 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba Learns in Context: Structure-Aware Domain Generalization for Multi-Task Point Cloud Understanding
Mar 21, 2026While recent Transformer and Mamba architectures have advanced point cloud representation learning, they are typically developed for single-task or single-domain settings. Directly applying them to multi-task domain generalization (DG) leads to degraded performance. Transformers effectively model global dependencies but suffer from quadratic attention cost and lack explicit structural ordering, whereas Mamba offers linear-time recurrence yet often depends on coordinate-driven serialization, which is sensitive to viewpoint changes and missing regions, causing structural drift and unstable sequential modeling. In this paper, we propose Structure-Aware Domain Generalization (SADG), a Mamba-based In-Context Learning framework that preserves structural hierarchy across domains and tasks. We design structure-aware serialization (SAS) that generates transformation-invariant sequences using centroid-based topology and geodesic curvature continuity. We further devise hierarchical domain-aware modeling (HDM) that stabilizes cross-domain reasoning by consolidating intra-domain structure and fusing inter-domain relations. At test time, we introduce a lightweight spectral graph alignment (SGA) that shifts target features toward source prototypes in the spectral domain without updating model parameters, ensuring structure-preserving test-time feature shifting. In addition, we introduce MP3DObject, a real-scan object dataset for multi-task DG evaluation. Comprehensive experiments demonstrate that the proposed approach improves structural fidelity and consistently outperforms state-of-the-art methods across multiple tasks including reconstruction, denoising, and registration.
PMG: Progressive Motion Generation via Sparse Anchor Postures Curriculum Learning
Apr 23, 2025In computer animation, game design, and human-computer interaction, synthesizing human motion that aligns with user intent remains a significant challenge. Existing methods have notable limitations: textual approaches offer high-level semantic guidance but struggle to describe complex actions accurately; trajectory-based techniques provide intuitive global motion direction yet often fall short in generating precise or customized character movements; and anchor poses-guided methods are typically confined to synthesize only simple motion patterns. To generate more controllable and precise human motions, we propose \textbf{ProMoGen (Progressive Motion Generation)}, a novel framework that integrates trajectory guidance with sparse anchor motion control. Global trajectories ensure consistency in spatial direction and displacement, while sparse anchor motions only deliver precise action guidance without displacement. This decoupling enables independent refinement of both aspects, resulting in a more controllable, high-fidelity, and sophisticated motion synthesis. ProMoGen supports both dual and single control paradigms within a unified training process. Moreover, we recognize that direct learning from sparse motions is inherently unstable, we introduce \textbf{SAP-CL (Sparse Anchor Posture Curriculum Learning)}, a curriculum learning strategy that progressively adjusts the number of anchors used for guidance, thereby enabling more precise and stable convergence. Extensive experiments demonstrate that ProMoGen excels in synthesizing vivid and diverse motions guided by predefined trajectory and arbitrary anchor frames. Our approach seamlessly integrates personalized motion with structured guidance, significantly outperforming state-of-the-art methods across multiple control scenarios.
PCoTTA: Continual Test-Time Adaptation for Multi-Task Point Cloud Understanding
Nov 01, 2024



In this paper, we present PCoTTA, an innovative, pioneering framework for Continual Test-Time Adaptation (CoTTA) in multi-task point cloud understanding, enhancing the model's transferability towards the continually changing target domain. We introduce a multi-task setting for PCoTTA, which is practical and realistic, handling multiple tasks within one unified model during the continual adaptation. Our PCoTTA involves three key components: automatic prototype mixture (APM), Gaussian Splatted feature shifting (GSFS), and contrastive prototype repulsion (CPR). Firstly, APM is designed to automatically mix the source prototypes with the learnable prototypes with a similarity balancing factor, avoiding catastrophic forgetting. Then, GSFS dynamically shifts the testing sample toward the source domain, mitigating error accumulation in an online manner. In addition, CPR is proposed to pull the nearest learnable prototype close to the testing feature and push it away from other prototypes, making each prototype distinguishable during the adaptation. Experimental comparisons lead to a new benchmark, demonstrating PCoTTA's superiority in boosting the model's transferability towards the continually changing target domain.
