 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeCaMIL: Causality-Aware Multiple Instance Learning for Fair and Interpretable Whole Slide Image Diagnosis
Nov 14, 2025Multiple instance learning (MIL) has emerged as the dominant paradigm for whole slide image (WSI) analysis in computational pathology, achieving strong diagnostic performance through patch-level feature aggregation. However, existing MIL methods face critical limitations: (1) they rely on attention mechanisms that lack causal interpretability, and (2) they fail to integrate patient demographics (age, gender, race), leading to fairness concerns across diverse populations. These shortcomings hinder clinical translation, where algorithmic bias can exacerbate health disparities. We introduce \textbf{MeCaMIL}, a causality-aware MIL framework that explicitly models demographic confounders through structured causal graphs. Unlike prior approaches treating demographics as auxiliary features, MeCaMIL employs principled causal inference -- leveraging do-calculus and collider structures -- to disentangle disease-relevant signals from spurious demographic correlations. Extensive evaluation on three benchmarks demonstrates state-of-the-art performance across CAMELYON16 (ACC/AUC/F1: 0.939/0.983/0.946), TCGA-Lung (0.935/0.979/0.931), and TCGA-Multi (0.977/0.993/0.970, five cancer types). Critically, MeCaMIL achieves superior fairness -- demographic disparity variance drops by over 65% relative reduction on average across attributes, with notable improvements for underserved populations. The framework generalizes to survival prediction (mean C-index: 0.653, +0.017 over best baseline across five cancer types). Ablation studies confirm causal graph structure is essential -- alternative designs yield 0.048 lower accuracy and 4.2x times worse fairness. These results establish MeCaMIL as a principled framework for fair, interpretable, and clinically actionable AI in digital pathology. Code will be released upon acceptance.
Two-Stage Decoupling Framework for Variable-Length Glaucoma Prognosis
Sep 15, 2025Glaucoma is one of the leading causes of irreversible blindness worldwide. Glaucoma prognosis is essential for identifying at-risk patients and enabling timely intervention to prevent blindness. Many existing approaches rely on historical sequential data but are constrained by fixed-length inputs, limiting their flexibility. Additionally, traditional glaucoma prognosis methods often employ end-to-end models, which struggle with the limited size of glaucoma datasets. To address these challenges, we propose a Two-Stage Decoupling Framework (TSDF) for variable-length glaucoma prognosis. In the first stage, we employ a feature representation module that leverages self-supervised learning to aggregate multiple glaucoma datasets for training, disregarding differences in their supervisory information. This approach enables datasets of varying sizes to learn better feature representations. In the second stage, we introduce a temporal aggregation module that incorporates an attention-based mechanism to process sequential inputs of varying lengths, ensuring flexible and efficient utilization of all available data. This design significantly enhances model performance while maintaining a compact parameter size. Extensive experiments on two benchmark glaucoma datasets:the Ocular Hypertension Treatment Study (OHTS) and the Glaucoma Real-world Appraisal Progression Ensemble (GRAPE),which differ significantly in scale and clinical settings,demonstrate the effectiveness and robustness of our approach.
