 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFleSpeech: Flexibly Controllable Speech Generation with Various Prompts
Jan 08, 2025



Controllable speech generation methods typically rely on single or fixed prompts, hindering creativity and flexibility. These limitations make it difficult to meet specific user needs in certain scenarios, such as adjusting the style while preserving a selected speaker's timbre, or choosing a style and generating a voice that matches a character's visual appearance. To overcome these challenges, we propose \textit{FleSpeech}, a novel multi-stage speech generation framework that allows for more flexible manipulation of speech attributes by integrating various forms of control. FleSpeech employs a multimodal prompt encoder that processes and unifies different text, audio, and visual prompts into a cohesive representation. This approach enhances the adaptability of speech synthesis and supports creative and precise control over the generated speech. Additionally, we develop a data collection pipeline for multimodal datasets to facilitate further research and applications in this field. Comprehensive subjective and objective experiments demonstrate the effectiveness of FleSpeech. Audio samples are available at https://kkksuper.github.io/FleSpeech/
CoDiff-VC: A Codec-Assisted Diffusion Model for Zero-shot Voice Conversion
Dec 03, 2024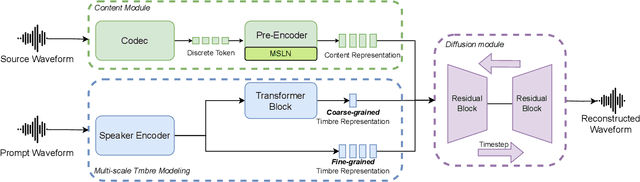
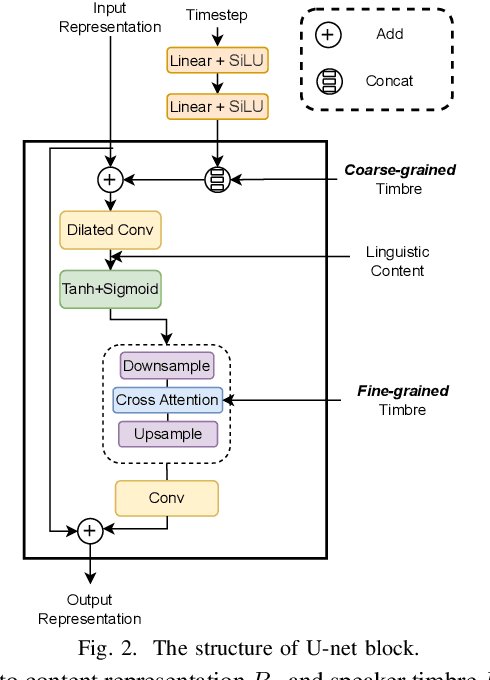
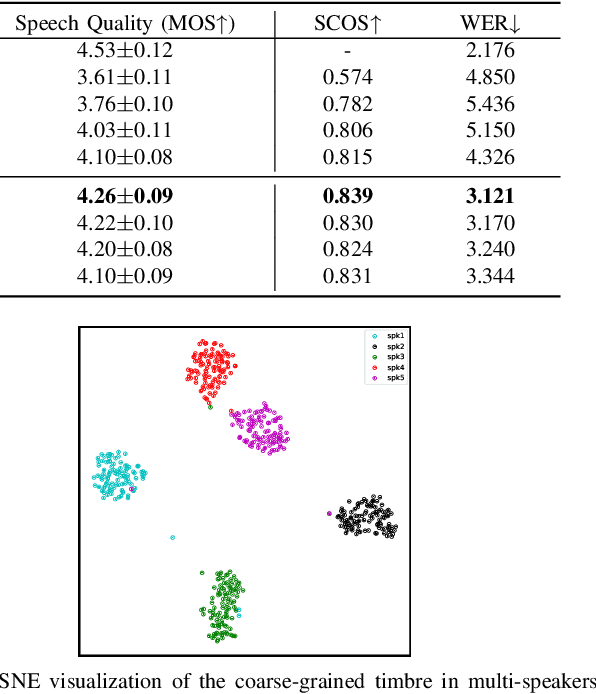
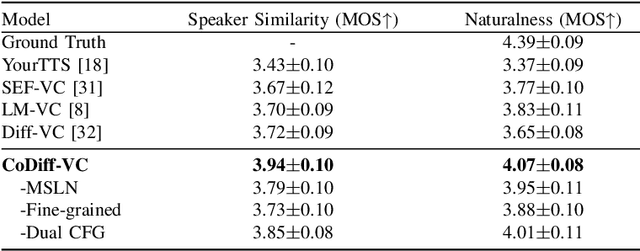
Zero-shot voice conversion (VC) aims to convert the original speaker's timbre to any target speaker while keeping the linguistic content. Current mainstream zero-shot voice conversion approaches depend on pre-trained recognition models to disentangle linguistic content and speaker representation. This results in a timbre residue within the decoupled linguistic content and inadequacies in speaker representation modeling. In this study, we propose CoDiff-VC, an end-to-end framework for zero-shot voice conversion that integrates a speech codec and a diffusion model to produce high-fidelity waveforms. Our approach involves employing a single-codebook codec to separate linguistic content from the source speech. To enhance content disentanglement, we introduce Mix-Style layer normalization (MSLN) to perturb the original timbre. Additionally, we incorporate a multi-scale speaker timbre modeling approach to ensure timbre consistency and improve voice detail similarity. To improve speech quality and speaker similarity, we introduce dual classifier-free guidance, providing both content and timbre guidance during the generation process. Objective and subjective experiments affirm that CoDiff-VC significantly improves speaker similarity, generating natural and higher-quality speech.
