 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Feb 02, 2026Adaptive multimodal reasoning has emerged as a promising frontier in Vision-Language Models (VLMs), aiming to dynamically modulate between tool-augmented visual reasoning and text reasoning to enhance both effectiveness and efficiency. However, existing evaluations rely on static difficulty labels and simplistic metrics, which fail to capture the dynamic nature of difficulty relative to varying model capacities. Consequently, they obscure the distinction between adaptive mode selection and general performance while neglecting fine-grained process analyses. In this paper, we propose AdaptMMBench, a comprehensive benchmark for adaptive multimodal reasoning across five domains: real-world, OCR, GUI, knowledge, and math, encompassing both direct perception and complex reasoning tasks. AdaptMMBench utilizes a Matthews Correlation Coefficient (MCC) metric to evaluate the selection rationality of different reasoning modes, isolating this meta-cognition ability by dynamically identifying task difficulties based on models' capability boundaries. Moreover, AdaptMMBench facilitates multi-dimensional process evaluation across key step coverage, tool effectiveness, and computational efficiency. Our evaluation reveals that while adaptive mode selection scales with model capacity, it notably decouples from final accuracy. Conversely, key step coverage aligns with performance, though tool effectiveness remains highly inconsistent across model architectures.
Text-promptable Object Counting via Quantity Awareness Enhancement
Jul 09, 2025Recent advances in large vision-language models (VLMs) have shown remarkable progress in solving the text-promptable object counting problem. Representative methods typically specify text prompts with object category information in images. This however is insufficient for training the model to accurately distinguish the number of objects in the counting task. To this end, we propose QUANet, which introduces novel quantity-oriented text prompts with a vision-text quantity alignment loss to enhance the model's quantity awareness. Moreover, we propose a dual-stream adaptive counting decoder consisting of a Transformer stream, a CNN stream, and a number of Transformer-to-CNN enhancement adapters (T2C-adapters) for density map prediction. The T2C-adapters facilitate the effective knowledge communication and aggregation between the Transformer and CNN streams. A cross-stream quantity ranking loss is proposed in the end to optimize the ranking orders of predictions from the two streams. Extensive experiments on standard benchmarks such as FSC-147, CARPK, PUCPR+, and ShanghaiTech demonstrate our model's strong generalizability for zero-shot class-agnostic counting. Code is available at https://github.com/viscom-tongji/QUANet
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025
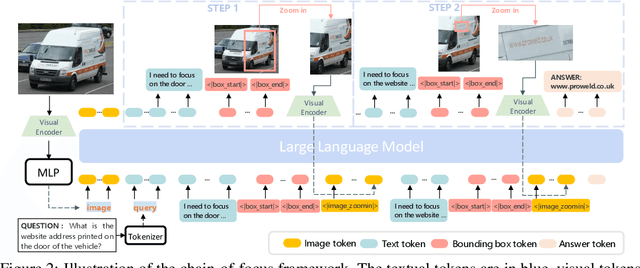


Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.
TTRD3: Texture Transfer Residual Denoising Dual Diffusion Model for Remote Sensing Image Super-Resolution
Apr 17, 2025Remote Sensing Image Super-Resolution (RSISR) reconstructs high-resolution (HR) remote sensing images from low-resolution inputs to support fine-grained ground object interpretation. Existing methods face three key challenges: (1) Difficulty in extracting multi-scale features from spatially heterogeneous RS scenes, (2) Limited prior information causing semantic inconsistency in reconstructions, and (3) Trade-off imbalance between geometric accuracy and visual quality. To address these issues, we propose the Texture Transfer Residual Denoising Dual Diffusion Model (TTRD3) with three innovations: First, a Multi-scale Feature Aggregation Block (MFAB) employing parallel heterogeneous convolutional kernels for multi-scale feature extraction. Second, a Sparse Texture Transfer Guidance (STTG) module that transfers HR texture priors from reference images of similar scenes. Third, a Residual Denoising Dual Diffusion Model (RDDM) framework combining residual diffusion for deterministic reconstruction and noise diffusion for diverse generation. Experiments on multi-source RS datasets demonstrate TTRD3's superiority over state-of-the-art methods, achieving 1.43% LPIPS improvement and 3.67% FID enhancement compared to best-performing baselines. Code/model: https://github.com/LED-666/TTRD3.
