 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing
May 07, 2024



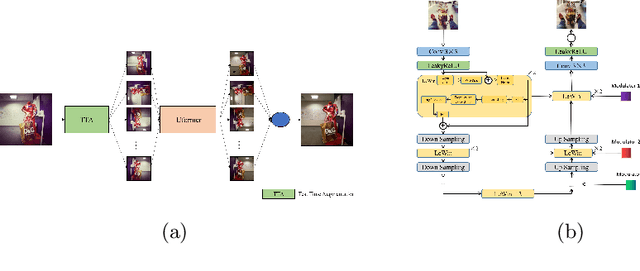
Existing diffusion-based video editing methods have achieved impressive results in motion editing. Most of the existing methods focus on the motion alignment between the edited video and the reference video. However, these methods do not constrain the background and object content of the video to remain unchanged, which makes it possible for users to generate unexpected videos. In this paper, we propose a one-shot video motion editing method called Edit-Your-Motion that requires only a single text-video pair for training. Specifically, we design the Detailed Prompt-Guided Learning Strategy (DPL) to decouple spatio-temporal features in space-time diffusion models. DPL separates learning object content and motion into two training stages. In the first training stage, we focus on learning the spatial features (the features of object content) and breaking down the temporal relationships in the video frames by shuffling them. We further propose Recurrent-Causal Attention (RC-Attn) to learn the consistent content features of the object from unordered video frames. In the second training stage, we restore the temporal relationship in video frames to learn the temporal feature (the features of the background and object's motion). We also adopt the Noise Constraint Loss to smooth out inter-frame differences. Finally, in the inference stage, we inject the content features of the source object into the editing branch through a two-branch structure (editing branch and reconstruction branch). With Edit-Your-Motion, users can edit the motion of objects in the source video to generate more exciting and diverse videos. Comprehensive qualitative experiments, quantitative experiments and user preference studies demonstrate that Edit-Your-Motion performs better than other methods.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022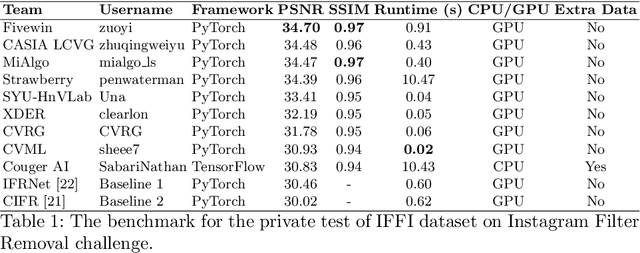

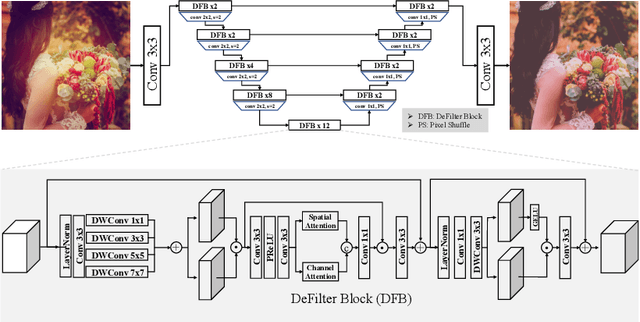
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021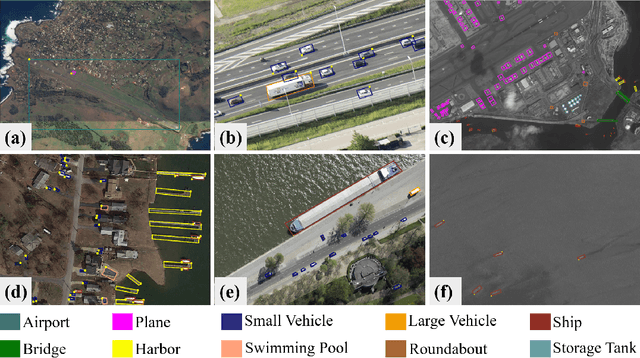

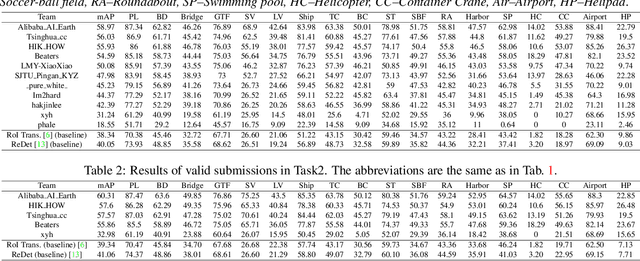
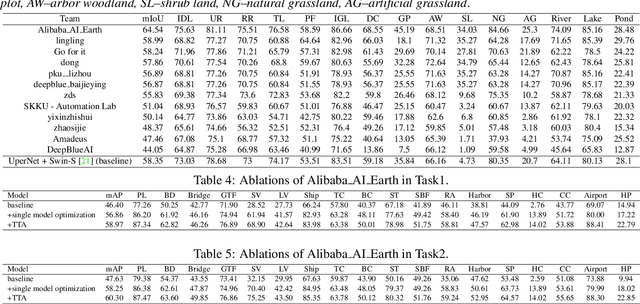
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.