 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSHA: A Benchmark for Visual Language Models in Trustworthy Safety Hazard Assessment Scenarios
Mar 31, 2026Recent advances in vision-language models (VLMs) have accelerated their application to indoor safety hazards assessment. However, existing benchmarks suffer from three fundamental limitations: (1) heavy reliance on synthetic datasets constructed via simulation software, creating a significant domain gap with real-world environments; (2) oversimplified safety tasks with artificial constraints on hazard and scene types, thereby limiting model generalization; and (3) absence of rigorous evaluation protocols to thoroughly assess model capabilities in complex home safety scenarios. To address these challenges, we introduce TSHA (\textbf{T}rustworthy \textbf{S}afety \textbf{H}azards \textbf{A}ssessment), a comprehensive benchmark comprising 81,809 carefully curated training samples drawn from four complementary sources: existing indoor datasets, internet images, AIGC images, and newly captured images. This benchmark set also includes a highly challenging test set with 1707 samples, comprising not only a carefully selected subset from the training distribution but also newly added videos and panoramic images containing multiple safety hazards, used to evaluate the model's robustness in complex safety scenarios. Extensive experiments on 23 popular VLMs demonstrate that current VLMs lack robust capabilities for safety hazard assessment. Importantly, models trained on the TSHA training set not only achieve a significant performance improvement of up to +18.3 points on the TSHA test set but also exhibit enhanced generalizability across other benchmarks, underscoring the substantial contribution and importance of the TSHA benchmark.
Mamba Learns in Context: Structure-Aware Domain Generalization for Multi-Task Point Cloud Understanding
Mar 21, 2026While recent Transformer and Mamba architectures have advanced point cloud representation learning, they are typically developed for single-task or single-domain settings. Directly applying them to multi-task domain generalization (DG) leads to degraded performance. Transformers effectively model global dependencies but suffer from quadratic attention cost and lack explicit structural ordering, whereas Mamba offers linear-time recurrence yet often depends on coordinate-driven serialization, which is sensitive to viewpoint changes and missing regions, causing structural drift and unstable sequential modeling. In this paper, we propose Structure-Aware Domain Generalization (SADG), a Mamba-based In-Context Learning framework that preserves structural hierarchy across domains and tasks. We design structure-aware serialization (SAS) that generates transformation-invariant sequences using centroid-based topology and geodesic curvature continuity. We further devise hierarchical domain-aware modeling (HDM) that stabilizes cross-domain reasoning by consolidating intra-domain structure and fusing inter-domain relations. At test time, we introduce a lightweight spectral graph alignment (SGA) that shifts target features toward source prototypes in the spectral domain without updating model parameters, ensuring structure-preserving test-time feature shifting. In addition, we introduce MP3DObject, a real-scan object dataset for multi-task DG evaluation. Comprehensive experiments demonstrate that the proposed approach improves structural fidelity and consistently outperforms state-of-the-art methods across multiple tasks including reconstruction, denoising, and registration.
