 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Speech Representation Better Matches Text-Native Reasoning? A Study of Speech-Text Alignment on Frame Rate and Representation
Jun 10, 2026Spoken dialogue models typically start from text LLM backbones, yet reasoning often degrades when conditioning on speech instead of text. We attribute part of this modality gap to a temporal-granularity mismatch: speech tokens are temporally redundant and far longer than text under matched semantics, diluting per-token semantic density and weakening text-native reasoning dynamics. We study speech token design as a representation selection problem and sweep frame rates under a frozen LLM backbone with a fixed information rate. To make low frame rates feasible, we introduce factorized FSQ and a lightweight non-autoregressive audio LM head, scaling capacity to nearly 300\,bits/frame without sacrificing efficient prediction. With the bottleneck removed, we sweep frame rates (50$\rightarrow$2.08\,Hz) and alignment depth, and observe a consistent best regime for speech QA at 4.17\,Hz with intermediate-layer representation alignment.
EmoOmni: Bridging Emotional Understanding and Expression in Omni-Modal LLMs
Feb 25, 2026The evolution of Omni-Modal Large Language Models~(Omni-LLMs) has revolutionized human--computer interaction, enabling unified audio-visual perception and speech response. However, existing Omni-LLMs struggle with complex real-world scenarios, often leading to superficial understanding and contextually mismatched emotional responses. This issue is further intensified by Omni-LLM's Thinker-Talker architectures, which are implicitly connected through hidden states, leading to the loss of emotional details. In this work, we present EmoOmni, a unified framework for accurate understanding and expression in multimodal emotional dialogue. At its core, we introduce the emotional Chain-of-Thought~(E-CoT), which enforces a reasoning from fine-grained multimodal perception to textual response. Moreover, we explicitly treat E-CoT as high-level emotional instructions that guide the talker, enabling accurate emotional expression. Complementing the model, we construct EmoOmniPipe to obtain the real-world annotated dialogue data and establish a benchmark, EmoOmniEval, to facilitate systematic assessment of multimodal emotional dialogue task. Experiments show that EmoOmni-7B achieves comparable performance with Qwen3Omni-30B-A3B-Thinking under the same talker.
SLAP: Scalable Language-Audio Pretraining with Variable-Duration Audio and Multi-Objective Training
Jan 18, 2026Contrastive language-audio pretraining (CLAP) has achieved notable success in learning semantically rich audio representations and is widely adopted for various audio-related tasks. However, current CLAP models face several key limitations. First, they are typically trained on relatively small datasets, often comprising a few million audio samples. Second, existing CLAP models are restricted to short and fixed duration, which constrains their usage in real-world scenarios with variable-duration audio. Third, the standard contrastive training objective operates on global representations, which may hinder the learning of dense, fine-grained audio features. To address these challenges, we introduce Scalable Language-Audio Pretraining (SLAP), which scales language-audio pretraining to 109 million audio-text pairs with variable audio durations and incorporates multiple training objectives. SLAP unifies contrastive loss with additional self-supervised and captioning losses in a single-stage training, facilitating the learning of richer dense audio representations. The proposed SLAP model achieves new state-of-the-art performance on audio-text retrieval and zero-shot audio classification tasks, demonstrating its effectiveness across diverse benchmarks.
Region-Specific Audio Tagging for Spatial Sound
Sep 11, 2025Audio tagging aims to label sound events appearing in an audio recording. In this paper, we propose region-specific audio tagging, a new task which labels sound events in a given region for spatial audio recorded by a microphone array. The region can be specified as an angular space or a distance from the microphone. We first study the performance of different combinations of spectral, spatial, and position features. Then we extend state-of-the-art audio tagging systems such as pre-trained audio neural networks (PANNs) and audio spectrogram transformer (AST) to the proposed region-specific audio tagging task. Experimental results on both the simulated and the real datasets show the feasibility of the proposed task and the effectiveness of the proposed method. Further experiments show that incorporating the directional features is beneficial for omnidirectional tagging.
