 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealRep: Generalized SDR-to-HDR Conversion with Style Disentangled Representation Learning
May 12, 2025High-Dynamic-Range Wide-Color-Gamut (HDR-WCG) technology is becoming increasingly prevalent, intensifying the demand for converting Standard Dynamic Range (SDR) content to HDR. Existing methods primarily rely on fixed tone mapping operators, which are inadequate for handling SDR inputs with diverse styles commonly found in real-world scenarios. To address this challenge, we propose a generalized SDR-to-HDR method that handles diverse styles in real-world SDR content, termed Realistic Style Disentangled Representation Learning (RealRep). By disentangling luminance and chrominance, we analyze the intrinsic differences between contents with varying styles and propose a disentangled multi-view style representation learning method. This approach captures the guidance prior of true luminance and chrominance distributions across different styles, even when the SDR style distributions exhibit significant variations, thereby establishing a robust embedding space for inverse tone mapping. Motivated by the difficulty of directly utilizing degradation representation priors, we further introduce the Degradation-Domain Aware Controlled Mapping Network (DDACMNet), a two-stage framework that performs adaptive hierarchical mapping guided by a control-aware normalization mechanism. DDACMNet dynamically modulates the mapping process via degradation-conditioned hierarchical features, enabling robust adaptation across diverse degradation domains. Extensive experiments show that RealRep consistently outperforms state-of-the-art methods with superior generalization and perceptually faithful HDR color gamut reconstruction.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
An End-to-End Real-World Camera Imaging Pipeline
Nov 16, 2024



Recent advances in neural camera imaging pipelines have demonstrated notable progress. Nevertheless, the real-world imaging pipeline still faces challenges including the lack of joint optimization in system components, computational redundancies, and optical distortions such as lens shading.In light of this, we propose an end-to-end camera imaging pipeline (RealCamNet) to enhance real-world camera imaging performance. Our methodology diverges from conventional, fragmented multi-stage image signal processing towards end-to-end architecture. This architecture facilitates joint optimization across the full pipeline and the restoration of coordinate-biased distortions. RealCamNet is designed for high-quality conversion from RAW to RGB and compact image compression. Specifically, we deeply analyze coordinate-dependent optical distortions, e.g., vignetting and dark shading, and design a novel Coordinate-Aware Distortion Restoration (CADR) module to restore coordinate-biased distortions. Furthermore, we propose a Coordinate-Independent Mapping Compression (CIMC) module to implement tone mapping and redundant information compression. Existing datasets suffer from misalignment and overly idealized conditions, making them inadequate for training real-world imaging pipelines. Therefore, we collected a real-world imaging dataset. Experiment results show that RealCamNet achieves the best rate-distortion performance with lower inference latency.
Beyond Feature Mapping GAP: Integrating Real HDRTV Priors for Superior SDRTV-to-HDRTV Conversion
Nov 16, 2024



The rise of HDR-WCG display devices has highlighted the need to convert SDRTV to HDRTV, as most video sources are still in SDR. Existing methods primarily focus on designing neural networks to learn a single-style mapping from SDRTV to HDRTV. However, the limited information in SDRTV and the diversity of styles in real-world conversions render this process an ill-posed problem, thereby constraining the performance and generalization of these methods. Inspired by generative approaches, we propose a novel method for SDRTV to HDRTV conversion guided by real HDRTV priors. Despite the limited information in SDRTV, introducing real HDRTV as reference priors significantly constrains the solution space of the originally high-dimensional ill-posed problem. This shift transforms the task from solving an unreferenced prediction problem to making a referenced selection, thereby markedly enhancing the accuracy and reliability of the conversion process. Specifically, our approach comprises two stages: the first stage employs a Vector Quantized Generative Adversarial Network to capture HDRTV priors, while the second stage matches these priors to the input SDRTV content to recover realistic HDRTV outputs. We evaluate our method on public datasets, demonstrating its effectiveness with significant improvements in both objective and subjective metrics across real and synthetic datasets.