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge: Tasks, Results and Findings
Oct 31, 2024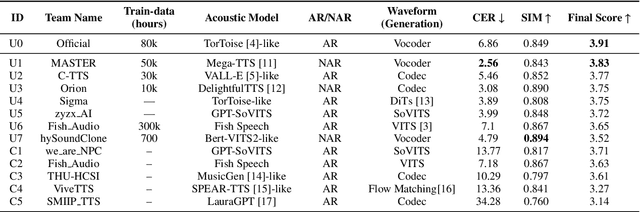
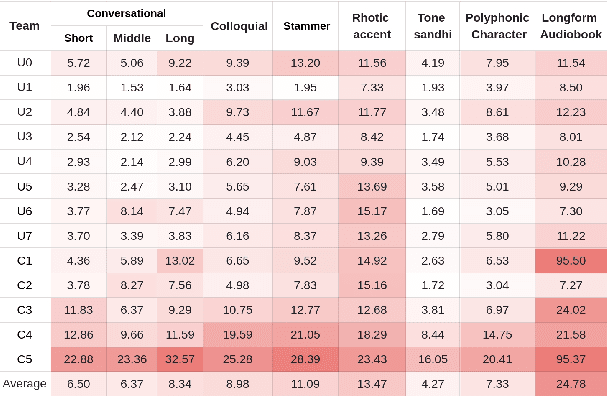
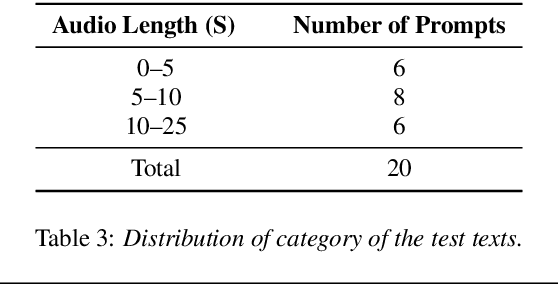
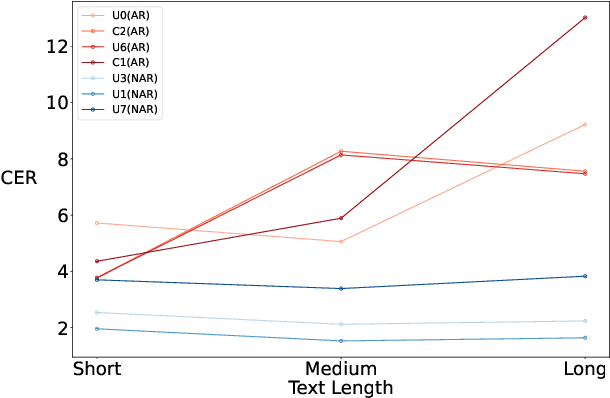
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge aims to benchmark and advance zero-shot spontaneous style voice cloning, particularly focusing on generating spontaneous behaviors in conversational speech. The challenge comprises two tracks: an unconstrained track without limitation on data and model usage, and a constrained track only allowing the use of constrained open-source datasets. A 100-hour high-quality conversational speech dataset is also made available with the challenge. This paper details the data, tracks, submitted systems, evaluation results, and findings.
