 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-Transcriber: A Robust End-to-End Framework for Multi-Speaker Speech Transcription
Jun 01, 2026Recent advances in Automatic Speech Recognition (ASR) and Large Language Models (LLMs) have significantly improved speech understanding capabilities. However, multi-speaker speech transcription remains challenging task, constrained by highly similar speaker voices, rapid turn-taking transitions, overlapping utterances and inaccurate speaker boundary segmentation. These challenges become particularly pronounced in real-world conversational audio, where speaker dynamics and acoustic conditions are highly variable. This technical report presents SoulX-Transcriber, a unified multi-speaker transcription system that jointly models speaker diarization (SD) and ASR within an LLM-based framework. SoulX-Transcriber adopts a two-stage training strategy to improve both speaker discrimination and transcription robustness. In the first stage, speaker-aware multi-task continuous pre-training enhances speaker representation learning and boundary perception. In the second stage, supervised fine-tuning further optimizes the model for accurate end-to-end speaker-attributed transcription under complex multi-speaker conditions. SoulX-Transcriber delivers strong performance and robustness across multiple public benchmarks, including AliMeeting, AISHELL-4, and AMI, while maintaining high adaptability to multi-domain scenarios.
SoulX-Duplug: Plug-and-Play Streaming State Prediction Module for Realtime Full-Duplex Speech Conversation
Mar 16, 2026Recent advances in spoken dialogue systems have brought increased attention to human-like full-duplex voice interactions. However, our comprehensive review of this field reveals several challenges, including the difficulty in obtaining training data, catastrophic forgetting, and limited scalability. In this work, we propose SoulX-Duplug, a plug-and-play streaming state prediction module for full-duplex spoken dialogue systems. By jointly performing streaming ASR, SoulX-Duplug explicitly leverages textual information to identify user intent, effectively serving as a semantic VAD. To promote fair evaluation, we introduce SoulX-Duplug-Eval, extending widely used benchmarks with improved bilingual coverage. Experimental results show that SoulX-Duplug enables low-latency streaming dialogue state control, and the system built upon it outperforms existing full-duplex models in overall turn management and latency performance. We have open-sourced SoulX-Duplug and SoulX-Duplug-Eval.
SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Feb 08, 2026While recent years have witnessed rapid progress in speech synthesis, open-source singing voice synthesis (SVS) systems still face significant barriers to industrial deployment, particularly in terms of robustness and zero-shot generalization. In this report, we introduce SoulX-Singer, a high-quality open-source SVS system designed with practical deployment considerations in mind. SoulX-Singer supports controllable singing generation conditioned on either symbolic musical scores (MIDI) or melodic representations, enabling flexible and expressive control in real-world production workflows. Trained on more than 42,000 hours of vocal data, the system supports Mandarin Chinese, English, and Cantonese and consistently achieves state-of-the-art synthesis quality across languages under diverse musical conditions. Furthermore, to enable reliable evaluation of zero-shot SVS performance in practical scenarios, we construct SoulX-Singer-Eval, a dedicated benchmark with strict training-test disentanglement, facilitating systematic assessment in zero-shot settings.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025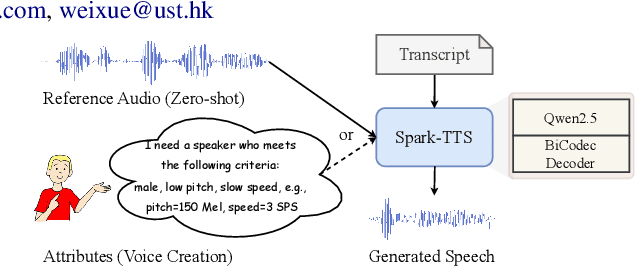
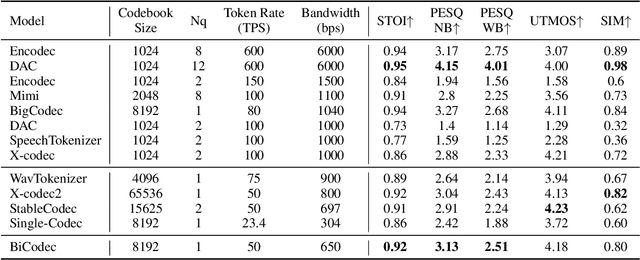
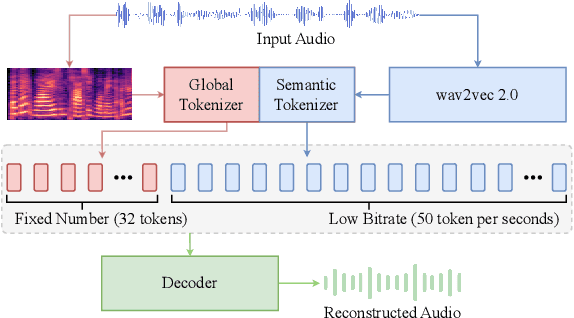
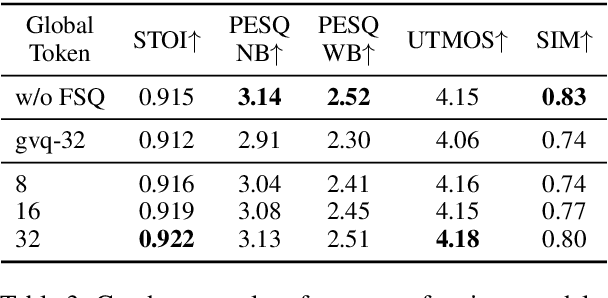
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Steering Language Model to Stable Speech Emotion Recognition via Contextual Perception and Chain of Thought
Feb 25, 2025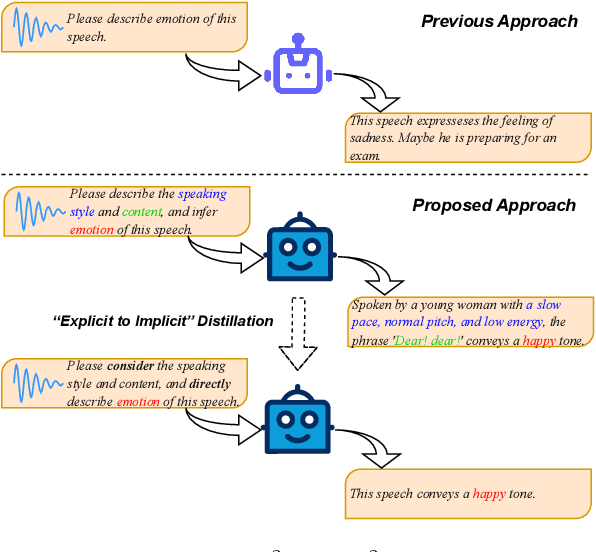


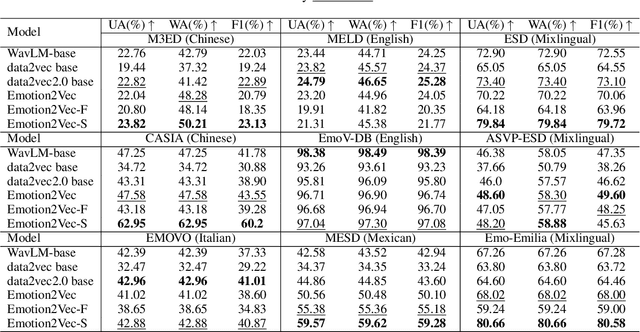
Large-scale audio language models (ALMs), such as Qwen2-Audio, are capable of comprehending diverse audio signal, performing audio analysis and generating textual responses. However, in speech emotion recognition (SER), ALMs often suffer from hallucinations, resulting in misclassifications or irrelevant outputs. To address these challenges, we propose C$^2$SER, a novel ALM designed to enhance the stability and accuracy of SER through Contextual perception and Chain of Thought (CoT). C$^2$SER integrates the Whisper encoder for semantic perception and Emotion2Vec-S for acoustic perception, where Emotion2Vec-S extends Emotion2Vec with semi-supervised learning to enhance emotional discrimination. Additionally, C$^2$SER employs a CoT approach, processing SER in a step-by-step manner while leveraging speech content and speaking styles to improve recognition. To further enhance stability, C$^2$SER introduces self-distillation from explicit CoT to implicit CoT, mitigating error accumulation and boosting recognition accuracy. Extensive experiments show that C$^2$SER outperforms existing popular ALMs, such as Qwen2-Audio and SECap, delivering more stable and precise emotion recognition. We release the training code, checkpoints, and test sets to facilitate further research.
