 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluAudio: A Comprehensive Benchmark for Hallucination Detection in Large Audio-Language Models
Apr 21, 2026Large Audio-Language Models (LALMs) have recently achieved strong performance across various audio-centric tasks. However, hallucination, where models generate responses that are semantically incorrect or acoustically unsupported, remains largely underexplored in the audio domain. Existing hallucination benchmarks mainly focus on text or vision, while the few audio-oriented studies are limited in scale, modality coverage, and diagnostic depth. We therefore introduce HalluAudio, the first large-scale benchmark for evaluating hallucinations across speech, environmental sound, and music. HalluAudio comprises over 5K human-verified QA pairs and spans diverse task types, including binary judgments, multi-choice reasoning, attribute verification, and open-ended QA. To systematically induce hallucinations, we design adversarial prompts and mixed-audio conditions. Beyond accuracy, our evaluation protocol measures hallucination rate, yes/no bias, error-type analysis, and refusal rate, enabling a fine-grained analysis of LALM failure modes. We benchmark a broad range of open-source and proprietary models, providing the first large-scale comparison across speech, sound, and music. Our results reveal significant deficiencies in acoustic grounding, temporal reasoning, and music attribute understanding, underscoring the need for reliable and robust LALMs.
Whisper-MLA: Reducing GPU Memory Consumption of ASR Models based on MHA2MLA Conversion
Feb 28, 2026The Transformer-based Whisper model has achieved state-of-the-art performance in Automatic Speech Recognition (ASR). However, its Multi-Head Attention (MHA) mechanism results in significant GPU memory consumption due to the linearly growing Key-Value (KV) cache usage, which is problematic for many applications especially with long-form audio. To address this, we introduce Whisper-MLA, a novel architecture that incorporates Multi-Head Latent Attention (MLA) into the Whisper model. Specifically, we adapt MLA for Whisper's absolute positional embeddings and systematically investigate its application across encoder self-attention, decoder self-attention, and cross-attention modules. Empirical results indicate that applying MLA exclusively to decoder self-attention yields the desired balance between performance and memory efficiency. Our proposed approach allows conversion of a pretrained Whisper model to Whisper-MLA with minimal fine-tuning. Extensive experiments on the LibriSpeech benchmark validate the effectiveness of this conversion, demonstrating that Whisper-MLA reduces the KV cache size by up to 87.5% while maintaining competitive accuracy.
Listening for "You": Enhancing Speech Image Retrieval via Target Speaker Extraction
Sep 11, 2025Image retrieval using spoken language cues has emerged as a promising direction in multimodal perception, yet leveraging speech in multi-speaker scenarios remains challenging. We propose a novel Target Speaker Speech-Image Retrieval task and a framework that learns the relationship between images and multi-speaker speech signals in the presence of a target speaker. Our method integrates pre-trained self-supervised audio encoders with vision models via target speaker-aware contrastive learning, conditioned on a Target Speaker Extraction and Retrieval module. This enables the system to extract spoken commands from the target speaker and align them with corresponding images. Experiments on SpokenCOCO2Mix and SpokenCOCO3Mix show that TSRE significantly outperforms existing methods, achieving 36.3% and 29.9% Recall@1 in 2 and 3 speaker scenarios, respectively - substantial improvements over single speaker baselines and state-of-the-art models. Our approach demonstrates potential for real-world deployment in assistive robotics and multimodal interaction systems.