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
Jun 11, 2024


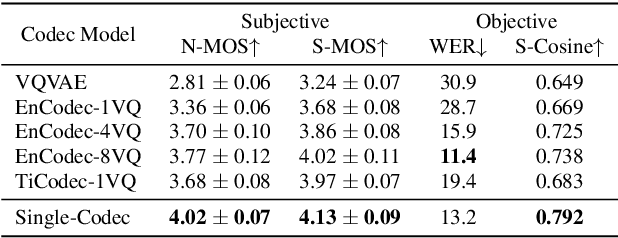
The multi-codebook speech codec enables the application of large language models (LLM) in TTS but bottlenecks efficiency and robustness due to multi-sequence prediction. To avoid this obstacle, we propose Single-Codec, a single-codebook single-sequence codec, which employs a disentangled VQ-VAE to decouple speech into a time-invariant embedding and a phonetically-rich discrete sequence. Furthermore, the encoder is enhanced with 1) contextual modeling with a BLSTM module to exploit the temporal information, 2) a hybrid sampling module to alleviate distortion from upsampling and downsampling, and 3) a resampling module to encourage discrete units to carry more phonetic information. Compared with multi-codebook codecs, e.g., EnCodec and TiCodec, Single-Codec demonstrates higher reconstruction quality with a lower bandwidth of only 304bps. The effectiveness of Single-Code is further validated by LLM-TTS experiments, showing improved naturalness and intelligibility.
SponTTS: modeling and transferring spontaneous style for TTS
Nov 13, 2023Spontaneous speaking style exhibits notable differences from other speaking styles due to various spontaneous phenomena (e.g., filled pauses, prolongation) and substantial prosody variation (e.g., diverse pitch and duration variation, occasional non-verbal speech like smile), posing challenges to modeling and prediction of spontaneous style. Moreover, the limitation of high-quality spontaneous data constrains spontaneous speech generation for speakers without spontaneous data. To address these problems, we propose SponTTS, a two-stage approach based on bottleneck (BN) features to model and transfer spontaneous style for TTS. In the first stage, we adopt a Conditional Variational Autoencoder (CVAE) to capture spontaneous prosody from a BN feature and involve the spontaneous phenomena by the constraint of spontaneous phenomena embedding prediction loss. Besides, we introduce a flow-based predictor to predict a latent spontaneous style representation from the text, which enriches the prosody and context-specific spontaneous phenomena during inference. In the second stage, we adopt a VITS-like module to transfer the spontaneous style learned in the first stage to target speakers. Experiments demonstrate that SponTTS is effective in modeling spontaneous style and transferring the style to the target speakers, generating spontaneous speech with high naturalness, expressiveness, and speaker similarity. The zero-shot spontaneous style TTS test further verifies the generalization and robustness of SponTTS in generating spontaneous speech for unseen speakers.
V2V4Real: A Real-world Large-scale Dataset for Vehicle-to-Vehicle Cooperative Perception
Mar 19, 2023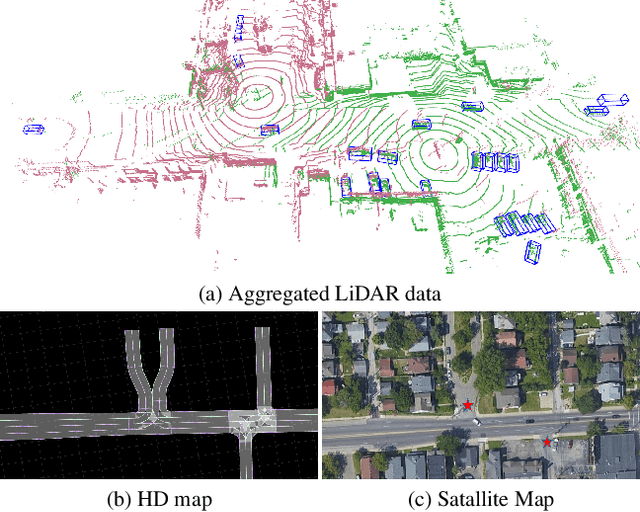



Modern perception systems of autonomous vehicles are known to be sensitive to occlusions and lack the capability of long perceiving range. It has been one of the key bottlenecks that prevents Level 5 autonomy. Recent research has demonstrated that the Vehicle-to-Vehicle (V2V) cooperative perception system has great potential to revolutionize the autonomous driving industry. However, the lack of a real-world dataset hinders the progress of this field. To facilitate the development of cooperative perception, we present V2V4Real, the first large-scale real-world multi-modal dataset for V2V perception. The data is collected by two vehicles equipped with multi-modal sensors driving together through diverse scenarios. Our V2V4Real dataset covers a driving area of 410 km, comprising 20K LiDAR frames, 40K RGB frames, 240K annotated 3D bounding boxes for 5 classes, and HDMaps that cover all the driving routes. V2V4Real introduces three perception tasks, including cooperative 3D object detection, cooperative 3D object tracking, and Sim2Real domain adaptation for cooperative perception. We provide comprehensive benchmarks of recent cooperative perception algorithms on three tasks. The V2V4Real dataset can be found at https://research.seas.ucla.edu/mobility-lab/v2v4real/.