AudioTurbo: Fast Text-to-Audio Generation with Rectified Diffusion
May 28, 2025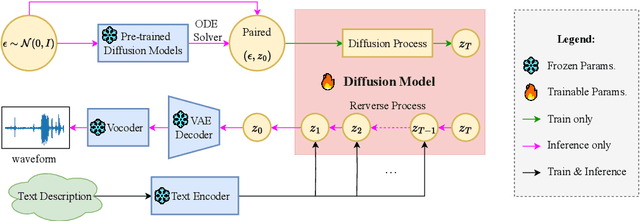
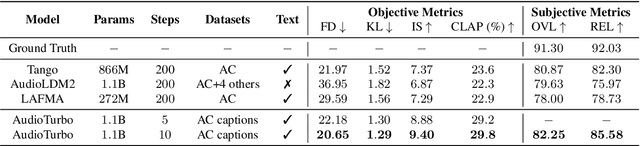
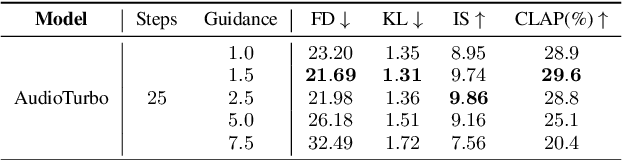
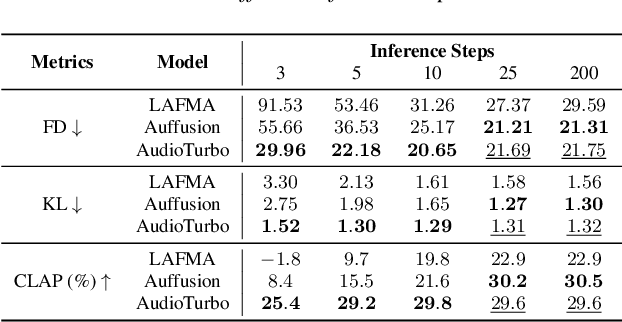
Diffusion models have significantly improved the quality and diversity of audio generation but are hindered by slow inference speed. Rectified flow enhances inference speed by learning straight-line ordinary differential equation (ODE) paths. However, this approach requires training a flow-matching model from scratch and tends to perform suboptimally, or even poorly, at low step counts. To address the limitations of rectified flow while leveraging the advantages of advanced pre-trained diffusion models, this study integrates pre-trained models with the rectified diffusion method to improve the efficiency of text-to-audio (TTA) generation. Specifically, we propose AudioTurbo, which learns first-order ODE paths from deterministic noise sample pairs generated by a pre-trained TTA model. Experiments on the AudioCaps dataset demonstrate that our model, with only 10 sampling steps, outperforms prior models and reduces inference to 3 steps compared to a flow-matching-based acceleration model.
EnvSDD: Benchmarking Environmental Sound Deepfake Detection
May 25, 2025Audio generation systems now create very realistic soundscapes that can enhance media production, but also pose potential risks. Several studies have examined deepfakes in speech or singing voice. However, environmental sounds have different characteristics, which may make methods for detecting speech and singing deepfakes less effective for real-world sounds. In addition, existing datasets for environmental sound deepfake detection are limited in scale and audio types. To address this gap, we introduce EnvSDD, the first large-scale curated dataset designed for this task, consisting of 45.25 hours of real and 316.74 hours of fake audio. The test set includes diverse conditions to evaluate the generalizability, such as unseen generation models and unseen datasets. We also propose an audio deepfake detection system, based on a pre-trained audio foundation model. Results on EnvSDD show that our proposed system outperforms the state-of-the-art systems from speech and singing domains.
SongEval: A Benchmark Dataset for Song Aesthetics Evaluation
May 16, 2025Aesthetics serve as an implicit and important criterion in song generation tasks that reflect human perception beyond objective metrics. However, evaluating the aesthetics of generated songs remains a fundamental challenge, as the appreciation of music is highly subjective. Existing evaluation metrics, such as embedding-based distances, are limited in reflecting the subjective and perceptual aspects that define musical appeal. To address this issue, we introduce SongEval, the first open-source, large-scale benchmark dataset for evaluating the aesthetics of full-length songs. SongEval includes over 2,399 songs in full length, summing up to more than 140 hours, with aesthetic ratings from 16 professional annotators with musical backgrounds. Each song is evaluated across five key dimensions: overall coherence, memorability, naturalness of vocal breathing and phrasing, clarity of song structure, and overall musicality. The dataset covers both English and Chinese songs, spanning nine mainstream genres. Moreover, to assess the effectiveness of song aesthetic evaluation, we conduct experiments using SongEval to predict aesthetic scores and demonstrate better performance than existing objective evaluation metrics in predicting human-perceived musical quality.