Audio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture
Apr 21, 2025



Fish Feeding Intensity Assessment (FFIA) is crucial in industrial aquaculture management. Recent multi-modal approaches have shown promise in improving FFIA robustness and efficiency. However, these methods face significant challenges when adapting to new fish species or environments due to catastrophic forgetting and the lack of suitable datasets. To address these limitations, we first introduce AV-CIL-FFIA, a new dataset comprising 81,932 labelled audio-visual clips capturing feeding intensities across six different fish species in real aquaculture environments. Then, we pioneer audio-visual class incremental learning (CIL) for FFIA and demonstrate through benchmarking on AV-CIL-FFIA that it significantly outperforms single-modality methods. Existing CIL methods rely heavily on historical data. Exemplar-based approaches store raw samples, creating storage challenges, while exemplar-free methods avoid data storage but struggle to distinguish subtle feeding intensity variations across different fish species. To overcome these limitations, we introduce HAIL-FFIA, a novel audio-visual class-incremental learning framework that bridges this gap with a prototype-based approach that achieves exemplar-free efficiency while preserving essential knowledge through compact feature representations. Specifically, HAIL-FFIA employs hierarchical representation learning with a dual-path knowledge preservation mechanism that separates general intensity knowledge from fish-specific characteristics. Additionally, it features a dynamic modality balancing system that adaptively adjusts the importance of audio versus visual information based on feeding behaviour stages. Experimental results show that HAIL-FFIA is superior to SOTA methods on AV-CIL-FFIA, achieving higher accuracy with lower storage needs while effectively mitigating catastrophic forgetting in incremental fish species learning.
UniCodec: Unified Audio Codec with Single Domain-Adaptive Codebook
Feb 27, 2025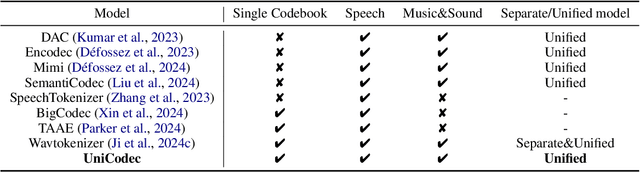

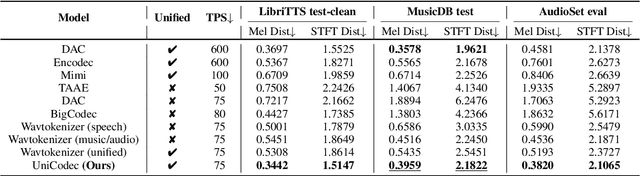
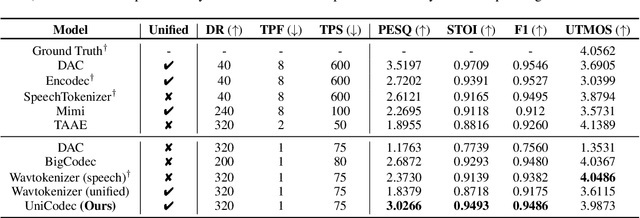
The emergence of audio language models is empowered by neural audio codecs, which establish critical mappings between continuous waveforms and discrete tokens compatible with language model paradigms. The evolutionary trends from multi-layer residual vector quantizer to single-layer quantizer are beneficial for language-autoregressive decoding. However, the capability to handle multi-domain audio signals through a single codebook remains constrained by inter-domain distribution discrepancies. In this work, we introduce UniCodec, a unified audio codec with a single codebook to support multi-domain audio data, including speech, music, and sound. To achieve this, we propose a partitioned domain-adaptive codebook method and domain Mixture-of-Experts strategy to capture the distinct characteristics of each audio domain. Furthermore, to enrich the semantic density of the codec without auxiliary modules, we propose a self-supervised mask prediction modeling approach. Comprehensive objective and subjective evaluations demonstrate that UniCodec achieves excellent audio reconstruction performance across the three audio domains, outperforming existing unified neural codecs with a single codebook, and even surpasses state-of-the-art domain-specific codecs on both acoustic and semantic representation capabilities.
