 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Acoustic Word Embedding Learning via Correspondence Transformer Encoder
Paper and Code
Jul 19, 2023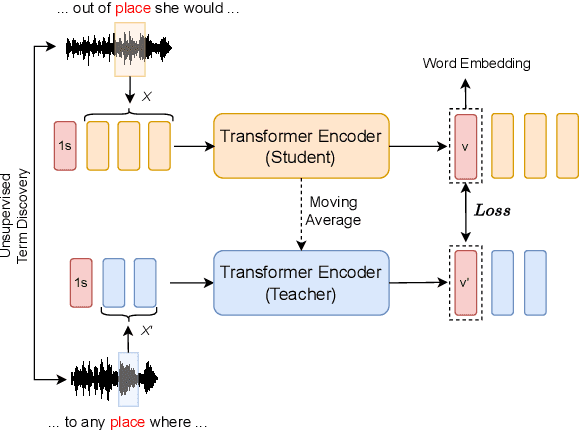
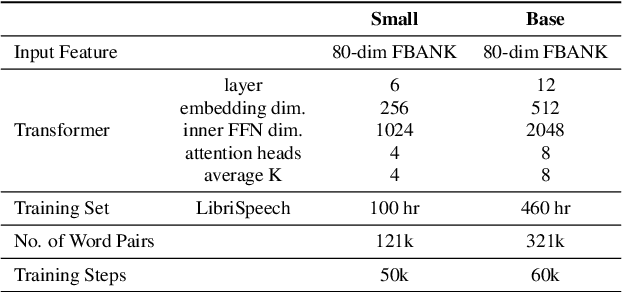
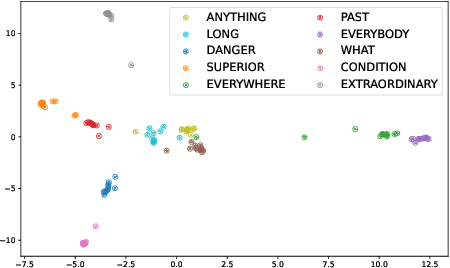
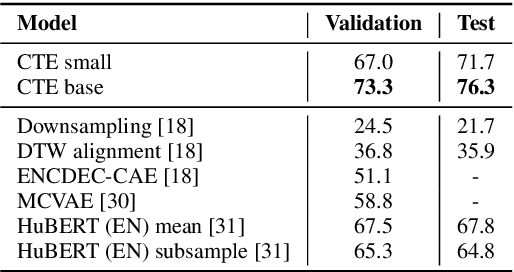
Acoustic word embeddings (AWEs) aims to map a variable-length speech segment into a fixed-dimensional representation. High-quality AWEs should be invariant to variations, such as duration, pitch and speaker. In this paper, we introduce a novel self-supervised method to learn robust AWEs from a large-scale unlabelled speech corpus. Our model, named Correspondence Transformer Encoder (CTE), employs a teacher-student learning framework. We train the model based on the idea that different realisations of the same word should be close in the underlying embedding space. Specifically, we feed the teacher and student encoder with different acoustic instances of the same word and pre-train the model with a word-level loss. Our experiments show that the embeddings extracted from the proposed CTE model are robust to speech variations, e.g. speakers and domains. Additionally, when evaluated on Xitsonga, a low-resource cross-lingual setting, the CTE model achieves new state-of-the-art performance.