 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewards as Labels: Revisiting RLVR from a Classification Perspective
Feb 05, 2026Reinforcement Learning with Verifiable Rewards has recently advanced the capabilities of Large Language Models in complex reasoning tasks by providing explicit rule-based supervision. Among RLVR methods, GRPO and its variants have achieved strong empirical performance. Despite their success, we identify that they suffer from Gradient Misassignment in Positives and Gradient Domination in Negatives, which lead to inefficient and suboptimal policy updates. To address these issues, we propose Rewards as Labels (REAL), a novel framework that revisits verifiable rewards as categorical labels rather than scalar weights, thereby reformulating policy optimization as a classification problem. Building on this, we further introduce anchor logits to enhance policy learning. Our analysis reveals that REAL induces a monotonic and bounded gradient weighting, enabling balanced gradient allocation across rollouts and effectively mitigating the identified mismatches. Extensive experiments on mathematical reasoning benchmarks show that REAL improves training stability and consistently outperforms GRPO and strong variants such as DAPO. On the 1.5B model, REAL improves average Pass@1 over DAPO by 6.7%. These gains further scale to 7B model, REAL continues to outperform DAPO and GSPO by 6.2% and 1.7%, respectively. Notably, even with a vanilla binary cross-entropy, REAL remains stable and exceeds DAPO by 4.5% on average.
Task-free Adaptive Meta Black-box Optimization
Jan 29, 2026Handcrafted optimizers become prohibitively inefficient for complex black-box optimization (BBO) tasks. MetaBBO addresses this challenge by meta-learning to automatically configure optimizers for low-level BBO tasks, thereby eliminating heuristic dependencies. However, existing methods typically require extensive handcrafted training tasks to learn meta-strategies that generalize to target tasks, which poses a critical limitation for realistic applications with unknown task distributions. To overcome the issue, we propose the Adaptive meta Black-box Optimization Model (ABOM), which performs online parameter adaptation using solely optimization data from the target task, obviating the need for predefined task distributions. Unlike conventional metaBBO frameworks that decouple meta-training and optimization phases, ABOM introduces a closed-loop adaptive parameter learning mechanism, where parameterized evolutionary operators continuously self-update by leveraging generated populations during optimization. This paradigm shift enables zero-shot optimization: ABOM achieves competitive performance on synthetic BBO benchmarks and realistic unmanned aerial vehicle path planning problems without any handcrafted training tasks. Visualization studies reveal that parameterized evolutionary operators exhibit statistically significant search patterns, including natural selection and genetic recombination.