PAL: Prompting Analytic Learning with Missing Modality for Multi-Modal Class-Incremental Learning
Jan 16, 2025Multi-modal class-incremental learning (MMCIL) seeks to leverage multi-modal data, such as audio-visual and image-text pairs, thereby enabling models to learn continuously across a sequence of tasks while mitigating forgetting. While existing studies primarily focus on the integration and utilization of multi-modal information for MMCIL, a critical challenge remains: the issue of missing modalities during incremental learning phases. This oversight can exacerbate severe forgetting and significantly impair model performance. To bridge this gap, we propose PAL, a novel exemplar-free framework tailored to MMCIL under missing-modality scenarios. Concretely, we devise modality-specific prompts to compensate for missing information, facilitating the model to maintain a holistic representation of the data. On this foundation, we reformulate the MMCIL problem into a Recursive Least-Squares task, delivering an analytical linear solution. Building upon these, PAL not only alleviates the inherent under-fitting limitation in analytic learning but also preserves the holistic representation of missing-modality data, achieving superior performance with less forgetting across various multi-modal incremental scenarios. Extensive experiments demonstrate that PAL significantly outperforms competitive methods across various datasets, including UPMC-Food101 and N24News, showcasing its robustness towards modality absence and its anti-forgetting ability to maintain high incremental accuracy.
VoiceBench: Benchmarking LLM-Based Voice Assistants
Oct 22, 2024
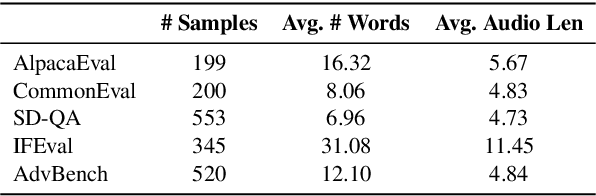

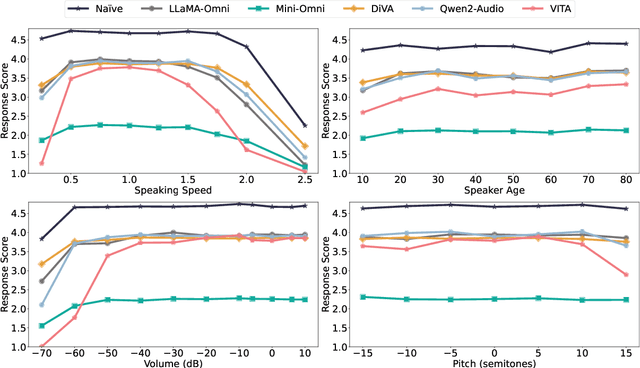
Building on the success of large language models (LLMs), recent advancements such as GPT-4o have enabled real-time speech interactions through LLM-based voice assistants, offering a significantly improved user experience compared to traditional text-based interactions. However, the absence of benchmarks designed to evaluate these speech interaction capabilities has hindered progress of LLM-based voice assistants development. Current evaluations focus primarily on automatic speech recognition (ASR) or general knowledge evaluation with clean speeches, neglecting the more intricate, real-world scenarios that involve diverse speaker characteristics, environmental and content factors. To address this, we introduce VoiceBench, the first benchmark designed to provide a multi-faceted evaluation of LLM-based voice assistants. VoiceBench also includes both real and synthetic spoken instructions that incorporate the above three key real-world variations. Extensive experiments reveal the limitations of current LLM-based voice assistant models and offer valuable insights for future research and development in this field.