Beyond Alignment: Blind Video Face Restoration via Parsing-Guided Temporal-Coherent Transformer
Apr 21, 2024



Multiple complex degradations are coupled in low-quality video faces in the real world. Therefore, blind video face restoration is a highly challenging ill-posed problem, requiring not only hallucinating high-fidelity details but also enhancing temporal coherence across diverse pose variations. Restoring each frame independently in a naive manner inevitably introduces temporal incoherence and artifacts from pose changes and keypoint localization errors. To address this, we propose the first blind video face restoration approach with a novel parsing-guided temporal-coherent transformer (PGTFormer) without pre-alignment. PGTFormer leverages semantic parsing guidance to select optimal face priors for generating temporally coherent artifact-free results. Specifically, we pre-train a temporal-spatial vector quantized auto-encoder on high-quality video face datasets to extract expressive context-rich priors. Then, the temporal parse-guided codebook predictor (TPCP) restores faces in different poses based on face parsing context cues without performing face pre-alignment. This strategy reduces artifacts and mitigates jitter caused by cumulative errors from face pre-alignment. Finally, the temporal fidelity regulator (TFR) enhances fidelity through temporal feature interaction and improves video temporal consistency. Extensive experiments on face videos show that our method outperforms previous face restoration baselines. The code will be released on \href{https://github.com/kepengxu/PGTFormer}{https://github.com/kepengxu/PGTFormer}.
Towards Robust SDRTV-to-HDRTV via Dual Inverse Degradation Network
Jul 07, 2023



Recently, the transformation of standard dynamic range TV (SDRTV) to high dynamic range TV (HDRTV) is in high demand due to the scarcity of HDRTV content. However, the conversion of SDRTV to HDRTV often amplifies the existing coding artifacts in SDRTV which deteriorate the visual quality of the output. In this study, we propose a dual inverse degradation SDRTV-to-HDRTV network DIDNet to address the issue of coding artifact restoration in converted HDRTV, which has not been previously studied. Specifically, we propose a temporal-spatial feature alignment module and dual modulation convolution to remove coding artifacts and enhance color restoration ability. Furthermore, a wavelet attention module is proposed to improve SDRTV features in the frequency domain. An auxiliary loss is introduced to decouple the learning process for effectively restoring from dual degradation. The proposed method outperforms the current state-of-the-art method in terms of quantitative results, visual quality, and inference times, thus enhancing the performance of the SDRTV-to-HDRTV method in real-world scenarios.
SDRTV-to-HDRTV Conversion via Spatial-Temporal Feature Fusion
Nov 04, 2022HDR(High Dynamic Range) video can reproduce realistic scenes more realistically, with a wider gamut and broader brightness range. HDR video resources are still scarce, and most videos are still stored in SDR (Standard Dynamic Range) format. Therefore, SDRTV-to-HDRTV Conversion (SDR video to HDR video) can significantly enhance the user's video viewing experience. Since the correlation between adjacent video frames is very high, the method utilizing the information of multiple frames can improve the quality of the converted HDRTV. Therefore, we propose a multi-frame fusion neural network \textbf{DSLNet} for SDRTV to HDRTV conversion. We first propose a dynamic spatial-temporal feature alignment module \textbf{DMFA}, which can align and fuse multi-frame. Then a novel spatial-temporal feature modulation module \textbf{STFM}, STFM extracts spatial-temporal information of adjacent frames for more accurate feature modulation. Finally, we design a quality enhancement module \textbf{LKQE} with large kernels, which can enhance the quality of generated HDR videos. To evaluate the performance of the proposed method, we construct a corresponding multi-frame dataset using HDR video of the HDR10 standard to conduct a comprehensive evaluation of different methods. The experimental results show that our method obtains state-of-the-art performance. The dataset and code will be released.