Exploring the User Experience of AI-Assisted Sound Searching Systems for Creative Workflows
Apr 22, 2025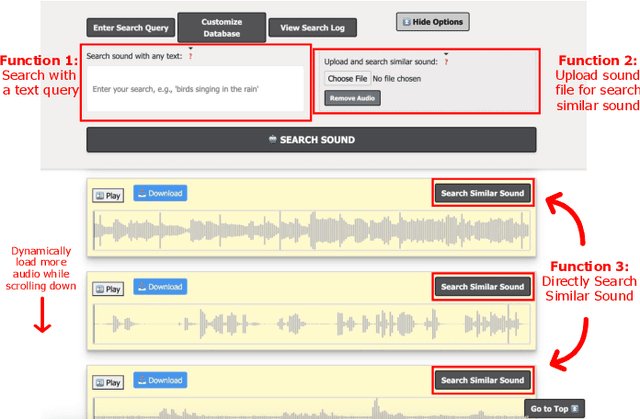
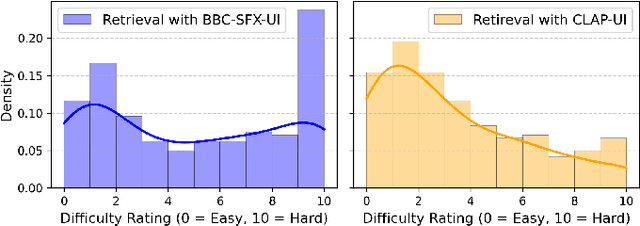
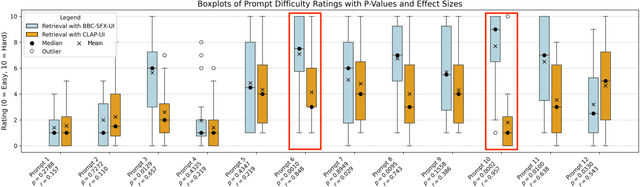
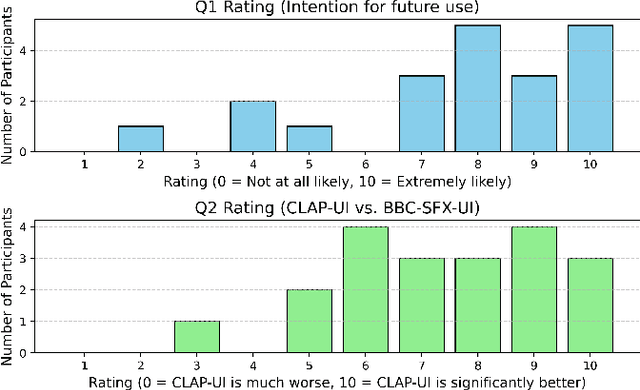
Locating the right sound effect efficiently is an important yet challenging topic for audio production. Most current sound-searching systems rely on pre-annotated audio labels created by humans, which can be time-consuming to produce and prone to inaccuracies, limiting the efficiency of audio production. Following the recent advancement of contrastive language-audio pre-training (CLAP) models, we explore an alternative CLAP-based sound-searching system (CLAP-UI) that does not rely on human annotations. To evaluate the effectiveness of CLAP-UI, we conducted comparative experiments with a widely used sound effect searching platform, the BBC Sound Effect Library. Our study evaluates user performance, cognitive load, and satisfaction through ecologically valid tasks based on professional sound-searching workflows. Our result shows that CLAP-UI demonstrated significantly enhanced productivity and reduced frustration while maintaining comparable cognitive demands. We also qualitatively analyzed the participants' feedback, which offered valuable perspectives on the design of future AI-assisted sound search systems.