Beyond Single-Audio: Advancing Multi-Audio Processing in Audio Large Language Models
Sep 27, 2024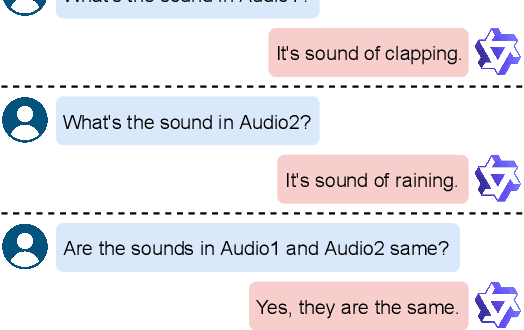
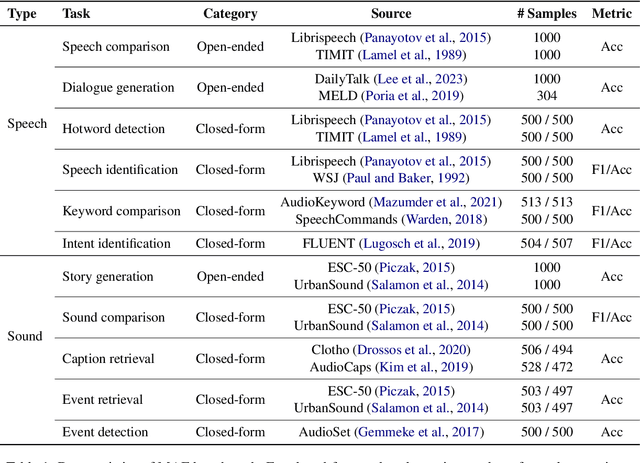
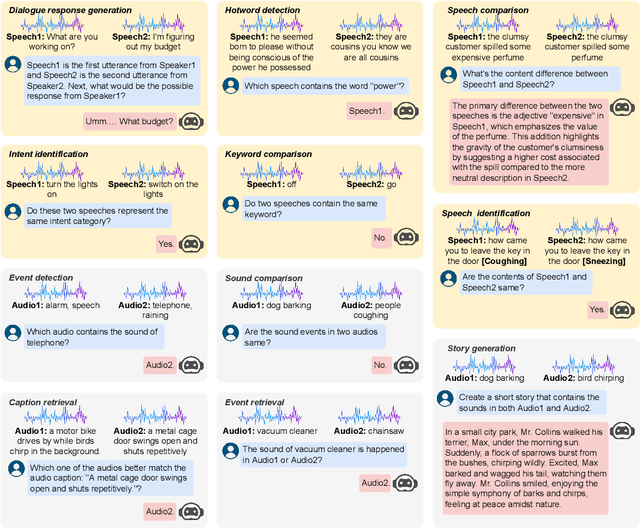
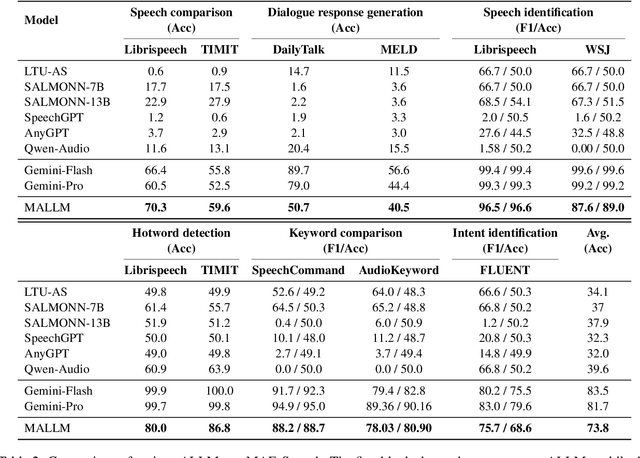
Various audio-LLMs (ALLMs) have been explored recently for tackling different audio tasks simultaneously using a single, unified model. While existing evaluations of ALLMs primarily focus on single-audio tasks, real-world applications often involve processing multiple audio streams simultaneously. To bridge this gap, we propose the first multi-audio evaluation (MAE) benchmark that consists of 20 datasets from 11 multi-audio tasks encompassing both speech and sound scenarios. Comprehensive experiments on MAE demonstrate that the existing ALLMs, while being powerful in comprehending primary audio elements in individual audio inputs, struggling to handle multi-audio scenarios. To this end, we propose a novel multi-audio-LLM (MALLM) to capture audio context among multiple similar audios using discriminative learning on our proposed synthetic data. The results demonstrate that the proposed MALLM outperforms all baselines and achieves high data efficiency using synthetic data without requiring human annotations. The proposed MALLM opens the door for ALLMs towards multi-audio processing era and brings us closer to replicating human auditory capabilities in machines.