SeNM-VAE: Semi-Supervised Noise Modeling with Hierarchical Variational Autoencoder
Mar 26, 2024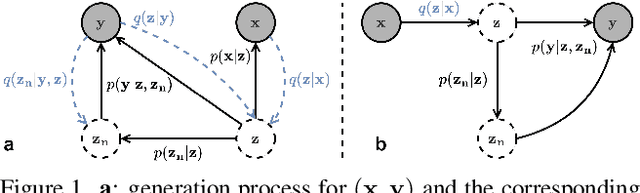
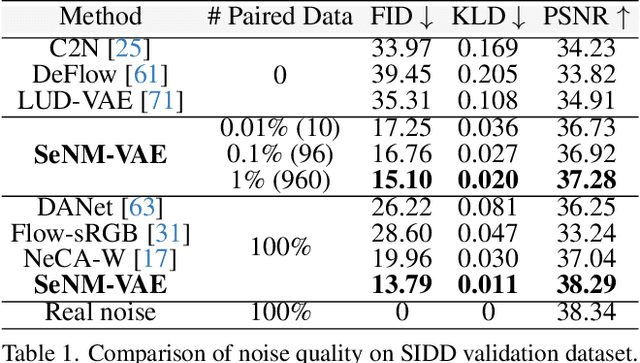
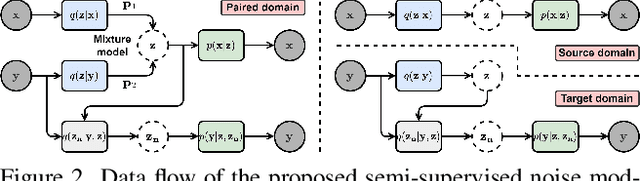
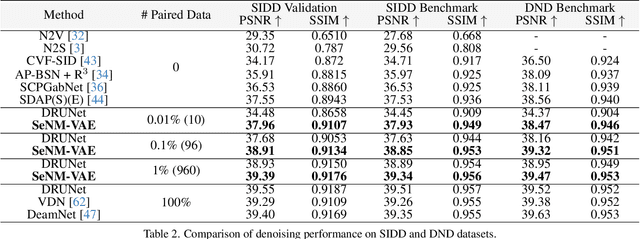
The data bottleneck has emerged as a fundamental challenge in learning based image restoration methods. Researchers have attempted to generate synthesized training data using paired or unpaired samples to address this challenge. This study proposes SeNM-VAE, a semi-supervised noise modeling method that leverages both paired and unpaired datasets to generate realistic degraded data. Our approach is based on modeling the conditional distribution of degraded and clean images with a specially designed graphical model. Under the variational inference framework, we develop an objective function for handling both paired and unpaired data. We employ our method to generate paired training samples for real-world image denoising and super-resolution tasks. Our approach excels in the quality of synthetic degraded images compared to other unpaired and paired noise modeling methods. Furthermore, our approach demonstrates remarkable performance in downstream image restoration tasks, even with limited paired data. With more paired data, our method achieves the best performance on the SIDD dataset.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
Epsilon*: Privacy Metric for Machine Learning Models
Jul 21, 2023



We introduce Epsilon*, a new privacy metric for measuring the privacy risk of a single model instance prior to, during, or after deployment of privacy mitigation strategies. The metric does not require access to the training data sampling or model training algorithm. Epsilon* is a function of true positive and false positive rates in a hypothesis test used by an adversary in a membership inference attack. We distinguish between quantifying the privacy loss of a trained model instance and quantifying the privacy loss of the training mechanism which produces this model instance. Existing approaches in the privacy auditing literature provide lower bounds for the latter, while our metric provides a lower bound for the former by relying on an (${\epsilon}$,${\delta}$)-type of quantification of the privacy of the trained model instance. We establish a relationship between these lower bounds and show how to implement Epsilon* to avoid numerical and noise amplification instability. We further show in experiments on benchmark public data sets that Epsilon* is sensitive