 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioRAG: A Challenging Benchmark for Audio Reasoning and Information Retrieval
Feb 11, 2026Due to recent advancements in Large Audio-Language Models (LALMs) that demonstrate remarkable performance across a range of sound-, speech- and music-related tasks, there is a growing interest in proposing benchmarks to assess these models. Existing benchmarks generally focus only on reasoning with internal knowledge, neglecting real-world scenarios that require external information grounding. To bridge this gap, we introduce AudioRAG, a novel benchmark designed to evaluate audio-based reasoning augmented by information retrieval in realistic web environments. This benchmark comprises both LLM-generated and manually curated question-answer pairs. Our evaluations reveal that even the state-of-the-art LALMs struggle to answer these questions. We therefore propose an agentic pipeline that integrates audio reasoning with retrieval-augmented generation, providing a stronger baseline for future research.
Interpolating Speaker Identities in Embedding Space for Data Expansion
Aug 26, 2025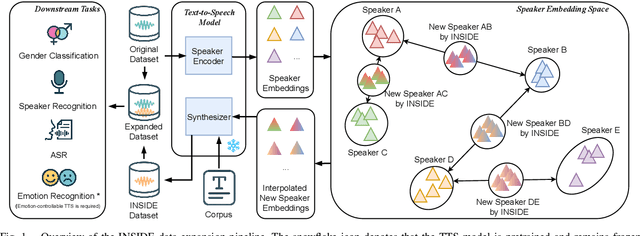
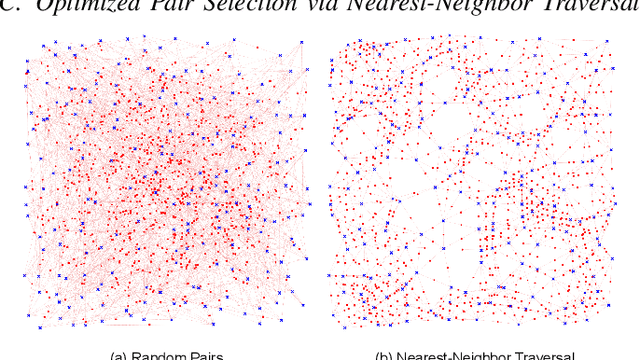
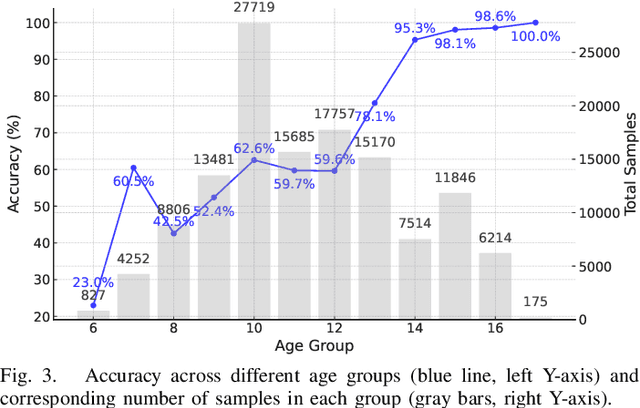
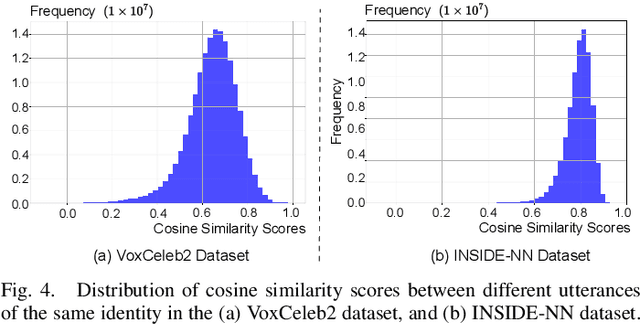
The success of deep learning-based speaker verification systems is largely attributed to access to large-scale and diverse speaker identity data. However, collecting data from more identities is expensive, challenging, and often limited by privacy concerns. To address this limitation, we propose INSIDE (Interpolating Speaker Identities in Embedding Space), a novel data expansion method that synthesizes new speaker identities by interpolating between existing speaker embeddings. Specifically, we select pairs of nearby speaker embeddings from a pretrained speaker embedding space and compute intermediate embeddings using spherical linear interpolation. These interpolated embeddings are then fed to a text-to-speech system to generate corresponding speech waveforms. The resulting data is combined with the original dataset to train downstream models. Experiments show that models trained with INSIDE-expanded data outperform those trained only on real data, achieving 3.06\% to 5.24\% relative improvements. While INSIDE is primarily designed for speaker verification, we also validate its effectiveness on gender classification, where it yields a 13.44\% relative improvement. Moreover, INSIDE is compatible with other augmentation techniques and can serve as a flexible, scalable addition to existing training pipelines.