Automated Driving Systems Data Acquisition and Processing Platform
Nov 24, 2022This paper presents an automated driving system (ADS) data acquisition and processing platform for vehicle trajectory extraction, reconstruction, and evaluation based on connected automated vehicle (CAV) cooperative perception. This platform presents a holistic pipeline from the raw advanced sensory data collection to data processing, which can process the sensor data from multiple CAVs and extract the objects' Identity (ID) number, position, speed, and orientation information in the map and Frenet coordinates. First, the ADS data acquisition and analytics platform are presented. Specifically, the experimental CAVs platform and sensor configuration are shown, and the processing software, including a deep-learning-based object detection algorithm using LiDAR information, a late fusion scheme to leverage cooperative perception to fuse the detected objects from multiple CAVs, and a multi-object tracking method is introduced. To further enhance the object detection and tracking results, high definition maps consisting of point cloud and vector maps are generated and forwarded to a world model to filter out the objects off the road and extract the objects' coordinates in Frenet coordinates and the lane information. In addition, a post-processing method is proposed to refine trajectories from the object tracking algorithms. Aiming to tackle the ID switch issue of the object tracking algorithm, a fuzzy-logic-based approach is proposed to detect the discontinuous trajectories of the same object. Finally, results, including object detection and tracking and a late fusion scheme, are presented, and the post-processing algorithm's improvements in noise level and outlier removal are discussed, confirming the functionality and effectiveness of the proposed holistic data collection and processing platform.
VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
Nov 05, 2022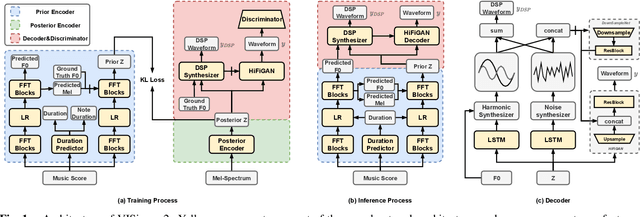
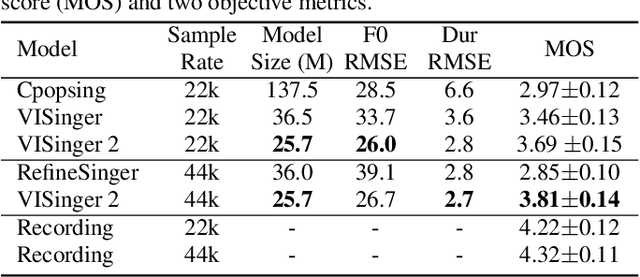
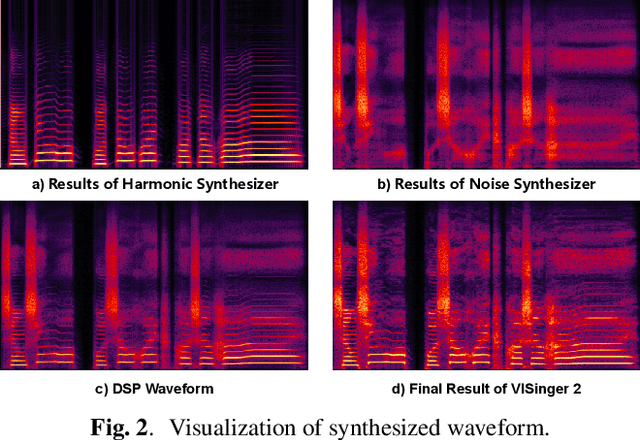
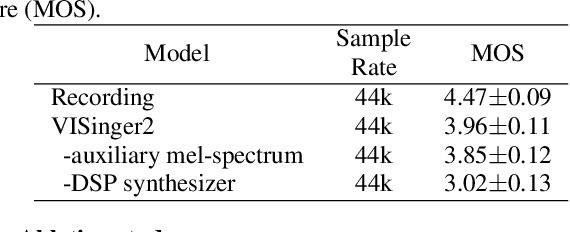
End-to-end singing voice synthesis (SVS) model VISinger can achieve better performance than the typical two-stage model with fewer parameters. However, VISinger has several problems: text-to-phase problem, the end-to-end model learns the meaningless mapping of text-to-phase; glitches problem, the harmonic components corresponding to the periodic signal of the voiced segment occurs a sudden change with audible artefacts; low sampling rate, the sampling rate of 24KHz does not meet the application needs of high-fidelity generation with the full-band rate (44.1KHz or higher). In this paper, we propose VISinger 2 to address these issues by integrating the digital signal processing (DSP) methods with VISinger. Specifically, inspired by recent advances in differentiable digital signal processing (DDSP), we incorporate a DSP synthesizer into the decoder to solve the above issues. The DSP synthesizer consists of a harmonic synthesizer and a noise synthesizer to generate periodic and aperiodic signals, respectively, from the latent representation z in VISinger. It supervises the posterior encoder to extract the latent representation without phase information and avoid the prior encoder modelling text-to-phase mapping. To avoid glitch artefacts, the HiFi-GAN is modified to accept the waveforms generated by the DSP synthesizer as a condition to produce the singing voice. Moreover, with the improved waveform decoder, VISinger 2 manages to generate 44.1kHz singing audio with richer expression and better quality. Experiments on OpenCpop corpus show that VISinger 2 outperforms VISinger, CpopSing and RefineSinger in both subjective and objective metrics.