Preserving Empirical Probabilities in BERT for Small-sample Clinical Entity Recognition
Sep 05, 2024



Named Entity Recognition (NER) encounters the challenge of unbalanced labels, where certain entity types are overrepresented while others are underrepresented in real-world datasets. This imbalance can lead to biased models that perform poorly on minority entity classes, impeding accurate and equitable entity recognition. This paper explores the effects of unbalanced entity labels of the BERT-based pre-trained model. We analyze the different mechanisms of loss calculation and loss propagation for the task of token classification on randomized datasets. Then we propose ways to improve the token classification for the highly imbalanced task of clinical entity recognition.
DG-PIC: Domain Generalized Point-In-Context Learning for Point Cloud Understanding
Jul 11, 2024
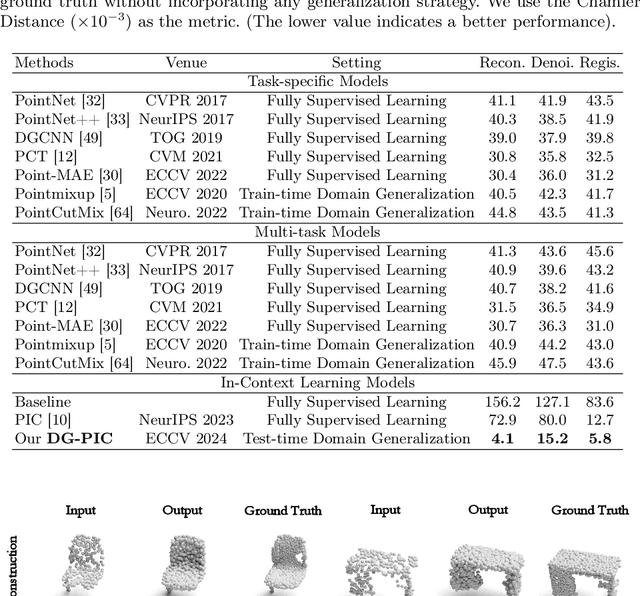
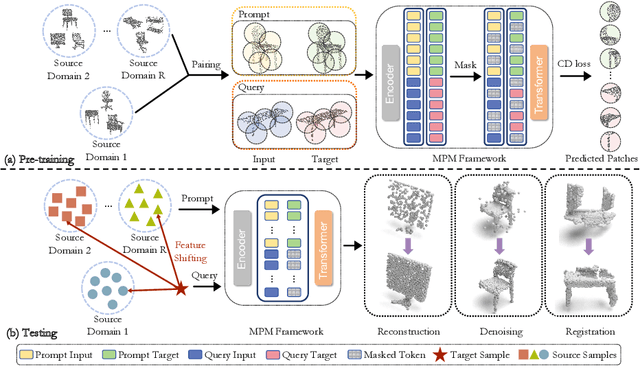

Recent point cloud understanding research suffers from performance drops on unseen data, due to the distribution shifts across different domains. While recent studies use Domain Generalization (DG) techniques to mitigate this by learning domain-invariant features, most are designed for a single task and neglect the potential of testing data. Despite In-Context Learning (ICL) showcasing multi-task learning capability, it usually relies on high-quality context-rich data and considers a single dataset, and has rarely been studied in point cloud understanding. In this paper, we introduce a novel, practical, multi-domain multi-task setting, handling multiple domains and multiple tasks within one unified model for domain generalized point cloud understanding. To this end, we propose Domain Generalized Point-In-Context Learning (DG-PIC) that boosts the generalizability across various tasks and domains at testing time. In particular, we develop dual-level source prototype estimation that considers both global-level shape contextual and local-level geometrical structures for representing source domains and a dual-level test-time feature shifting mechanism that leverages both macro-level domain semantic information and micro-level patch positional relationships to pull the target data closer to the source ones during the testing. Our DG-PIC does not require any model updates during the testing and can handle unseen domains and multiple tasks, \textit{i.e.,} point cloud reconstruction, denoising, and registration, within one unified model. We also introduce a benchmark for this new setting. Comprehensive experiments demonstrate that DG-PIC outperforms state-of-the-art techniques significantly.