DIVE into MoE: Diversity-Enhanced Reconstruction of Large Language Models from Dense into Mixture-of-Experts
Jun 11, 2025



Large language models (LLMs) with the Mixture-of-Experts (MoE) architecture achieve high cost-efficiency by selectively activating a subset of the parameters. Despite the inference efficiency of MoE LLMs, the training of extensive experts from scratch incurs substantial overhead, whereas reconstructing a dense LLM into an MoE LLM significantly reduces the training budget. However, existing reconstruction methods often overlook the diversity among experts, leading to potential redundancy. In this paper, we come up with the observation that a specific LLM exhibits notable diversity after being pruned on different calibration datasets, based on which we present a Diversity-Enhanced reconstruction method named DIVE. The recipe of DIVE includes domain affinity mining, pruning-based expert reconstruction, and efficient retraining. Specifically, the reconstruction includes pruning and reassembly of the feed-forward network (FFN) module. After reconstruction, we efficiently retrain the model on routers, experts and normalization modules. We implement DIVE on Llama-style LLMs with open-source training corpora. Experiments show that DIVE achieves training efficiency with minimal accuracy trade-offs, outperforming existing pruning and MoE reconstruction methods with the same number of activated parameters.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025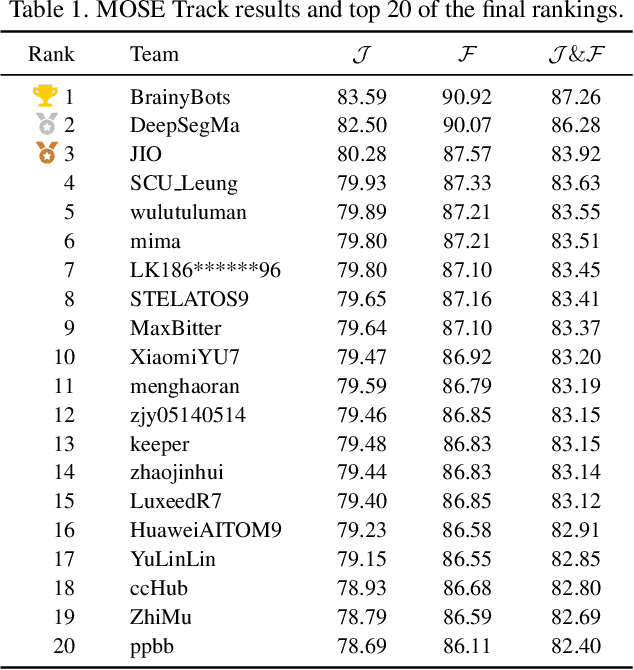
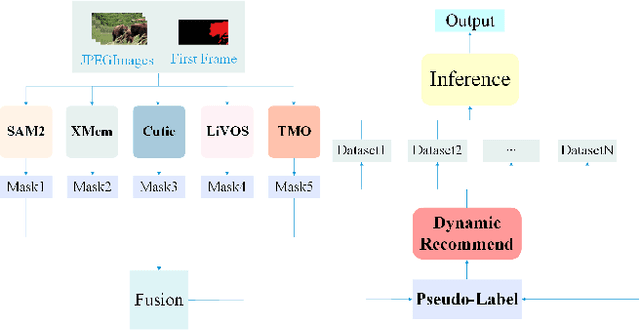
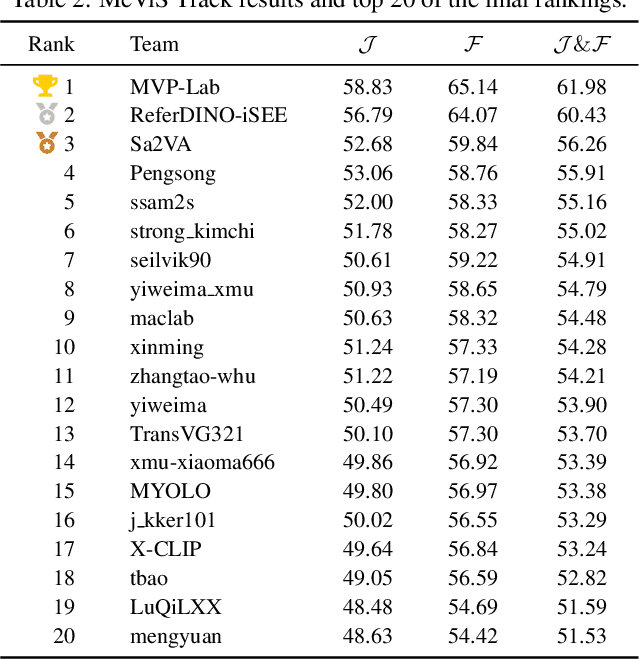
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
MASSeg : 2nd Technical Report for 4th PVUW MOSE Track
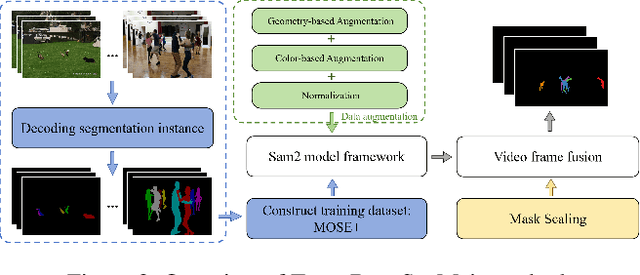
Apr 14, 2025Complex video object segmentation continues to face significant challenges in small object recognition, occlusion handling, and dynamic scene modeling. This report presents our solution, which ranked second in the MOSE track of CVPR 2025 PVUW Challenge. Based on an existing segmentation framework, we propose an improved model named MASSeg for complex video object segmentation, and construct an enhanced dataset, MOSE+, which includes typical scenarios with occlusions, cluttered backgrounds, and small target instances. During training, we incorporate a combination of inter-frame consistent and inconsistent data augmentation strategies to improve robustness and generalization. During inference, we design a mask output scaling strategy to better adapt to varying object sizes and occlusion levels. As a result, MASSeg achieves a J score of 0.8250, F score of 0.9007, and a J&F score of 0.8628 on the MOSE test set.