HR-VILAGE-3K3M: A Human Respiratory Viral Immunization Longitudinal Gene Expression Dataset for Systems Immunity
May 19, 2025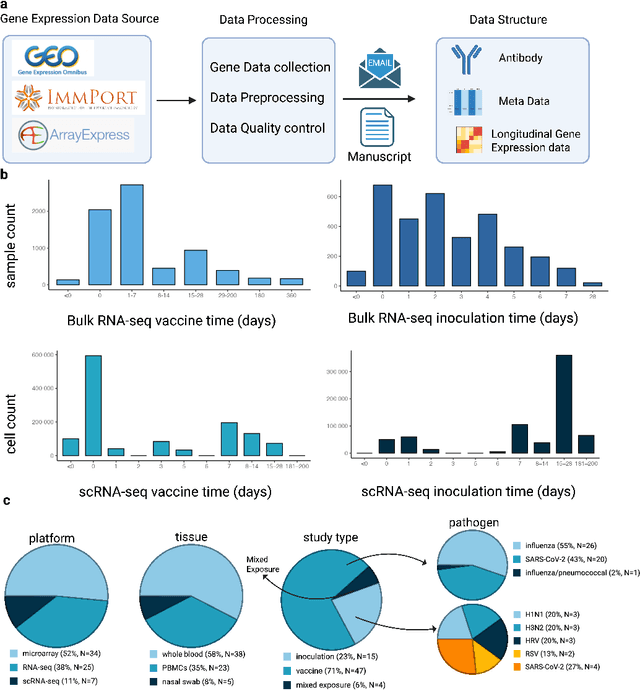



Respiratory viral infections pose a global health burden, yet the cellular immune responses driving protection or pathology remain unclear. Natural infection cohorts often lack pre-exposure baseline data and structured temporal sampling. In contrast, inoculation and vaccination trials generate insightful longitudinal transcriptomic data. However, the scattering of these datasets across platforms, along with inconsistent metadata and preprocessing procedure, hinders AI-driven discovery. To address these challenges, we developed the Human Respiratory Viral Immunization LongitudinAl Gene Expression (HR-VILAGE-3K3M) repository: an AI-ready, rigorously curated dataset that integrates 14,136 RNA-seq profiles from 3,178 subjects across 66 studies encompassing over 2.56 million cells. Spanning vaccination, inoculation, and mixed exposures, the dataset includes microarray, bulk RNA-seq, and single-cell RNA-seq from whole blood, PBMCs, and nasal swabs, sourced from GEO, ImmPort, and ArrayExpress. We harmonized subject-level metadata, standardized outcome measures, applied unified preprocessing pipelines with rigorous quality control, and aligned all data to official gene symbols. To demonstrate the utility of HR-VILAGE-3K3M, we performed predictive modeling of vaccine responders and evaluated batch-effect correction methods. Beyond these initial demonstrations, it supports diverse systems immunology applications and benchmarking of feature selection and transfer learning algorithms. Its scale and heterogeneity also make it ideal for pretraining foundation models of the human immune response and for advancing multimodal learning frameworks. As the largest longitudinal transcriptomic resource for human respiratory viral immunization, it provides an accessible platform for reproducible AI-driven research, accelerating systems immunology and vaccine development against emerging viral threats.
Continually Evolved Multimodal Foundation Models for Cancer Prognosis
Jan 30, 2025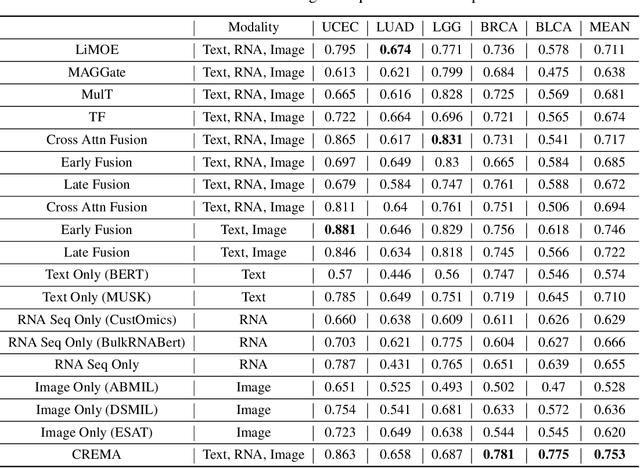
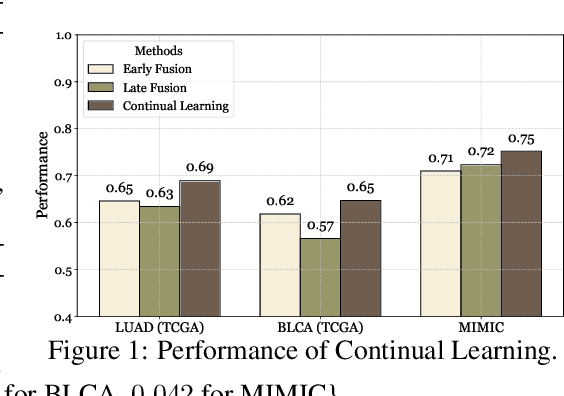
Cancer prognosis is a critical task that involves predicting patient outcomes and survival rates. To enhance prediction accuracy, previous studies have integrated diverse data modalities, such as clinical notes, medical images, and genomic data, leveraging their complementary information. However, existing approaches face two major limitations. First, they struggle to incorporate newly arrived data with varying distributions into training, such as patient records from different hospitals, thus rendering sub-optimal generalizability and limited utility in real-world applications. Second, most multimodal integration methods rely on simplistic concatenation or task-specific pipelines, which fail to capture the complex interdependencies across modalities. To address these, we propose a continually evolving multi-modal foundation model. Extensive experiments on the TCGA dataset demonstrate the effectiveness of our approach, highlighting its potential to advance cancer prognosis by enabling robust and adaptive multimodal integration.