DSPGAN: a GAN-based universal vocoder for high-fidelity TTS by time-frequency domain supervision from DSP
Nov 02, 2022



Recent development of neural vocoders based on the generative adversarial neural network (GAN) has shown their advantages of generating raw waveform conditioned on mel-spectrogram with fast inference speed and lightweight networks. Whereas, it is still challenging to train a universal neural vocoder that can synthesize high-fidelity speech from various scenarios with unseen speakers, languages, and speaking styles. In this paper, we propose DSPGAN, a GAN-based universal vocoder for high-fidelity speech synthesis by applying the time-frequency domain supervision from digital signal processing (DSP). To eliminate the mismatch problem caused by the ground-truth spectrograms in training phase and the predicted spectrograms in inference phase, we leverage the mel-spectrogram extracted from the waveform generated by a DSP module, rather than the predicted mel-spectrogram from the Text-to-Speech (TTS) acoustic model, as the time-frequency domain supervision to the GAN-based vocoder. We also utilize sine excitation as the time-domain supervision to improve the harmonic modeling and eliminate various artifacts of the GAN-based vocoder. Experimental results show that DSPGAN significantly outperforms the compared approaches and can generate high-fidelity speech based on diverse data in TTS.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022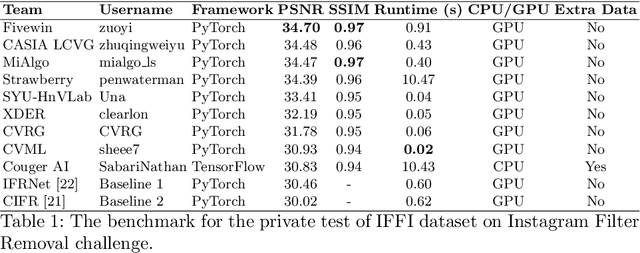

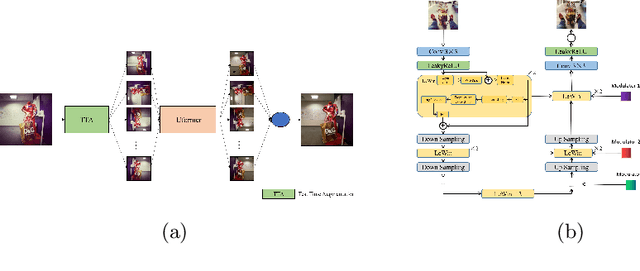
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
Global Priors Guided Modulation Network for Joint Super-Resolution and Inverse Tone-Mapping
Aug 14, 2022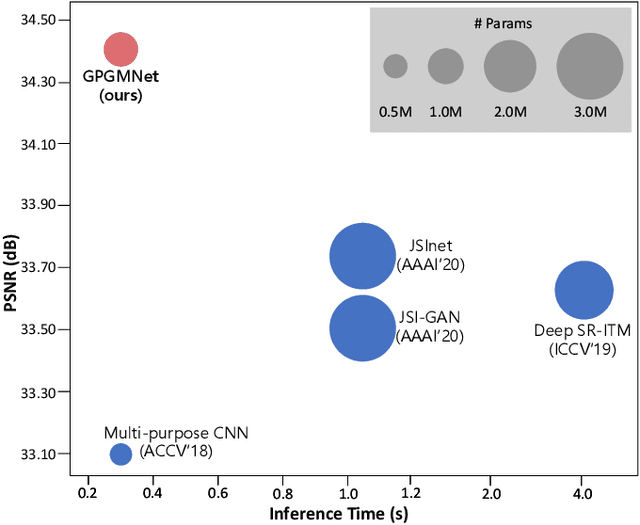