Analytic Class Incremental Learning for Sound Source Localization with Privacy Protection
Sep 11, 2024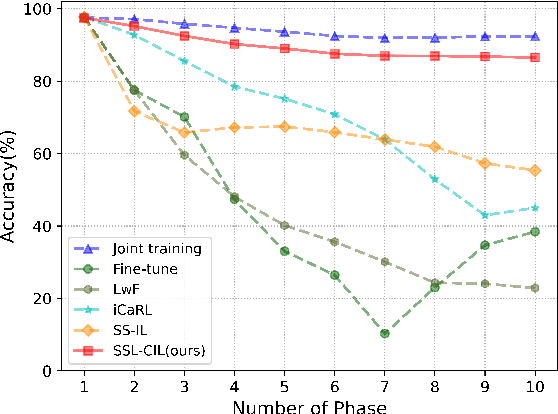
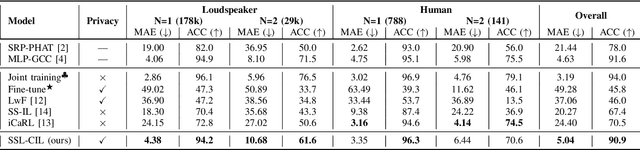

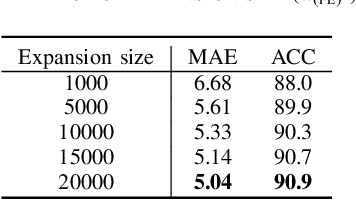
Sound Source Localization (SSL) enabling technology for applications such as surveillance and robotics. While traditional Signal Processing (SP)-based SSL methods provide analytic solutions under specific signal and noise assumptions, recent Deep Learning (DL)-based methods have significantly outperformed them. However, their success depends on extensive training data and substantial computational resources. Moreover, they often rely on large-scale annotated spatial data and may struggle when adapting to evolving sound classes. To mitigate these challenges, we propose a novel Class Incremental Learning (CIL) approach, termed SSL-CIL, which avoids serious accuracy degradation due to catastrophic forgetting by incrementally updating the DL-based SSL model through a closed-form analytic solution. In particular, data privacy is ensured since the learning process does not revisit any historical data (exemplar-free), which is more suitable for smart home scenarios. Empirical results in the public SSLR dataset demonstrate the superior performance of our proposal, achieving a localization accuracy of 90.9%, surpassing other competitive methods.
TTSlow: Slow Down Text-to-Speech with Efficiency Robustness Evaluations
Jul 02, 2024



Text-to-speech (TTS) has been extensively studied for generating high-quality speech with textual inputs, playing a crucial role in various real-time applications. For real-world deployment, ensuring stable and timely generation in TTS models against minor input perturbations is of paramount importance. Therefore, evaluating the robustness of TTS models against such perturbations, commonly known as adversarial attacks, is highly desirable. In this paper, we propose TTSlow, a novel adversarial approach specifically tailored to slow down the speech generation process in TTS systems. To induce long TTS waiting time, we design novel efficiency-oriented adversarial loss to encourage endless generation process. TTSlow encompasses two attack strategies targeting both text inputs and speaker embedding. Specifically, we propose TTSlow-text, which utilizes a combination of homoglyphs-based and swap-based perturbations, along with TTSlow-spk, which employs a gradient optimization attack approach for speaker embedding. TTSlow serves as the first attack approach targeting a wide range of TTS models, including autoregressive and non-autoregressive TTS ones, thereby advancing exploration in audio security. Extensive experiments are conducted to evaluate the inference efficiency of TTS models, and in-depth analysis of generated speech intelligibility is performed using Gemini. The results demonstrate that TTSlow can effectively slow down two TTS models across three publicly available datasets. We are committed to releasing the source code upon acceptance, facilitating further research and benchmarking in this domain.