Learning Evolution via Optimization Knowledge Adaptation
Jan 04, 2025



Evolutionary algorithms (EAs) maintain populations through evolutionary operators to discover diverse solutions for complex tasks while gathering valuable knowledge, such as historical population data and fitness evaluations. However, traditional EAs face challenges in dynamically adapting to expanding knowledge bases, hindering the efficient exploitation of accumulated information and limiting adaptability to new situations. To address these issues, we introduce an Optimization Knowledge Adaptation Evolutionary Model (OKAEM), which features dynamic parameter adjustment using accumulated knowledge to enhance its optimization capabilities. OKAEM employs attention mechanisms to model the interactions among individuals, fitness landscapes, and genetic components separately, thereby parameterizing the evolutionary operators of selection, crossover, and mutation. These powerful learnable operators enable OKAEM to benefit from pre-learned extensive prior knowledge and self-tune with real-time evolutionary insights. Experimental results demonstrate that OKAEM: 1) exploits prior knowledge for significant performance gains across various knowledge transfer settings; 2) achieves competitive performance through self-tuning alone, even without prior knowledge; 3) outperforms state-of-the-art black-box baselines in a vision-language model tuning case; 4) can improve its optimization capabilities with growing knowledge; 5) is capable of emulating principles of natural selection and genetic recombination.
Knowledge-aware Evolutionary Graph Neural Architecture Search
Nov 26, 2024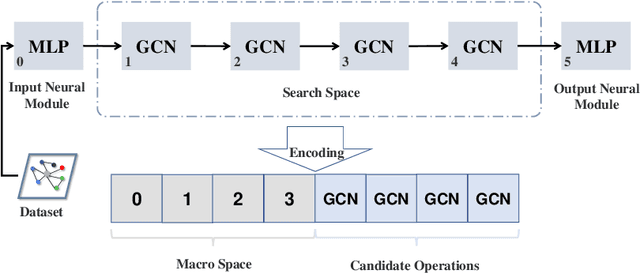
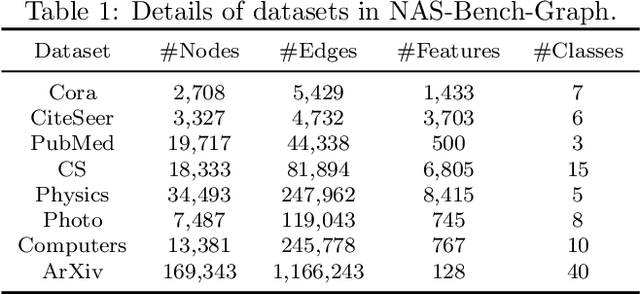
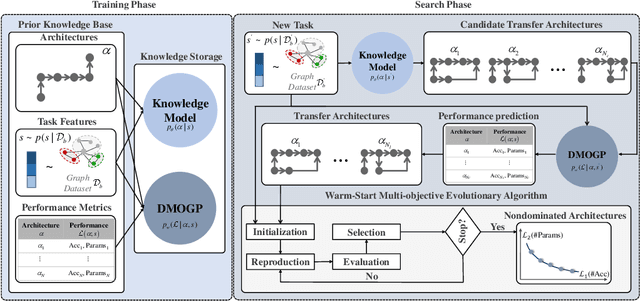
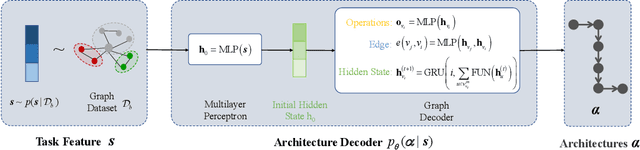