Audio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture
Apr 21, 2025



Fish Feeding Intensity Assessment (FFIA) is crucial in industrial aquaculture management. Recent multi-modal approaches have shown promise in improving FFIA robustness and efficiency. However, these methods face significant challenges when adapting to new fish species or environments due to catastrophic forgetting and the lack of suitable datasets. To address these limitations, we first introduce AV-CIL-FFIA, a new dataset comprising 81,932 labelled audio-visual clips capturing feeding intensities across six different fish species in real aquaculture environments. Then, we pioneer audio-visual class incremental learning (CIL) for FFIA and demonstrate through benchmarking on AV-CIL-FFIA that it significantly outperforms single-modality methods. Existing CIL methods rely heavily on historical data. Exemplar-based approaches store raw samples, creating storage challenges, while exemplar-free methods avoid data storage but struggle to distinguish subtle feeding intensity variations across different fish species. To overcome these limitations, we introduce HAIL-FFIA, a novel audio-visual class-incremental learning framework that bridges this gap with a prototype-based approach that achieves exemplar-free efficiency while preserving essential knowledge through compact feature representations. Specifically, HAIL-FFIA employs hierarchical representation learning with a dual-path knowledge preservation mechanism that separates general intensity knowledge from fish-specific characteristics. Additionally, it features a dynamic modality balancing system that adaptively adjusts the importance of audio versus visual information based on feeding behaviour stages. Experimental results show that HAIL-FFIA is superior to SOTA methods on AV-CIL-FFIA, achieving higher accuracy with lower storage needs while effectively mitigating catastrophic forgetting in incremental fish species learning.
HandSplat: Embedding-Driven Gaussian Splatting for High-Fidelity Hand Rendering
Mar 18, 2025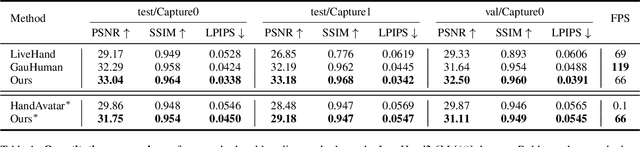
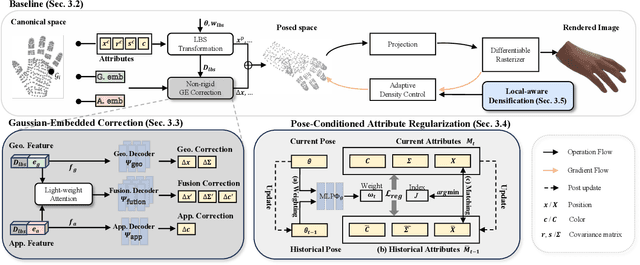
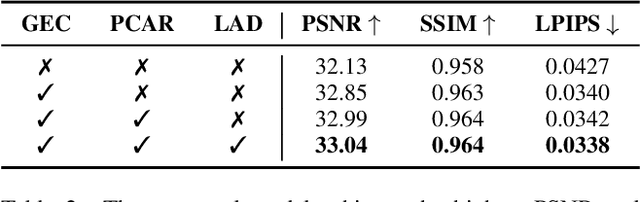

Existing 3D Gaussian Splatting (3DGS) methods for hand rendering rely on rigid skeletal motion with an oversimplified non-rigid motion model, which fails to capture fine geometric and appearance details. Additionally, they perform densification based solely on per-point gradients and process poses independently, ignoring spatial and temporal correlations. These limitations lead to geometric detail loss, temporal instability, and inefficient point distribution. To address these issues, we propose HandSplat, a novel Gaussian Splatting-based framework that enhances both fidelity and stability for hand rendering. To improve fidelity, we extend standard 3DGS attributes with implicit geometry and appearance embeddings for finer non-rigid motion modeling while preserving the static hand characteristic modeled by original 3DGS attributes. Additionally, we introduce a local gradient-aware densification strategy that dynamically refines Gaussian density in high-variation regions. To improve stability, we incorporate pose-conditioned attribute regularization to encourage attribute consistency across similar poses, mitigating temporal artifacts. Extensive experiments on InterHand2.6M demonstrate that HandSplat surpasses existing methods in fidelity and stability while achieving real-time performance. We will release the code and pre-trained models upon acceptance.