 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Geometry-Appearance Consistency Optimization for Sparse-View Gaussian Splatting
Mar 03, 20263D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating a back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction. Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
LocalDyGS: Multi-view Global Dynamic Scene Modeling via Adaptive Local Implicit Feature Decoupling
Jul 03, 2025Due to the complex and highly dynamic motions in the real world, synthesizing dynamic videos from multi-view inputs for arbitrary viewpoints is challenging. Previous works based on neural radiance field or 3D Gaussian splatting are limited to modeling fine-scale motion, greatly restricting their application. In this paper, we introduce LocalDyGS, which consists of two parts to adapt our method to both large-scale and fine-scale motion scenes: 1) We decompose a complex dynamic scene into streamlined local spaces defined by seeds, enabling global modeling by capturing motion within each local space. 2) We decouple static and dynamic features for local space motion modeling. A static feature shared across time steps captures static information, while a dynamic residual field provides time-specific features. These are combined and decoded to generate Temporal Gaussians, modeling motion within each local space. As a result, we propose a novel dynamic scene reconstruction framework to model highly dynamic real-world scenes more realistically. Our method not only demonstrates competitive performance on various fine-scale datasets compared to state-of-the-art (SOTA) methods, but also represents the first attempt to model larger and more complex highly dynamic scenes. Project page: https://wujh2001.github.io/LocalDyGS/.
HEPP: Hyper-efficient Perception and Planning for High-speed Obstacle Avoidance of UAVs
May 23, 2025High-speed obstacle avoidance of uncrewed aerial vehicles (UAVs) in cluttered environments is a significant challenge. Existing UAV planning and obstacle avoidance systems can only fly at moderate speeds or at high speeds over empty or sparse fields. In this article, we propose a hyper-efficient perception and planning system for the high-speed obstacle avoidance of UAVs. The system mainly consists of three modules: 1) A novel incremental robocentric mapping method with distance and gradient information, which takes 89.5% less time compared to existing methods. 2) A novel obstacle-aware topological path search method that generates multiple distinct paths. 3) An adaptive gradient-based high-speed trajectory generation method with a novel time pre-allocation algorithm. With these innovations, the system has an excellent real-time performance with only milliseconds latency in each iteration, taking 79.24% less time than existing methods at high speeds (15 m/s in cluttered environments), allowing UAVs to fly swiftly and avoid obstacles in cluttered environments. The planned trajectory of the UAV is close to the global optimum in both temporal and spatial domains. Finally, extensive validations in both simulation and real-world experiments demonstrate the effectiveness of our proposed system for high-speed navigation in cluttered environments.
HR-VILAGE-3K3M: A Human Respiratory Viral Immunization Longitudinal Gene Expression Dataset for Systems Immunity
May 19, 2025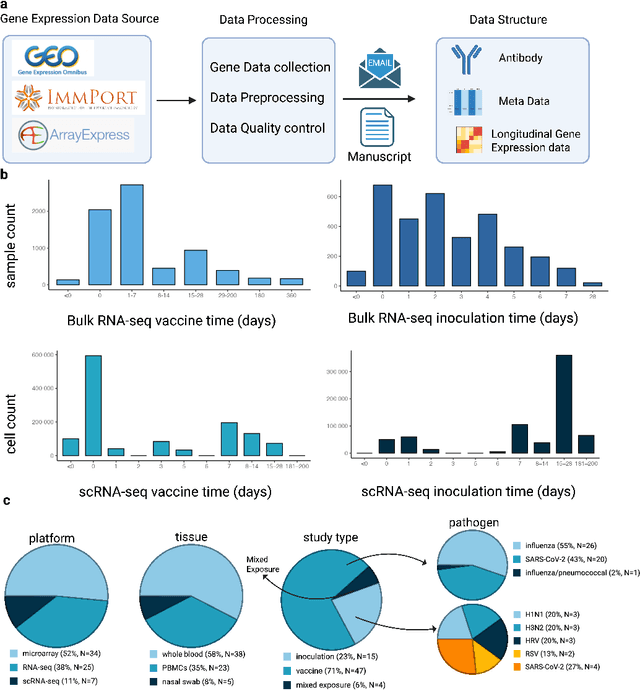



