 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Code-Switching Speech Recognition with TTS Data Augmentation
Jan 02, 2026Automatic speech recognition (ASR) for conversational code-switching speech remains challenging due to the scarcity of realistic, high-quality labeled speech data. This paper explores multilingual text-to-speech (TTS) models as an effective data augmentation technique to address this shortage. Specifically, we fine-tune the multilingual CosyVoice2 TTS model on the SEAME dataset to generate synthetic conversational Chinese-English code-switching speech, significantly increasing the quantity and speaker diversity of available training data. Our experiments demonstrate that augmenting real speech with synthetic speech reduces the mixed error rate (MER) from 12.1 percent to 10.1 percent on DevMan and from 17.8 percent to 16.0 percent on DevSGE, indicating consistent performance gains. These results confirm that multilingual TTS is an effective and practical tool for enhancing ASR robustness in low-resource conversational code-switching scenarios.
POTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
Zero-shot Context Biasing with Trie-based Decoding using Synthetic Multi-Pronunciation
Aug 25, 2025Contextual automatic speech recognition (ASR) systems allow for recognizing out-of-vocabulary (OOV) words, such as named entities or rare words. However, it remains challenging due to limited training data and ambiguous or inconsistent pronunciations. In this paper, we propose a synthesis-driven multi-pronunciation contextual biasing method that performs zero-shot contextual ASR on a pretrained Whisper model. Specifically, we leverage text-to-speech (TTS) systems to synthesize diverse speech samples containing each target rare word, and then use the pretrained Whisper model to extract multiple predicted pronunciation variants. These variant token sequences are compiled into a prefix-trie, which assigns rewards to beam hypotheses in a shallow-fusion manner during beam-search decoding. After which, any recognized variant is mapped back to the original rare word in the final transcription. The evaluation results on the Librispeech dataset show that our method reduces biased word error rate (WER) by 42% on test-clean and 43% on test-other while maintaining unbiased WER essentially unchanged.
Bi-directional Context-Enhanced Speech Large Language Models for Multilingual Conversational ASR
Jun 16, 2025This paper introduces the integration of language-specific bi-directional context into a speech large language model (SLLM) to improve multilingual continuous conversational automatic speech recognition (ASR). We propose a character-level contextual masking strategy during training, which randomly removes portions of the context to enhance robustness and better emulate the flawed transcriptions that may occur during inference. For decoding, a two-stage pipeline is utilized: initial isolated segment decoding followed by context-aware re-decoding using neighboring hypotheses. Evaluated on the 1500-hour Multilingual Conversational Speech and Language Model (MLC-SLM) corpus covering eleven languages, our method achieves an 18% relative improvement compared to a strong baseline, outperforming even the model trained on 6000 hours of data for the MLC-SLM competition. These results underscore the significant benefit of incorporating contextual information in multilingual continuous conversational ASR.
NTU Speechlab LLM-Based Multilingual ASR System for Interspeech MLC-SLM Challenge 2025
Jun 16, 2025This report details the NTU Speechlab system developed for the Interspeech 2025 Multilingual Conversational Speech and Language Model (MLC-SLM) Challenge (Task I), where we achieved 5th place. We present comprehensive analyses of our multilingual automatic speech recognition system, highlighting key advancements in model architecture, data selection, and training strategies. In particular, language-specific prompts and model averaging techniques were instrumental in boosting system performance across diverse languages. Compared to the initial baseline system, our final model reduced the average Mix Error Rate from 20.2% to 10.6%, representing an absolute improvement of 9.6% (a relative improvement of 48%) on the evaluation set. Our results demonstrate the effectiveness of our approach and offer practical insights for future Speech Large Language Models.
ED-sKWS: Early-Decision Spiking Neural Networks for Rapid,and Energy-Efficient Keyword Spotting
Jun 14, 2024Keyword Spotting (KWS) is essential in edge computing requiring rapid and energy-efficient responses. Spiking Neural Networks (SNNs) are well-suited for KWS for their efficiency and temporal capacity for speech. To further reduce the latency and energy consumption, this study introduces ED-sKWS, an SNN-based KWS model with an early-decision mechanism that can stop speech processing and output the result before the end of speech utterance. Furthermore, we introduce a Cumulative Temporal (CT) loss that can enhance prediction accuracy at both the intermediate and final timesteps. To evaluate early-decision performance, we present the SC-100 dataset including 100 speech commands with beginning and end timestamp annotation. Experiments on the Google Speech Commands v2 and our SC-100 datasets show that ED-sKWS maintains competitive accuracy with 61% timesteps and 52% energy consumption compared to SNN models without early-decision mechanism, ensuring rapid response and energy efficiency.
The NUS-HLT System for ICASSP2024 ICMC-ASR Grand Challenge
Dec 26, 2023This paper summarizes our team's efforts in both tracks of the ICMC-ASR Challenge for in-car multi-channel automatic speech recognition. Our submitted systems for ICMC-ASR Challenge include the multi-channel front-end enhancement and diarization, training data augmentation, speech recognition modeling with multi-channel branches. Tested on the offical Eval1 and Eval2 set, our best system achieves a relative 34.3% improvement in CER and 56.5% improvement in cpCER, compared to the offical baseline system.