MaSkel: A Model for Human Whole-body X-rays Generation from Human Masking Images
Apr 13, 2024The human whole-body X-rays could offer a valuable reference for various applications, including medical diagnostics, digital animation modeling, and ergonomic design. The traditional method of obtaining X-ray information requires the use of CT (Computed Tomography) scan machines, which emit potentially harmful radiation. Thus it faces a significant limitation for realistic applications because it lacks adaptability and safety. In our work, We proposed a new method to directly generate the 2D human whole-body X-rays from the human masking images. The predicted images will be similar to the real ones with the same image style and anatomic structure. We employed a data-driven strategy. By leveraging advanced generative techniques, our model MaSkel(Masking image to Skeleton X-rays) could generate a high-quality X-ray image from a human masking image without the need for invasive and harmful radiation exposure, which not only provides a new path to generate highly anatomic and customized data but also reduces health risks. To our knowledge, our model MaSkel is the first work for predicting whole-body X-rays. In this paper, we did two parts of the work. The first one is to solve the data limitation problem, the diffusion-based techniques are utilized to make a data augmentation, which provides two synthetic datasets for preliminary pretraining. Then we designed a two-stage training strategy to train MaSkel. At last, we make qualitative and quantitative evaluations of the generated X-rays. In addition, we invite some professional doctors to assess our predicted data. These evaluations demonstrate the MaSkel's superior ability to generate anatomic X-rays from human masking images. The related code and links of the dataset are available at https://github.com/2022yingjie/MaSkel.
CLARA: Multilingual Contrastive Learning for Audio Representation Acquisition
Nov 01, 2023Multilingual speech processing requires understanding emotions, a task made difficult by limited labelled data. CLARA, minimizes reliance on labelled data, enhancing generalization across languages. It excels at fostering shared representations, aiding cross-lingual transfer of speech and emotions, even with little data. Our approach adeptly captures emotional nuances in speech, overcoming subjective assessment issues. Using a large multilingual audio corpus and self-supervised learning, CLARA develops speech representations enriched with emotions, advancing emotion-aware multilingual speech processing. Our method expands the data range using data augmentation, textual embedding for visual understanding, and transfers knowledge from high- to low-resource languages. CLARA demonstrates excellent performance in emotion recognition, language comprehension, and audio benchmarks, excelling in zero-shot and few-shot learning. It adapts to low-resource languages, marking progress in multilingual speech representation learning.
EMNS /Imz/ Corpus: An emotive single-speaker dataset for narrative storytelling in games, television and graphic novels
May 25, 2023The increasing adoption of text-to-speech technologies has led to a growing demand for natural and emotive voices that adapt to a conversation's context and emotional tone. The Emotive Narrative Storytelling (EMNS) corpus is a unique speech dataset created to enhance conversations' expressiveness and emotive quality in interactive narrative-driven systems. The corpus consists of a 2.3-hour recording featuring a female speaker delivering labelled utterances. It encompasses eight acted emotional states, evenly distributed with a variance of 0.68%, along with expressiveness levels and natural language descriptions with word emphasis labels. The evaluation of audio samples from different datasets revealed that the EMNS corpus achieved the highest average scores in accurately conveying emotions and demonstrating expressiveness. It outperformed other datasets in conveying shared emotions and achieved comparable levels of genuineness. A classification task confirmed the accurate representation of intended emotions in the corpus, with participants recognising the recordings as genuine and expressive. Additionally, the availability of the dataset collection tool under the Apache 2.0 License simplifies remote speech data collection for researchers.