Respiratory viral infections pose a global health burden, yet the cellular immune responses driving protection or pathology remain unclear. Natural infection cohorts often lack pre-exposure baseline data and structured temporal sampling. In contrast, inoculation and vaccination trials generate insightful longitudinal transcriptomic data. However, the scattering of these datasets across platforms, along with inconsistent metadata and preprocessing procedure, hinders AI-driven discovery. To address these challenges, we developed the Human Respiratory Viral Immunization LongitudinAl Gene Expression (HR-VILAGE-3K3M) repository: an AI-ready, rigorously curated dataset that integrates 14,136 RNA-seq profiles from 3,178 subjects across 66 studies encompassing over 2.56 million cells. Spanning vaccination, inoculation, and mixed exposures, the dataset includes microarray, bulk RNA-seq, and single-cell RNA-seq from whole blood, PBMCs, and nasal swabs, sourced from GEO, ImmPort, and ArrayExpress. We harmonized subject-level metadata, standardized outcome measures, applied unified preprocessing pipelines with rigorous quality control, and aligned all data to official gene symbols. To demonstrate the utility of HR-VILAGE-3K3M, we performed predictive modeling of vaccine responders and evaluated batch-effect correction methods. Beyond these initial demonstrations, it supports diverse systems immunology applications and benchmarking of feature selection and transfer learning algorithms. Its scale and heterogeneity also make it ideal for pretraining foundation models of the human immune response and for advancing multimodal learning frameworks. As the largest longitudinal transcriptomic resource for human respiratory viral immunization, it provides an accessible platform for reproducible AI-driven research, accelerating systems immunology and vaccine development against emerging viral threats.
Any-to-Any Learning in Computational Pathology via Triplet Multimodal Pretraining
May 19, 2025



Recent advances in computational pathology and artificial intelligence have significantly enhanced the utilization of gigapixel whole-slide images and and additional modalities (e.g., genomics) for pathological diagnosis. Although deep learning has demonstrated strong potential in pathology, several key challenges persist: (1) fusing heterogeneous data types requires sophisticated strategies beyond simple concatenation due to high computational costs; (2) common scenarios of missing modalities necessitate flexible strategies that allow the model to learn robustly in the absence of certain modalities; (3) the downstream tasks in CPath are diverse, ranging from unimodal to multimodal, cnecessitating a unified model capable of handling all modalities. To address these challenges, we propose ALTER, an any-to-any tri-modal pretraining framework that integrates WSIs, genomics, and pathology reports. The term "any" emphasizes ALTER's modality-adaptive design, enabling flexible pretraining with any subset of modalities, and its capacity to learn robust, cross-modal representations beyond WSI-centric approaches. We evaluate ALTER across extensive clinical tasks including survival prediction, cancer subtyping, gene mutation prediction, and report generation, achieving superior or comparable performance to state-of-the-art baselines.