Walking the Schrödinger Bridge: A Direct Trajectory for Text-to-3D Generation
Nov 06, 2025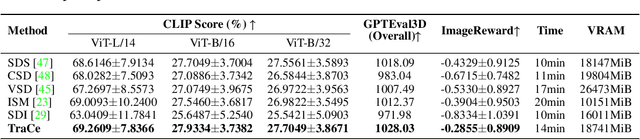
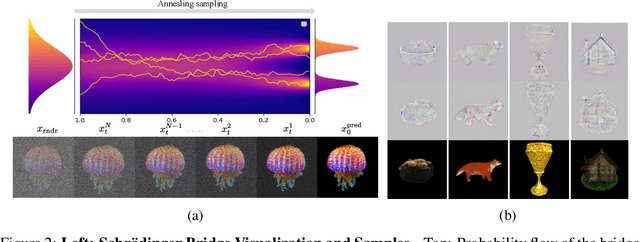

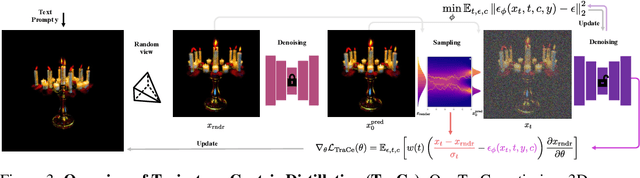
Recent advancements in optimization-based text-to-3D generation heavily rely on distilling knowledge from pre-trained text-to-image diffusion models using techniques like Score Distillation Sampling (SDS), which often introduce artifacts such as over-saturation and over-smoothing into the generated 3D assets. In this paper, we address this essential problem by formulating the generation process as learning an optimal, direct transport trajectory between the distribution of the current rendering and the desired target distribution, thereby enabling high-quality generation with smaller Classifier-free Guidance (CFG) values. At first, we theoretically establish SDS as a simplified instance of the Schrödinger Bridge framework. We prove that SDS employs the reverse process of an Schrödinger Bridge, which, under specific conditions (e.g., a Gaussian noise as one end), collapses to SDS's score function of the pre-trained diffusion model. Based upon this, we introduce Trajectory-Centric Distillation (TraCe), a novel text-to-3D generation framework, which reformulates the mathematically trackable framework of Schrödinger Bridge to explicitly construct a diffusion bridge from the current rendering to its text-conditioned, denoised target, and trains a LoRA-adapted model on this trajectory's score dynamics for robust 3D optimization. Comprehensive experiments demonstrate that TraCe consistently achieves superior quality and fidelity to state-of-the-art techniques.
PointDGRWKV: Generalizing RWKV-like Architecture to Unseen Domains for Point Cloud Classification
Aug 29, 2025



Domain Generalization (DG) has been recently explored to enhance the generalizability of Point Cloud Classification (PCC) models toward unseen domains. Prior works are based on convolutional networks, Transformer or Mamba architectures, either suffering from limited receptive fields or high computational cost, or insufficient long-range dependency modeling. RWKV, as an emerging architecture, possesses superior linear complexity, global receptive fields, and long-range dependency. In this paper, we present the first work that studies the generalizability of RWKV models in DG PCC. We find that directly applying RWKV to DG PCC encounters two significant challenges: RWKV's fixed direction token shift methods, like Q-Shift, introduce spatial distortions when applied to unstructured point clouds, weakening local geometric modeling and reducing robustness. In addition, the Bi-WKV attention in RWKV amplifies slight cross-domain differences in key distributions through exponential weighting, leading to attention shifts and degraded generalization. To this end, we propose PointDGRWKV, the first RWKV-based framework tailored for DG PCC. It introduces two key modules to enhance spatial modeling and cross-domain robustness, while maintaining RWKV's linear efficiency. In particular, we present Adaptive Geometric Token Shift to model local neighborhood structures to improve geometric context awareness. In addition, Cross-Domain key feature Distribution Alignment is designed to mitigate attention drift by aligning key feature distributions across domains. Extensive experiments on multiple benchmarks demonstrate that PointDGRWKV achieves state-of-the-art performance on DG PCC.