to privacy risk mitigation by training with differential privacy (DP), where the value of Epsilon* is reduced by up to 800% compared to the Epsilon* values of non-DP trained baseline models. This metric allows privacy auditors to be independent of model owners, and enables all decision-makers to visualize the privacy-utility landscape to make informed decisions regarding the trade-offs between model privacy and utility.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022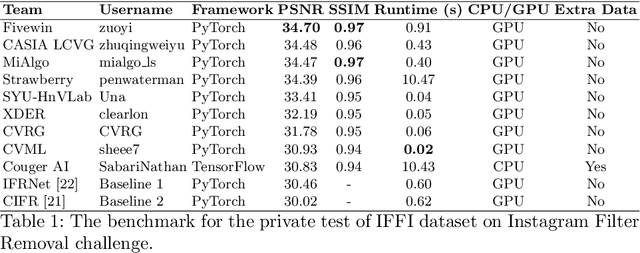

This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
EasyRec: An easy-to-use, extendable and efficient framework for building industrial recommendation systems
Sep 26, 2022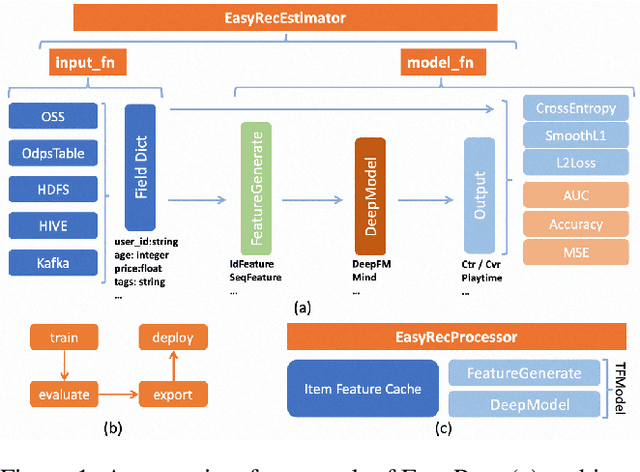
We present EasyRec, an easy-to-use, extendable and efficient recommendation framework for building industrial recommendation systems. Our EasyRec framework is superior in the following aspects: first, EasyRec adopts a modular and pluggable design pattern to reduce the efforts to build custom models; second, EasyRec implements hyper-parameter optimization and feature selection algorithms to improve model performance automatically; third, EasyRec applies online learning to fast adapt to the ever-changing data distribution. The code is released: https://github.com/alibaba/EasyRec.
Learn from Unpaired Data for Image Restoration: A Variational Bayes Approach
Apr 21, 2022



Collecting paired training data is difficult in practice, but the unpaired samples broadly exist. Current approaches aim at generating synthesized training data from the unpaired samples by exploring the relationship between the corrupted and clean data. This work proposes LUD-VAE, a deep generative method to learn the joint probability density function from data sampled from marginal distributions. Our approach is based on a carefully designed probabilistic graphical model in which the clean and corrupted data domains are conditionally independent. Using variational inference, we maximize the evidence lower bound (ELBO) to estimate the joint probability density function. Furthermore, we show that the ELBO is computable without paired samples under the inference invariant assumption. This property provides the mathematical rationale of our approach in the unpaired setting. Finally, we apply our method to real-world image denoising and super-resolution tasks and train the models using the synthetic data generated by the LUD-VAE. Experimental results validate the advantages of our method over other learnable approaches.