Adapting OpenAI's Whisper for Speech Recognition on Code-Switch Mandarin-English SEAME and ASRU2019 Datasets
Nov 29, 2023

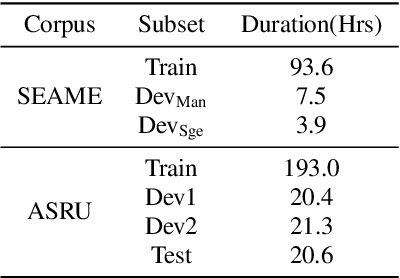

This paper details the experimental results of adapting the OpenAI's Whisper model for Code-Switch Mandarin-English Speech Recognition (ASR) on the SEAME and ASRU2019 corpora. We conducted 2 experiments: a) using adaptation data from 1 to 100/200 hours to demonstrate effectiveness of adaptation, b) examining different language ID setup on Whisper prompt. The Mixed Error Rate results show that the amount of adaptation data may be as low as $1\sim10$ hours to achieve saturation in performance gain (SEAME) while the ASRU task continued to show performance with more adaptation data ($>$100 hours). For the language prompt, the results show that although various prompting strategies initially produce different outcomes, adapting the Whisper model with code-switch data uniformly improves its performance. These results may be relevant also to the community when applying Whisper for related tasks of adapting to new target domains.
Mutual Information-Based Integrated Sensing and Communications: A WMMSE Framework
Oct 19, 2023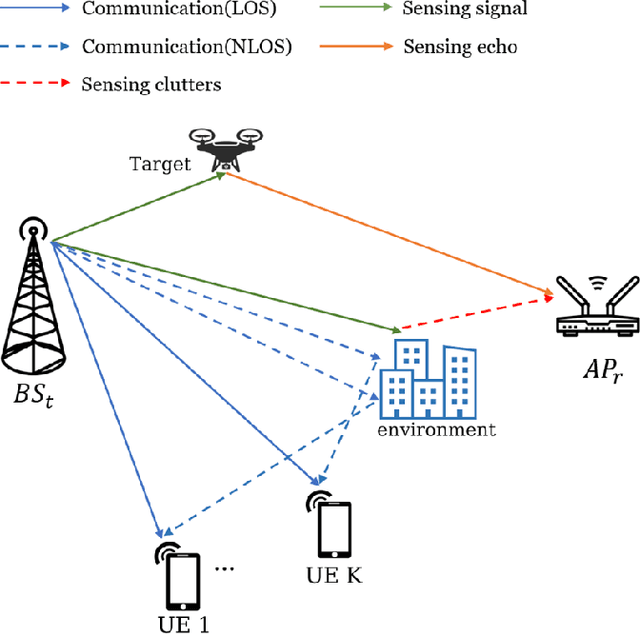
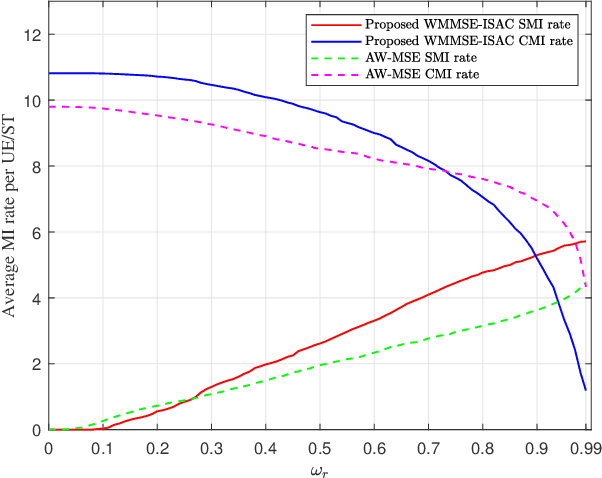
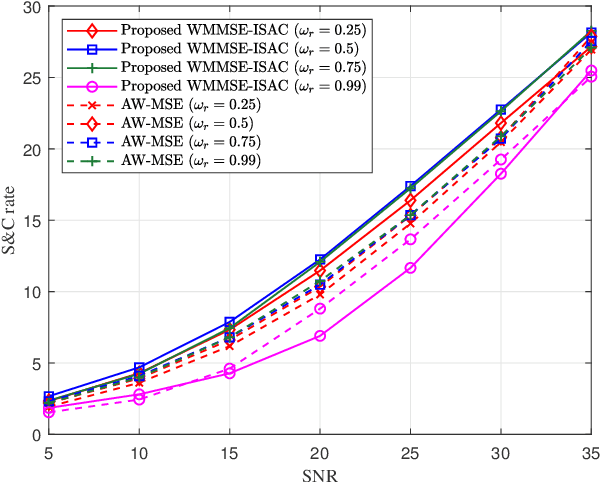
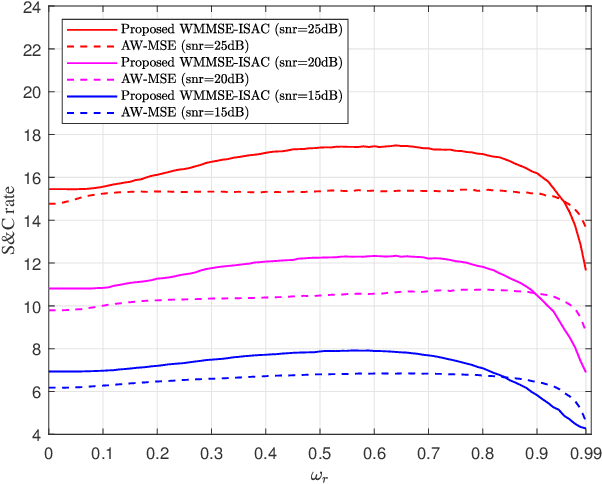
In this letter, a weighted minimum mean square error (WMMSE) empowered integrated sensing and communication (ISAC) system is investigated. One transmitting base station and one receiving wireless access point are considered to serve multiple users a sensing target. Based on the theory of mutual-information (MI), communication MI and sensing MI rate are utilized as the performance metrics under the presence of clutters. In particular, we propose an novel MI-based WMMSE-ISAC method by developing a unique transceiver design mechanism to maximize the weighted sensing and communication sum-rate of this system. Such a maximization process is achieved by utilizing the classical method -- WMMSE, aiming to better manage the effect of sensing clutters and the interference among users. Numerical results show the effectiveness of our proposed method, and the performance trade-off between sensing and communication is also validated.