Surgical Instruction Generation with Transformers
Jul 16, 2021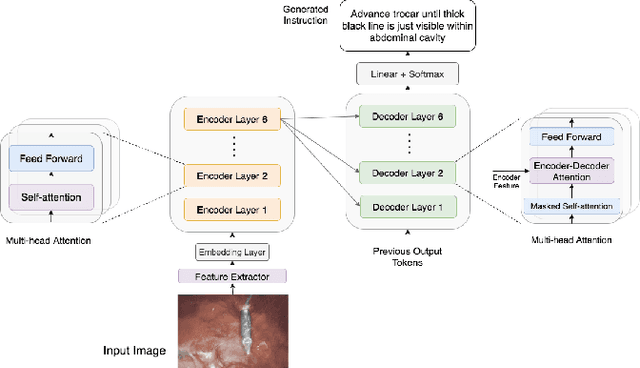
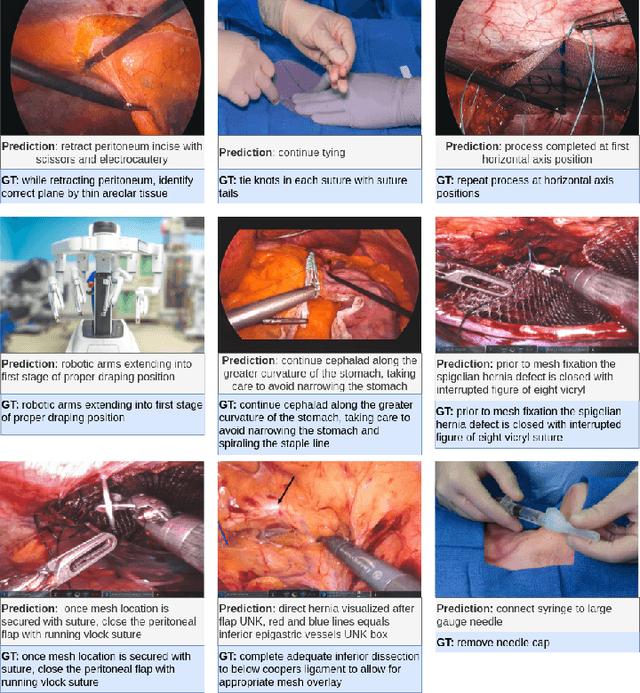
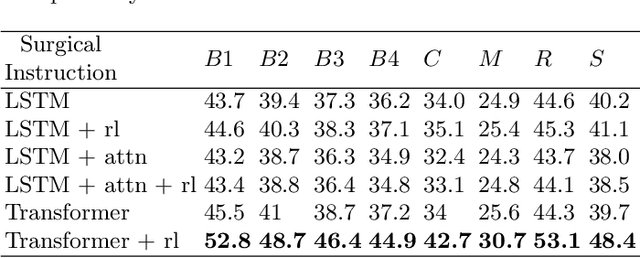
Automatic surgical instruction generation is a prerequisite towards intra-operative context-aware surgical assistance. However, generating instructions from surgical scenes is challenging, as it requires jointly understanding the surgical activity of current view and modelling relationships between visual information and textual description. Inspired by the neural machine translation and imaging captioning tasks in open domain, we introduce a transformer-backboned encoder-decoder network with self-critical reinforcement learning to generate instructions from surgical images. We evaluate the effectiveness of our method on DAISI dataset, which includes 290 procedures from various medical disciplines. Our approach outperforms the existing baseline over all caption evaluation metrics. The results demonstrate the benefits of the encoder-decoder structure backboned by transformer in handling multimodal context.
Skeleton-bridged Point Completion: From Global Inference to Local Adjustment
Oct 14, 2020
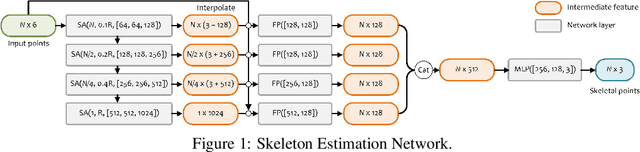

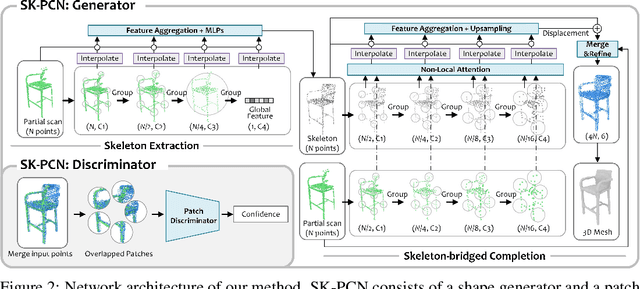
Point completion refers to complete the missing geometries of objects from partial point clouds. Existing works usually estimate the missing shape by decoding a latent feature encoded from the input points. However, real-world objects are usually with diverse topologies and surface details, which a latent feature may fail to represent to recover a clean and complete surface. To this end, we propose a skeleton-bridged point completion network (SK-PCN) for shape completion. Given a partial scan, our method first predicts its 3D skeleton to obtain the global structure, and completes the surface by learning displacements from skeletal points. We decouple the shape completion into structure estimation and surface reconstruction, which eases the learning difficulty and benefits our method to obtain on-surface details. Besides, considering the missing features during encoding input points, SK-PCN adopts a local adjustment strategy that merges the input point cloud to our predictions for surface refinement. Comparing with previous methods, our skeleton-bridged manner better supports point normal estimation to obtain the full surface mesh beyond point clouds. The qualitative and quantitative experiments on both point cloud and mesh completion show that our approach outperforms the existing methods on various object categories.