Source-Free Test-Time Adaptation For Online Surface-Defect Detection
Aug 18, 2024Surface defect detection is significant in industrial production. However, detecting defects with varying textures and anomaly classes during the test time is challenging. This arises due to the differences in data distributions between source and target domains. Collecting and annotating new data from the target domain and retraining the model is time-consuming and costly. In this paper, we propose a novel test-time adaptation surface-defect detection approach that adapts pre-trained models to new domains and classes during inference. Our approach involves two core ideas. Firstly, we introduce a supervisor to filter samples and select only those with high confidence to update the model. This ensures that the model is not excessively biased by incorrect data. Secondly, we propose the augmented mean prediction to generate robust pseudo labels and a dynamically-balancing loss to facilitate the model in effectively integrating classification and segmentation results to improve surface-defect detection accuracy. Our approach is real-time and does not require additional offline retraining. Experiments demonstrate it outperforms state-of-the-art techniques.
SimAda: A Simple Unified Framework for Adapting Segment Anything Model in Underperformed Scenes
Jan 31, 2024



Segment anything model (SAM) has demonstrated excellent generalization capabilities in common vision scenarios, yet lacking an understanding of specialized data. Although numerous works have focused on optimizing SAM for downstream tasks, these task-specific approaches usually limit the generalizability to other downstream tasks. In this paper, we aim to investigate the impact of the general vision modules on finetuning SAM and enable them to generalize across all downstream tasks. We propose a simple unified framework called SimAda for adapting SAM in underperformed scenes. Specifically, our framework abstracts the general modules of different methods into basic design elements, and we design four variants based on a shared theoretical framework. SimAda is simple yet effective, which removes all dataset-specific designs and focuses solely on general optimization, ensuring that SimAda can be applied to all SAM-based and even Transformer-based models. We conduct extensive experiments on nine datasets of six downstream tasks. The results demonstrate that SimAda significantly improves the performance of SAM on multiple downstream tasks and achieves state-of-the-art performance on most of them, without requiring task-specific designs. Code is available at: https://github.com/zongzi13545329/SimAda
BA-SAM: Scalable Bias-Mode Attention Mask for Segment Anything Model
Jan 08, 2024



In this paper, we address the challenge of image resolution variation for the Segment Anything Model (SAM). SAM, known for its zero-shot generalizability, exhibits a performance degradation when faced with datasets with varying image sizes. Previous approaches tend to resize the image to a fixed size or adopt structure modifications, hindering the preservation of SAM's rich prior knowledge. Besides, such task-specific tuning necessitates a complete retraining of the model, which is cost-expensive and unacceptable for deployment in the downstream tasks. In this paper, we reformulate this issue as a length extrapolation problem, where token sequence length varies while maintaining a consistent patch size for images of different sizes. To this end, we propose Scalable Bias-Mode Attention Mask (BA-SAM) to enhance SAM's adaptability to varying image resolutions while eliminating the need for structure modifications. Firstly, we introduce a new scaling factor to ensure consistent magnitude in the attention layer's dot product values when the token sequence length changes. Secondly, we present a bias-mode attention mask that allows each token to prioritize neighboring information, mitigating the impact of untrained distant information. Our BA-SAM demonstrates efficacy in two scenarios: zero-shot and fine-tuning. Extensive evaluation on diverse datasets, including DIS5K, DUTS, ISIC, COD10K, and COCO, reveals its ability to significantly mitigate performance degradation in the zero-shot setting and achieve state-of-the-art performance with minimal fine-tuning. Furthermore, we propose a generalized model and benchmark, showcasing BA-SAM's generalizability across all four datasets simultaneously.