Intermediate-layer output Regularization for Attention-based Speech Recognition with Shared Decoder
Jul 09, 2022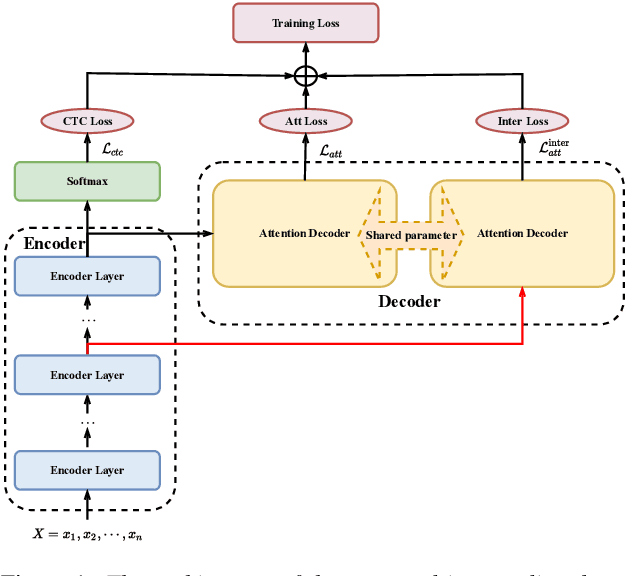
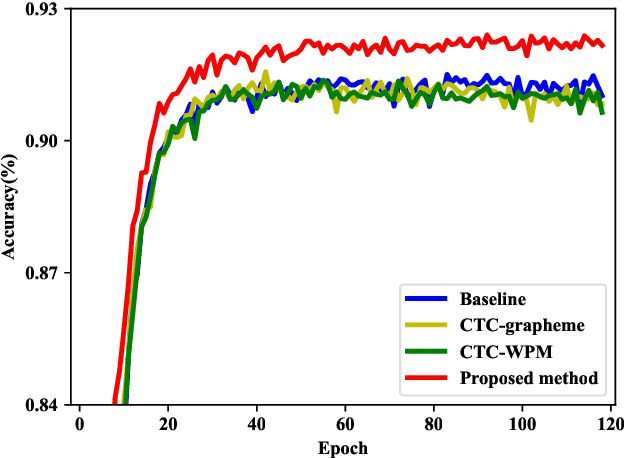
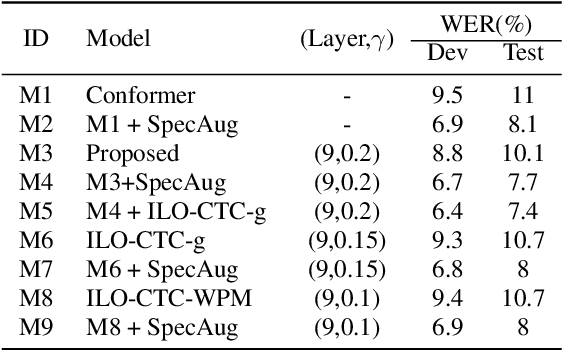
Intermediate layer output (ILO) regularization by means of multitask training on encoder side has been shown to be an effective approach to yielding improved results on a wide range of end-to-end ASR frameworks. In this paper, we propose a novel method to do ILO regularized training differently. Instead of using conventional multitask methods that entail more training overhead, we directly make the intermediate layer output as input to the decoder, that is, our decoder not only accepts the output of the final encoder layer as input, it also takes the output of the encoder ILO as input during training. With the proposed method, as both encoder and decoder are simultaneously "regularized", the network is more sufficiently trained, consistently leading to improved results, over the ILO-based CTC method, as well as over the original attention-based modeling method without the proposed method employed.