Context-Aware Two-Step Training Scheme for Domain Invariant Speech Separation
Mar 16, 2025
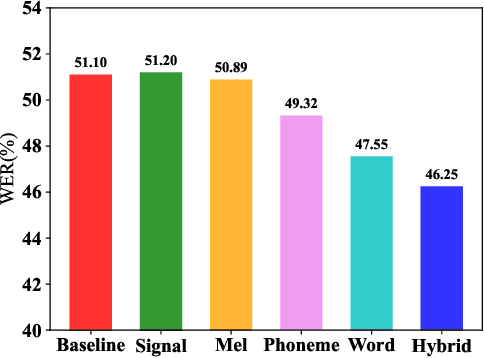


Speech separation seeks to isolate individual speech signals from a multi-talk speech mixture. Despite much progress, a system well-trained on synthetic data often experiences performance degradation on out-of-domain data, such as real-world speech mixtures. To address this, we introduce a novel context-aware, two-stage training scheme for speech separation models. In this training scheme, the conventional end-to-end architecture is replaced with a framework that contains a context extractor and a segregator. The two modules are trained step by step to simulate the speech separation process of an auditory system. We evaluate the proposed training scheme through cross-domain experiments on both synthetic and real-world speech mixtures, and demonstrate that our new scheme effectively boosts separation quality across different domains without adaptation, as measured by signal quality metrics and word error rate (WER). Additionally, an ablation study on the real test set highlights that the context information, including phoneme and word representations from pretrained SSL models, serves as effective domain invariant training targets for separation models.
SA-WavLM: Speaker-Aware Self-Supervised Pre-training for Mixture Speech
Jul 03, 2024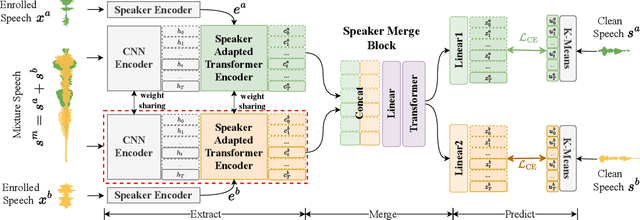
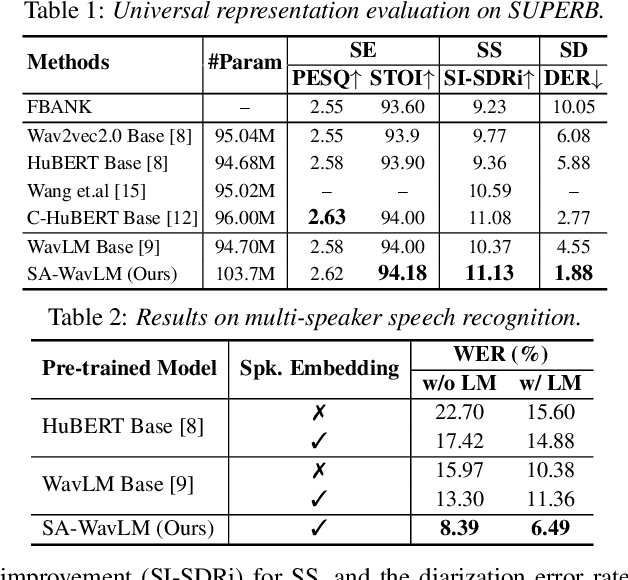
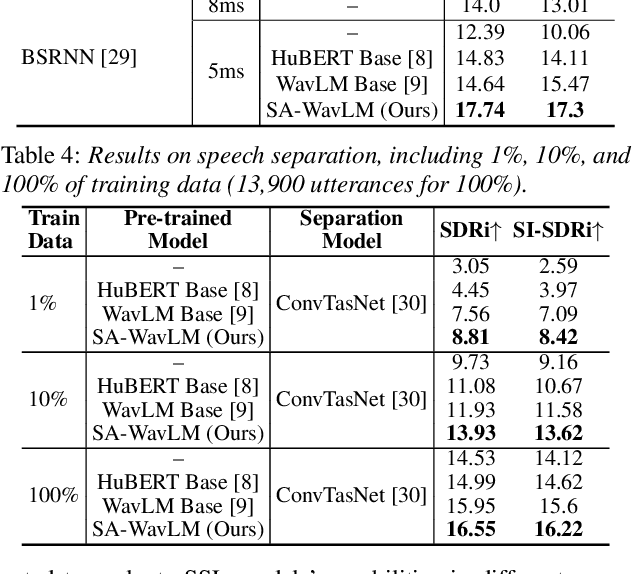
It was shown that pre-trained models with self-supervised learning (SSL) techniques are effective in various downstream speech tasks. However, most such models are trained on single-speaker speech data, limiting their effectiveness in mixture speech. This motivates us to explore pre-training on mixture speech. This work presents SA-WavLM, a novel pre-trained model for mixture speech. Specifically, SA-WavLM follows an "extract-merge-predict" pipeline in which the representations of each speaker in the input mixture are first extracted individually and then merged before the final prediction. In this pipeline, SA-WavLM performs speaker-informed extractions with the consideration of the interactions between different speakers. Furthermore, a speaker shuffling strategy is proposed to enhance the robustness towards the speaker absence. Experiments show that SA-WavLM either matches or improves upon the state-of-the-art pre-trained models.