A Survey of Deep Learning-based Point Cloud Denoising
Aug 23, 2025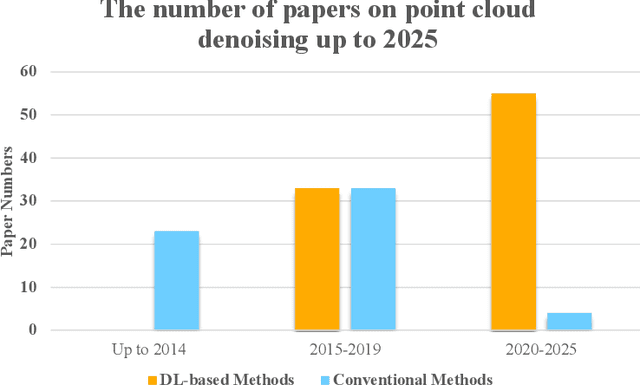
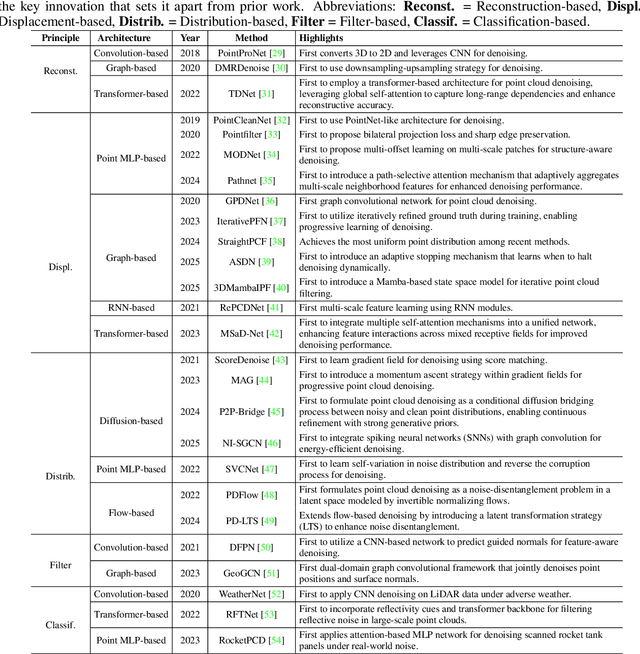
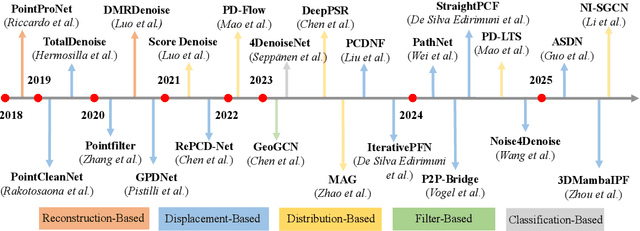

Accurate 3D geometry acquisition is essential for a wide range of applications, such as computer graphics, autonomous driving, robotics, and augmented reality. However, raw point clouds acquired in real-world environments are often corrupted with noise due to various factors such as sensor, lighting, material, environment etc, which reduces geometric fidelity and degrades downstream performance. Point cloud denoising is a fundamental problem, aiming to recover clean point sets while preserving underlying structures. Classical optimization-based methods, guided by hand-crafted filters or geometric priors, have been extensively studied but struggle to handle diverse and complex noise patterns. Recent deep learning approaches leverage neural network architectures to learn distinctive representations and demonstrate strong outcomes, particularly on complex and large-scale point clouds. Provided these significant advances, this survey provides a comprehensive and up-to-date review of deep learning-based point cloud denoising methods up to August 2025. We organize the literature from two perspectives: (1) supervision level (supervised vs. unsupervised), and (2) modeling perspective, proposing a functional taxonomy that unifies diverse approaches by their denoising principles. We further analyze architectural trends both structurally and chronologically, establish a unified benchmark with consistent training settings, and evaluate methods in terms of denoising quality, surface fidelity, point distribution, and computational efficiency. Finally, we discuss open challenges and outline directions for future research in this rapidly evolving field.
Hybrid Long and Short Range Flows for Point Cloud Filtering
Aug 12, 2025Point cloud capture processes are error-prone and introduce noisy artifacts that necessitate filtering/denoising. Recent filtering methods often suffer from point clustering or noise retaining issues. In this paper, we propose Hybrid Point Cloud Filtering ($\textbf{HybridPF}$) that considers both short-range and long-range filtering trajectories when removing noise. It is well established that short range scores, given by $\nabla_{x}\log p(x_t)$, may provide the necessary displacements to move noisy points to the underlying clean surface. By contrast, long range velocity flows approximate constant displacements directed from a high noise variant patch $x_0$ towards the corresponding clean surface $x_1$. Here, noisy patches $x_t$ are viewed as intermediate states between the high noise variant and the clean patches. Our intuition is that long range information from velocity flow models can guide the short range scores to align more closely with the clean points. In turn, score models generally provide a quicker convergence to the clean surface. Specifically, we devise two parallel modules, the ShortModule and LongModule, each consisting of an Encoder-Decoder pair to respectively account for short-range scores and long-range flows. We find that short-range scores, guided by long-range features, yield filtered point clouds with good point distributions and convergence near the clean surface. We design a joint loss function to simultaneously train the ShortModule and LongModule, in an end-to-end manner. Finally, we identify a key weakness in current displacement based methods, limitations on the decoder architecture, and propose a dynamic graph convolutional decoder to improve the inference process. Comprehensive experiments demonstrate that our HybridPF achieves state-of-the-art results while enabling faster inference speed.
MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution
Jun 17, 2025



Facial micro-expression recognition (MER) is a challenging problem, due to transient and subtle micro-expression (ME) actions. Most existing methods depend on hand-crafted features, key frames like onset, apex, and offset frames, or deep networks limited by small-scale and low-diversity datasets. In this paper, we propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data. Extensive experiments demonstrate that our framework (i) outperforms the state-of-the-art MER methods on CASME II, SAMM, and SMIC benchmarks, (ii) works well for optical flow estimation and facial landmark detection, and (iii) can capture facial subtle muscle actions in local regions associated with MEs. The code is available at https://github.com/CYF-cuber/MOL.
DiffDecompose: Layer-Wise Decomposition of Alpha-Composited Images via Diffusion Transformers
May 30, 2025Diffusion models have recently motivated great success in many generation tasks like object removal. Nevertheless, existing image decomposition methods struggle to disentangle semi-transparent or transparent layer occlusions due to mask prior dependencies, static object assumptions, and the lack of datasets. In this paper, we delve into a novel task: Layer-Wise Decomposition of Alpha-Composited Images, aiming to recover constituent layers from single overlapped images under the condition of semi-transparent/transparent alpha layer non-linear occlusion. To address challenges in layer ambiguity, generalization, and data scarcity, we first introduce AlphaBlend, the first large-scale and high-quality dataset for transparent and semi-transparent layer decomposition, supporting six real-world subtasks (e.g., translucent flare removal, semi-transparent cell decomposition, glassware decomposition). Building on this dataset, we present DiffDecompose, a diffusion Transformer-based framework that learns the posterior over possible layer decompositions conditioned on the input image, semantic prompts, and blending type. Rather than regressing alpha mattes directly, DiffDecompose performs In-Context Decomposition, enabling the model to predict one or multiple layers without per-layer supervision, and introduces Layer Position Encoding Cloning to maintain pixel-level correspondence across layers. Extensive experiments on the proposed AlphaBlend dataset and public LOGO dataset verify the effectiveness of DiffDecompose. The code and dataset will be available upon paper acceptance. Our code will be available at: https://github.com/Wangzt1121/DiffDecompose.
A Divide-and-Conquer Approach for Global Orientation of Non-Watertight Scene-Level Point Clouds Using 0-1 Integer Optimization
May 29, 2025Orienting point clouds is a fundamental problem in computer graphics and 3D vision, with applications in reconstruction, segmentation, and analysis. While significant progress has been made, existing approaches mainly focus on watertight, object-level 3D models. The orientation of large-scale, non-watertight 3D scenes remains an underexplored challenge. To address this gap, we propose DACPO (Divide-And-Conquer Point Orientation), a novel framework that leverages a divide-and-conquer strategy for scalable and robust point cloud orientation. Rather than attempting to orient an unbounded scene at once, DACPO segments the input point cloud into smaller, manageable blocks, processes each block independently, and integrates the results through a global optimization stage. For each block, we introduce a two-step process: estimating initial normal orientations by a randomized greedy method and refining them by an adapted iterative Poisson surface reconstruction. To achieve consistency across blocks, we model inter-block relationships using an an undirected graph, where nodes represent blocks and edges connect spatially adjacent blocks. To reliably evaluate orientation consistency between adjacent blocks, we introduce the concept of the visible connected region, which defines the region over which visibility-based assessments are performed. The global integration is then formulated as a 0-1 integer-constrained optimization problem, with block flip states as binary variables. Despite the combinatorial nature of the problem, DACPO remains scalable by limiting the number of blocks (typically a few hundred for 3D scenes) involved in the optimization. Experiments on benchmark datasets demonstrate DACPO's strong performance, particularly in challenging large-scale, non-watertight scenarios where existing methods often fail. The source code is available at https://github.com/zd-lee/DACPO.