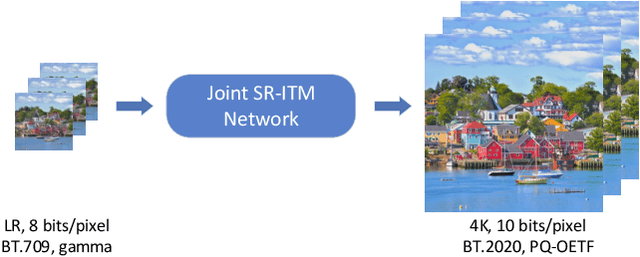
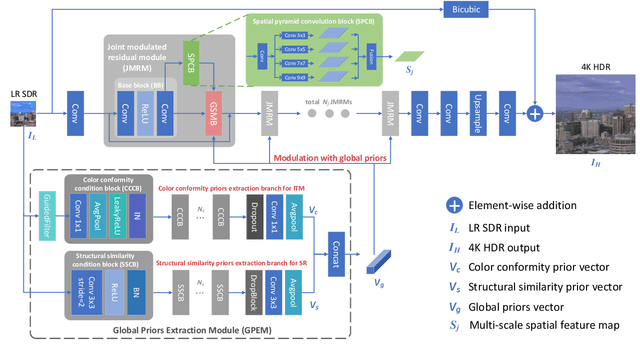
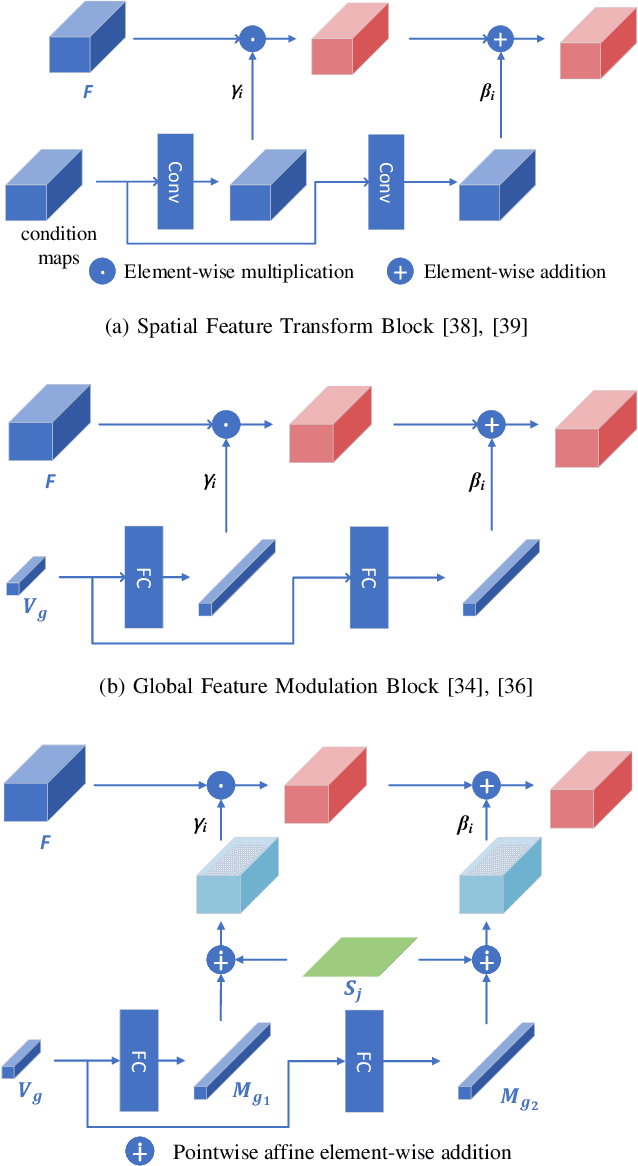
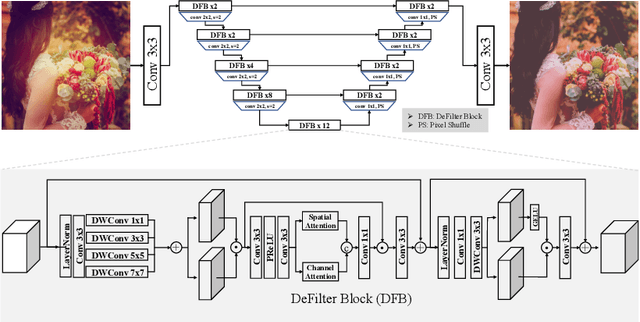
Joint super-resolution and inverse tone-mapping (SR-ITM) aims to enhance the visual quality of videos that have quality deficiencies in resolution and dynamic range. This problem arises when using 4K high dynamic range (HDR) TVs to watch a low-resolution standard dynamic range (LR SDR) video. Previous methods that rely on learning local information typically cannot do well in preserving color conformity and long-range structural similarity, resulting in unnatural color transition and texture artifacts. In order to tackle these challenges, we propose a global priors guided modulation network (GPGMNet) for joint SR-ITM. In particular, we design a global priors extraction module (GPEM) to extract color conformity prior and structural similarity prior that are beneficial for ITM and SR tasks, respectively. To further exploit the global priors and preserve spatial information, we devise multiple global priors guided spatial-wise modulation blocks (GSMBs) with a few parameters for intermediate feature modulation, in which the modulation parameters are generated by the shared global priors and the spatial features map from the spatial pyramid convolution block (SPCB). With these elaborate designs, the GPGMNet can achieve higher visual quality with lower computational complexity. Extensive experiments demonstrate that our proposed GPGMNet is superior to the state-of-the-art methods. Specifically, our proposed model exceeds the state-of-the-art by 0.64 dB in PSNR, with 69$\%$ fewer parameters and 3.1$\times$ speedup. The code will be released soon.