Graph neural architecture search (GNAS) can customize high-performance graph neural network architectures for specific graph tasks or datasets. However, existing GNAS methods begin searching for architectures from a zero-knowledge state, ignoring the prior knowledge that may improve the search efficiency. The available knowledge base (e.g. NAS-Bench-Graph) contains many rich architectures and their multiple performance metrics, such as the accuracy (#Acc) and number of parameters (#Params). This study proposes exploiting such prior knowledge to accelerate the multi-objective evolutionary search on a new graph dataset, named knowledge-aware evolutionary GNAS (KEGNAS). KEGNAS employs the knowledge base to train a knowledge model and a deep multi-output Gaussian process (DMOGP) in one go, which generates and evaluates transfer architectures in only a few GPU seconds. The knowledge model first establishes a dataset-to-architecture mapping, which can quickly generate candidate transfer architectures for a new dataset. Subsequently, the DMOGP with architecture and dataset encodings is designed to predict multiple performance metrics for candidate transfer architectures on the new dataset. According to the predicted metrics, non-dominated candidate transfer architectures are selected to warm-start the multi-objective evolutionary algorithm for optimizing the #Acc and #Params on a new dataset. Empirical studies on NAS-Bench-Graph and five real-world datasets show that KEGNAS swiftly generates top-performance architectures, achieving 4.27% higher accuracy than advanced evolutionary baselines and 11.54% higher accuracy than advanced differentiable baselines. In addition, ablation studies demonstrate that the use of prior knowledge significantly improves the search performance.
Automatic Graph Topology-Aware Transformer
May 30, 2024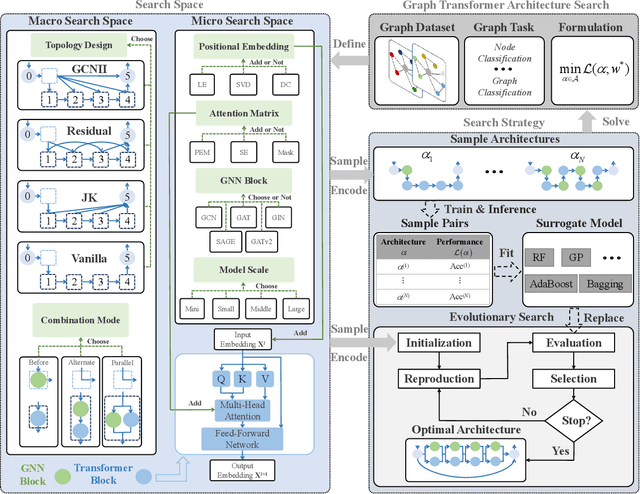
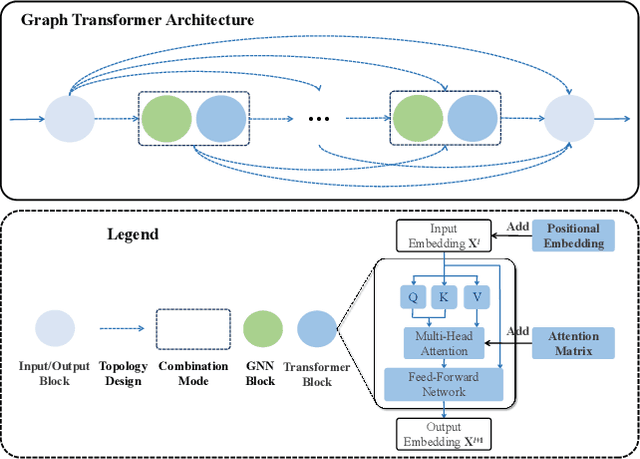
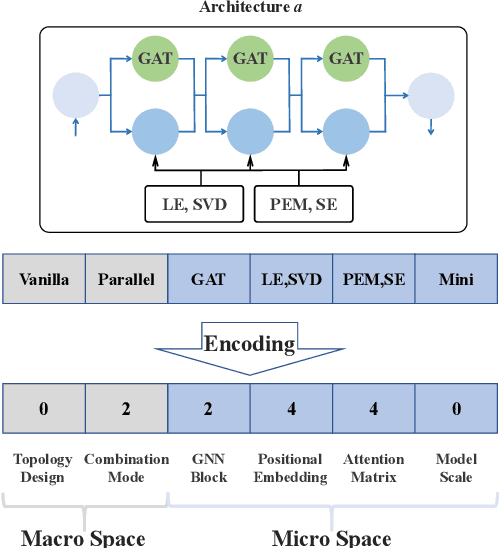
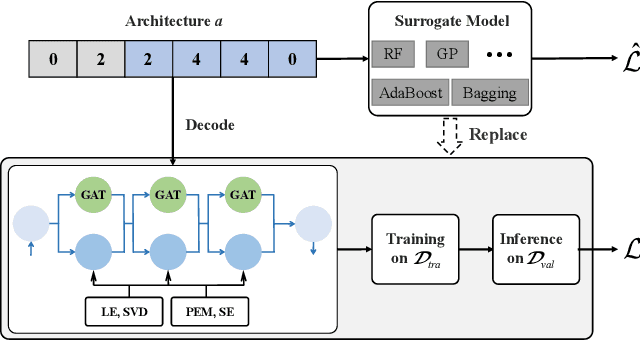
Existing efforts are dedicated to designing many topologies and graph-aware strategies for the graph Transformer, which greatly improve the model's representation capabilities. However, manually determining the suitable Transformer architecture for a specific graph dataset or task requires extensive expert knowledge and laborious trials. This paper proposes an evolutionary graph Transformer architecture search framework (EGTAS) to automate the construction of strong graph Transformers. We build a comprehensive graph Transformer search space with the micro-level and macro-level designs. EGTAS evolves graph Transformer topologies at the macro level and graph-aware strategies at the micro level. Furthermore, a surrogate model based on generic architectural coding is proposed to directly predict the performance of graph Transformers, substantially reducing the evaluation cost of evolutionary search. We demonstrate the efficacy of EGTAS across a range of graph-level and node-level tasks, encompassing both small-scale and large-scale graph datasets. Experimental results and ablation studies show that EGTAS can construct high-performance architectures that rival state-of-the-art manual and automated baselines.
A match made in consistency heaven: when large language models meet evolutionary algorithms
Jan 19, 2024Pre-trained large language models (LLMs) have powerful capabilities for generating creative natural text. Evolutionary algorithms (EAs) can discover diverse solutions to complex real-world problems. Motivated by the common collective and directionality of text sequence generation and evolution, this paper illustrates the strong consistency of LLMs and EAs, which includes multiple one-to-one key characteristics: token embedding and genotype-phenotype mapping, position encoding and fitness shaping, position embedding and selection, attention and crossover, feed-forward neural network and mutation, model training and parameter update, and multi-task learning and multi-objective optimization. Based on this consistency perspective, existing coupling studies are analyzed, including evolutionary fine-tuning and LLM-enhanced EAs. Leveraging these insights, we outline a fundamental roadmap for future research in coupling LLMs and EAs, while highlighting key challenges along the way. The consistency not only reveals the evolution mechanism behind LLMs but also facilitates the development of evolved artificial agents that approach or surpass biological organisms.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.