Object-level Cross-view Geo-localization with Location Enhancement and Multi-Head Cross Attention
May 23, 2025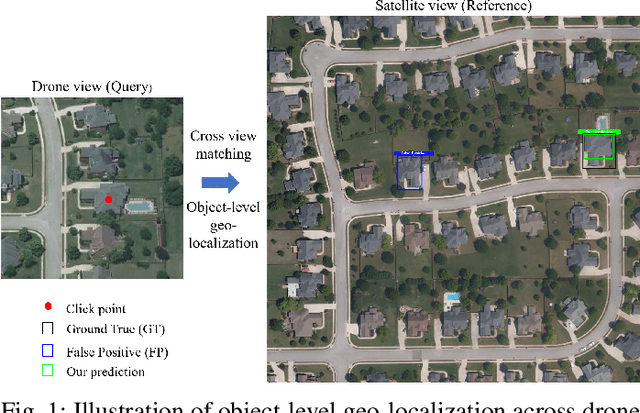
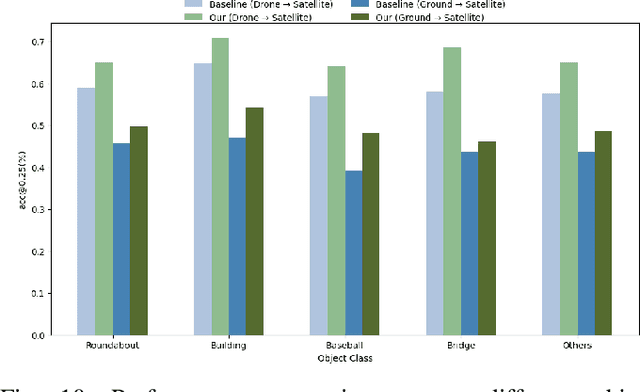
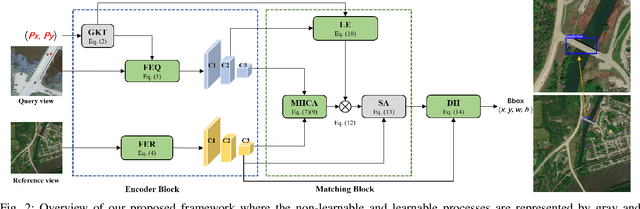
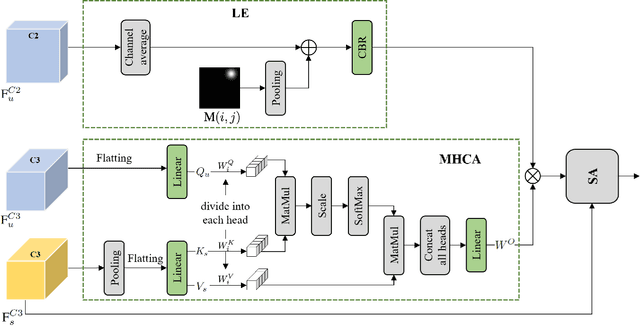
Cross-view geo-localization determines the location of a query image, captured by a drone or ground-based camera, by matching it to a geo-referenced satellite image. While traditional approaches focus on image-level localization, many applications, such as search-and-rescue, infrastructure inspection, and precision delivery, demand object-level accuracy. This enables users to prompt a specific object with a single click on a drone image to retrieve precise geo-tagged information of the object. However, variations in viewpoints, timing, and imaging conditions pose significant challenges, especially when identifying visually similar objects in extensive satellite imagery. To address these challenges, we propose an Object-level Cross-view Geo-localization Network (OCGNet). It integrates user-specified click locations using Gaussian Kernel Transfer (GKT) to preserve location information throughout the network. This cue is dually embedded into the feature encoder and feature matching blocks, ensuring robust object-specific localization. Additionally, OCGNet incorporates a Location Enhancement (LE) module and a Multi-Head Cross Attention (MHCA) module to adaptively emphasize object-specific features or expand focus to relevant contextual regions when necessary. OCGNet achieves state-of-the-art performance on a public dataset, CVOGL. It also demonstrates few-shot learning capabilities, effectively generalizing from limited examples, making it suitable for diverse applications (https://github.com/ZheyangH/OCGNet).