Swift4D:Adaptive divide-and-conquer Gaussian Splatting for compact and efficient reconstruction of dynamic scene
Mar 16, 2025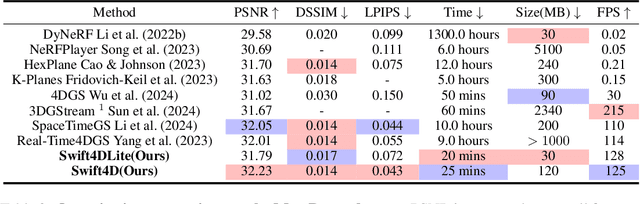
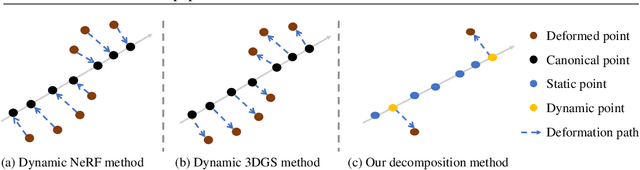
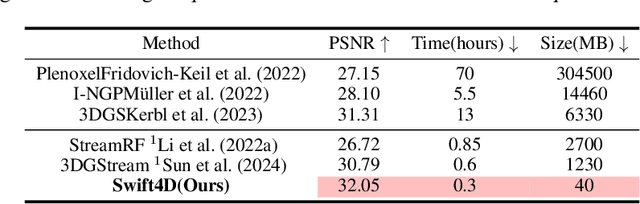
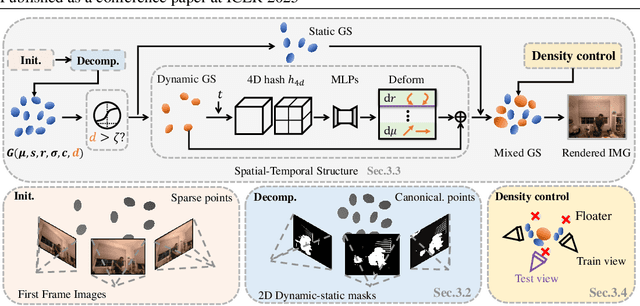
Novel view synthesis has long been a practical but challenging task, although the introduction of numerous methods to solve this problem, even combining advanced representations like 3D Gaussian Splatting, they still struggle to recover high-quality results and often consume too much storage memory and training time. In this paper we propose Swift4D, a divide-and-conquer 3D Gaussian Splatting method that can handle static and dynamic primitives separately, achieving a good trade-off between rendering quality and efficiency, motivated by the fact that most of the scene is the static primitive and does not require additional dynamic properties. Concretely, we focus on modeling dynamic transformations only for the dynamic primitives which benefits both efficiency and quality. We first employ a learnable decomposition strategy to separate the primitives, which relies on an additional parameter to classify primitives as static or dynamic. For the dynamic primitives, we employ a compact multi-resolution 4D Hash mapper to transform these primitives from canonical space into deformation space at each timestamp, and then mix the static and dynamic primitives to produce the final output. This divide-and-conquer method facilitates efficient training and reduces storage redundancy. Our method not only achieves state-of-the-art rendering quality while being 20X faster in training than previous SOTA methods with a minimum storage requirement of only 30MB on real-world datasets. Code is available at https://github.com/WuJH2001/swift4d.
CL-MVSNet: Unsupervised Multi-view Stereo with Dual-level Contrastive Learning
Mar 11, 2025
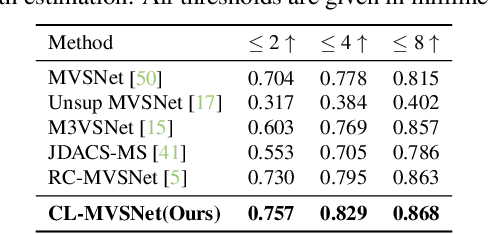
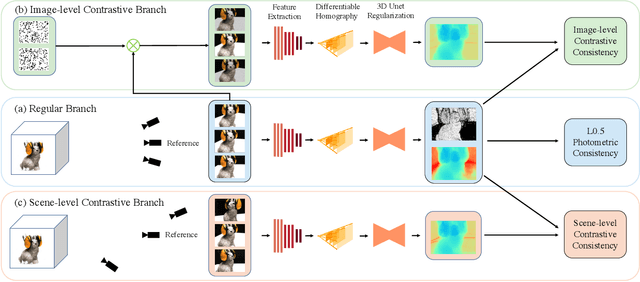
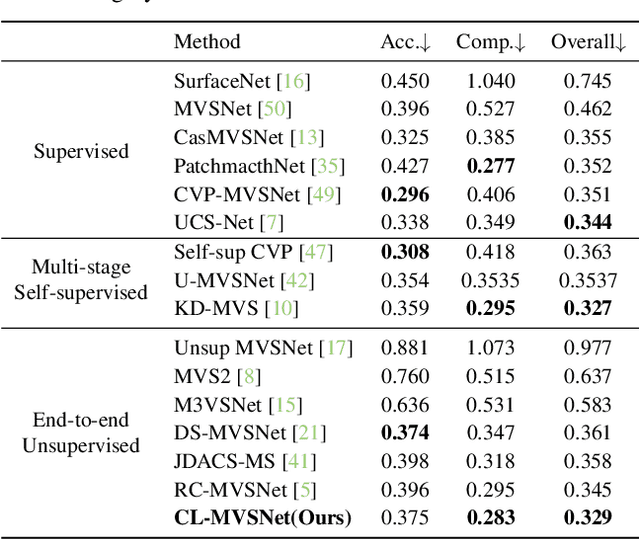
Unsupervised Multi-View Stereo (MVS) methods have achieved promising progress recently. However, previous methods primarily depend on the photometric consistency assumption, which may suffer from two limitations: indistinguishable regions and view-dependent effects, e.g., low-textured areas and reflections. To address these issues, in this paper, we propose a new dual-level contrastive learning approach, named CL-MVSNet. Specifically, our model integrates two contrastive branches into an unsupervised MVS framework to construct additional supervisory signals. On the one hand, we present an image-level contrastive branch to guide the model to acquire more context awareness, thus leading to more complete depth estimation in indistinguishable regions. On the other hand, we exploit a scene-level contrastive branch to boost the representation ability, improving robustness to view-dependent effects. Moreover, to recover more accurate 3D geometry, we introduce an L0.5 photometric consistency loss, which encourages the model to focus more on accurate points while mitigating the gradient penalty of undesirable ones. Extensive experiments on DTU and Tanks&Temples benchmarks demonstrate that our approach achieves state-of-the-art performance among all end-to-end unsupervised MVS frameworks and outperforms its supervised counterpart by a considerable margin without fine-tuning.