DSPGAN: a GAN-based universal vocoder for high-fidelity TTS by time-frequency domain supervision from DSP
Nov 02, 2022



Recent development of neural vocoders based on the generative adversarial neural network (GAN) has shown their advantages of generating raw waveform conditioned on mel-spectrogram with fast inference speed and lightweight networks. Whereas, it is still challenging to train a universal neural vocoder that can synthesize high-fidelity speech from various scenarios with unseen speakers, languages, and speaking styles. In this paper, we propose DSPGAN, a GAN-based universal vocoder for high-fidelity speech synthesis by applying the time-frequency domain supervision from digital signal processing (DSP). To eliminate the mismatch problem caused by the ground-truth spectrograms in training phase and the predicted spectrograms in inference phase, we leverage the mel-spectrogram extracted from the waveform generated by a DSP module, rather than the predicted mel-spectrogram from the Text-to-Speech (TTS) acoustic model, as the time-frequency domain supervision to the GAN-based vocoder. We also utilize sine excitation as the time-domain supervision to improve the harmonic modeling and eliminate various artifacts of the GAN-based vocoder. Experimental results show that DSPGAN significantly outperforms the compared approaches and can generate high-fidelity speech based on diverse data in TTS.
Opencpop: A High-Quality Open Source Chinese Popular Song Corpus for Singing Voice Synthesis
Jan 20, 2022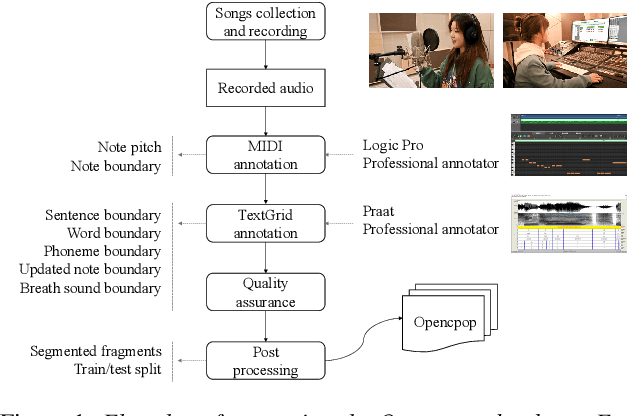
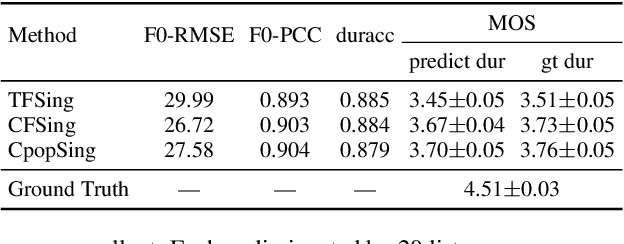


This paper introduces Opencpop, a publicly available high-quality Mandarin singing corpus designed for singing voice synthesis (SVS). The corpus consists of 100 popular Mandarin songs performed by a female professional singer. Audio files are recorded with studio quality at a sampling rate of 44,100 Hz and the corresponding lyrics and musical scores are provided. All singing recordings have been phonetically annotated with phoneme boundaries and syllable (note) boundaries. To demonstrate the reliability of the released data and to provide a baseline for future research, we built baseline deep neural network-based SVS models and evaluated them with both objective metrics and subjective mean opinion score (MOS) measure. Experimental results show that the best SVS model trained on our database achieves 3.70 MOS, indicating the reliability of the provided corpus. Opencpop is released to the open-source community WeNet, and the corpus, as well as synthesized demos, can be found on the project homepage.