Rethinking Implicit Neural Representations for Vision Learners
Nov 23, 2022Implicit Neural Representations (INRs) are powerful to parameterize continuous signals in computer vision. However, almost all INRs methods are limited to low-level tasks, e.g., image/video compression, super-resolution, and image generation. The questions on how to explore INRs to high-level tasks and deep networks are still under-explored. Existing INRs methods suffer from two problems: 1) narrow theoretical definitions of INRs are inapplicable to high-level tasks; 2) lack of representation capabilities to deep networks. Motivated by the above facts, we reformulate the definitions of INRs from a novel perspective and propose an innovative Implicit Neural Representation Network (INRN), which is the first study of INRs to tackle both low-level and high-level tasks. Specifically, we present three key designs for basic blocks in INRN along with two different stacking ways and corresponding loss functions. Extensive experiments with analysis on both low-level tasks (image fitting) and high-level vision tasks (image classification, object detection, instance segmentation) demonstrate the effectiveness of the proposed method.
See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
Aug 26, 2022
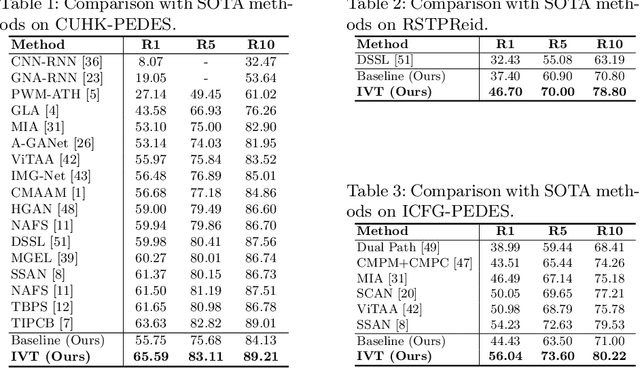
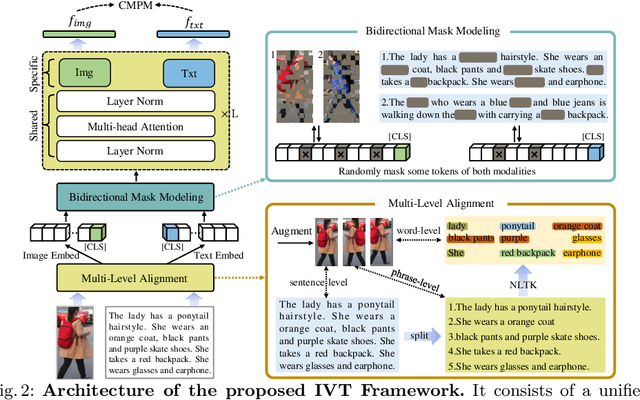

Text-based person retrieval aims to find the query person based on a textual description. The key is to learn a common latent space mapping between visual-textual modalities. To achieve this goal, existing works employ segmentation to obtain explicitly cross-modal alignments or utilize attention to explore salient alignments. These methods have two shortcomings: 1) Labeling cross-modal alignments are time-consuming. 2) Attention methods can explore salient cross-modal alignments but may ignore some subtle and valuable pairs. To relieve these issues, we introduce an Implicit Visual-Textual (IVT) framework for text-based person retrieval. Different from previous models, IVT utilizes a single network to learn representation for both modalities, which contributes to the visual-textual interaction. To explore the fine-grained alignment, we further propose two implicit semantic alignment paradigms: multi-level alignment (MLA) and bidirectional mask modeling (BMM). The MLA module explores finer matching at sentence, phrase, and word levels, while the BMM module aims to mine \textbf{more} semantic alignments between visual and textual modalities. Extensive experiments are carried out to evaluate the proposed IVT on public datasets, i.e., CUHK-PEDES, RSTPReID, and ICFG-PEDES. Even without explicit body part alignment, our approach still achieves state-of-the-art performance. Code is available at: https://github.com/TencentYoutuResearch/PersonRetrieval-IVT.