4D Gaussian Splatting with Scale-aware Residual Field and Adaptive Optimization for Real-time Rendering of Temporally Complex Dynamic Scenes
Dec 09, 2024



Reconstructing dynamic scenes from video sequences is a highly promising task in the multimedia domain. While previous methods have made progress, they often struggle with slow rendering and managing temporal complexities such as significant motion and object appearance/disappearance. In this paper, we propose SaRO-GS as a novel dynamic scene representation capable of achieving real-time rendering while effectively handling temporal complexities in dynamic scenes. To address the issue of slow rendering speed, we adopt a Gaussian primitive-based representation and optimize the Gaussians in 4D space, which facilitates real-time rendering with the assistance of 3D Gaussian Splatting. Additionally, to handle temporally complex dynamic scenes, we introduce a Scale-aware Residual Field. This field considers the size information of each Gaussian primitive while encoding its residual feature and aligns with the self-splitting behavior of Gaussian primitives. Furthermore, we propose an Adaptive Optimization Schedule, which assigns different optimization strategies to Gaussian primitives based on their distinct temporal properties, thereby expediting the reconstruction of dynamic regions. Through evaluations on monocular and multi-view datasets, our method has demonstrated state-of-the-art performance. Please see our project page at https://yjb6.github.io/SaRO-GS.github.io.
Structure Consistent Gaussian Splatting with Matching Prior for Few-shot Novel View Synthesis
Nov 06, 2024



Despite the substantial progress of novel view synthesis, existing methods, either based on the Neural Radiance Fields (NeRF) or more recently 3D Gaussian Splatting (3DGS), suffer significant degradation when the input becomes sparse. Numerous efforts have been introduced to alleviate this problem, but they still struggle to synthesize satisfactory results efficiently, especially in the large scene. In this paper, we propose SCGaussian, a Structure Consistent Gaussian Splatting method using matching priors to learn 3D consistent scene structure. Considering the high interdependence of Gaussian attributes, we optimize the scene structure in two folds: rendering geometry and, more importantly, the position of Gaussian primitives, which is hard to be directly constrained in the vanilla 3DGS due to the non-structure property. To achieve this, we present a hybrid Gaussian representation. Besides the ordinary non-structure Gaussian primitives, our model also consists of ray-based Gaussian primitives that are bound to matching rays and whose optimization of their positions is restricted along the ray. Thus, we can utilize the matching correspondence to directly enforce the position of these Gaussian primitives to converge to the surface points where rays intersect. Extensive experiments on forward-facing, surrounding, and complex large scenes show the effectiveness of our approach with state-of-the-art performance and high efficiency. Code is available at https://github.com/prstrive/SCGaussian.