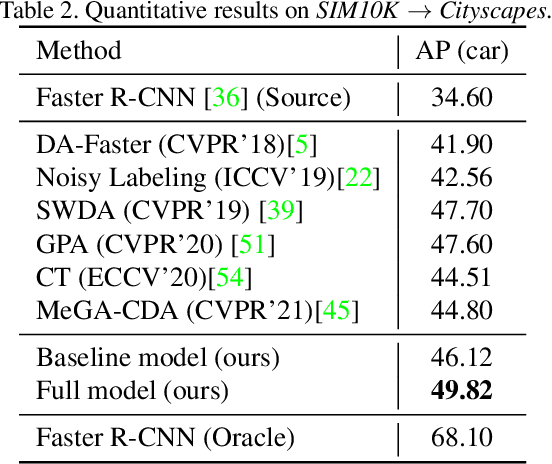
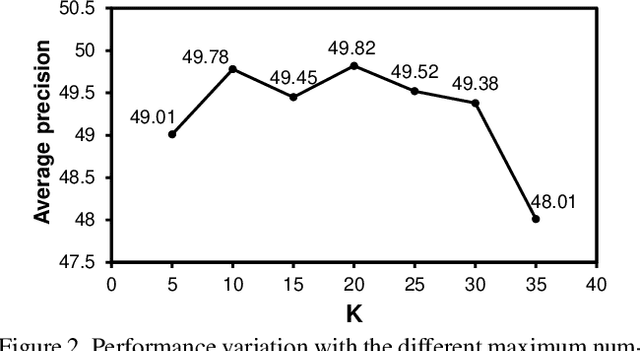
This work tackles the unsupervised cross-domain object detection problem which aims to generalize a pre-trained object detector to a new target domain without labels. We propose an uncertainty-aware model adaptation method, which is based on two motivations: 1) the estimation and exploitation of model uncertainty in a new domain is critical for reliable domain adaptation; and 2) the joint alignment of distributions for inputs (feature alignment) and outputs (self-training) is needed. To this end, we compose a Bayesian CNN-based framework for uncertainty estimation in object detection, and propose an algorithm for generation of uncertainty-aware pseudo-labels. We also devise a scheme for joint feature alignment and self-training of the object detection model with uncertainty-aware pseudo-labels. Experiments on multiple cross-domain object detection benchmarks show that our proposed method achieves state-of-the-art performance.