The NUS-HLT System for ICASSP2024 ICMC-ASR Grand Challenge
Dec 26, 2023This paper summarizes our team's efforts in both tracks of the ICMC-ASR Challenge for in-car multi-channel automatic speech recognition. Our submitted systems for ICMC-ASR Challenge include the multi-channel front-end enhancement and diarization, training data augmentation, speech recognition modeling with multi-channel branches. Tested on the offical Eval1 and Eval2 set, our best system achieves a relative 34.3% improvement in CER and 56.5% improvement in cpCER, compared to the offical baseline system.
Selective HuBERT: Self-Supervised Pre-Training for Target Speaker in Clean and Mixture Speech
Nov 08, 2023Self-supervised pre-trained speech models were shown effective for various downstream speech processing tasks. Since they are mainly pre-trained to map input speech to pseudo-labels, the resulting representations are only effective for the type of pre-train data used, either clean or mixture speech. With the idea of selective auditory attention, we propose a novel pre-training solution called Selective-HuBERT, or SHuBERT, which learns the selective extraction of target speech representations from either clean or mixture speech. Specifically, SHuBERT is trained to predict pseudo labels of a target speaker, conditioned on an enrolled speech from the target speaker. By doing so, SHuBERT is expected to selectively attend to the target speaker in a complex acoustic environment, thus benefiting various downstream tasks. We further introduce a dual-path training strategy and use the cross-correlation constraint between the two branches to encourage the model to generate noise-invariant representation. Experiments on SUPERB benchmark and LibriMix dataset demonstrate the universality and noise-robustness of SHuBERT. Furthermore, we find that our high-quality representation can be easily integrated with conventional supervised learning methods to achieve significant performance, even under extremely low-resource labeled data.
Self-Supervised Acoustic Word Embedding Learning via Correspondence Transformer Encoder
Jul 19, 2023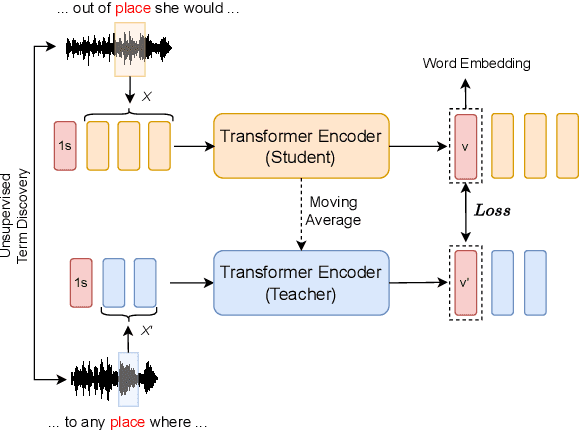
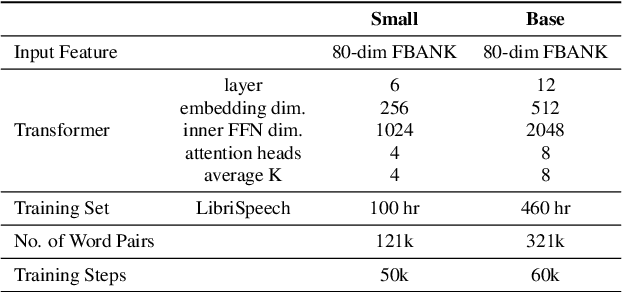
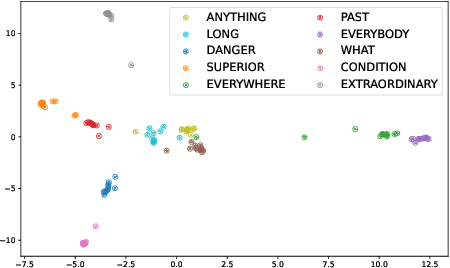
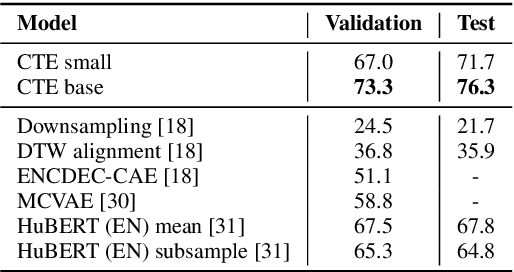
Acoustic word embeddings (AWEs) aims to map a variable-length speech segment into a fixed-dimensional representation. High-quality AWEs should be invariant to variations, such as duration, pitch and speaker. In this paper, we introduce a novel self-supervised method to learn robust AWEs from a large-scale unlabelled speech corpus. Our model, named Correspondence Transformer Encoder (CTE), employs a teacher-student learning framework. We train the model based on the idea that different realisations of the same word should be close in the underlying embedding space. Specifically, we feed the teacher and student encoder with different acoustic instances of the same word and pre-train the model with a word-level loss. Our experiments show that the embeddings extracted from the proposed CTE model are robust to speech variations, e.g. speakers and domains. Additionally, when evaluated on Xitsonga, a low-resource cross-lingual setting, the CTE model achieves new state-of-the-art performance.