Audio-FLAN: A Preliminary Release
Feb 23, 2025



Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Feb 06, 2025Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
CosyAudio: Improving Audio Generation with Confidence Scores and Synthetic Captions
Jan 28, 2025Text-to-Audio (TTA) generation is an emerging area within AI-generated content (AIGC), where audio is created from natural language descriptions. Despite growing interest, developing robust TTA models remains challenging due to the scarcity of well-labeled datasets and the prevalence of noisy or inaccurate captions in large-scale, weakly labeled corpora. To address these challenges, we propose CosyAudio, a novel framework that utilizes confidence scores and synthetic captions to enhance the quality of audio generation. CosyAudio consists of two core components: AudioCapTeller and an audio generator. AudioCapTeller generates synthetic captions for audio and provides confidence scores to evaluate their accuracy. The audio generator uses these synthetic captions and confidence scores to enable quality-aware audio generation. Additionally, we introduce a self-evolving training strategy that iteratively optimizes CosyAudio across both well-labeled and weakly-labeled datasets. Initially trained with well-labeled data, AudioCapTeller leverages its assessment capabilities on weakly-labeled datasets for high-quality filtering and reinforcement learning, which further improves its performance. The well-trained AudioCapTeller refines corpora by generating new captions and confidence scores, serving for the audio generator training. Extensive experiments on open-source datasets demonstrate that CosyAudio outperforms existing models in automated audio captioning, generates more faithful audio, and exhibits strong generalization across diverse scenarios.
EDSep: An Effective Diffusion-Based Method for Speech Source Separation
Jan 27, 2025


Generative models have attracted considerable attention for speech separation tasks, and among these, diffusion-based methods are being explored. Despite the notable success of diffusion techniques in generation tasks, their adaptation to speech separation has encountered challenges, notably slow convergence and suboptimal separation outcomes. To address these issues and enhance the efficacy of diffusion-based speech separation, we introduce EDSep, a novel single-channel method grounded in score matching via stochastic differential equation (SDE). This method enhances generative modeling for speech source separation by optimizing training and sampling efficiency. Specifically, a novel denoiser function is proposed to approximate data distributions, which obtains ideal denoiser outputs. Additionally, a stochastic sampler is carefully designed to resolve the reverse SDE during the sampling process, gradually separating speech from mixtures. Extensive experiments on databases such as WSJ0-2mix, LRS2-2mix, and VoxCeleb2-2mix demonstrate our proposed method's superior performance over existing diffusion and discriminative models, validating its efficacy.
FleSpeech: Flexibly Controllable Speech Generation with Various Prompts
Jan 08, 2025



Controllable speech generation methods typically rely on single or fixed prompts, hindering creativity and flexibility. These limitations make it difficult to meet specific user needs in certain scenarios, such as adjusting the style while preserving a selected speaker's timbre, or choosing a style and generating a voice that matches a character's visual appearance. To overcome these challenges, we propose \textit{FleSpeech}, a novel multi-stage speech generation framework that allows for more flexible manipulation of speech attributes by integrating various forms of control. FleSpeech employs a multimodal prompt encoder that processes and unifies different text, audio, and visual prompts into a cohesive representation. This approach enhances the adaptability of speech synthesis and supports creative and precise control over the generated speech. Additionally, we develop a data collection pipeline for multimodal datasets to facilitate further research and applications in this field. Comprehensive subjective and objective experiments demonstrate the effectiveness of FleSpeech. Audio samples are available at https://kkksuper.github.io/FleSpeech/