 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual input stream transformer for eye-tracking line assignment
Nov 10, 2023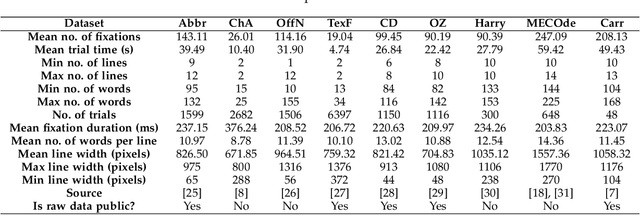
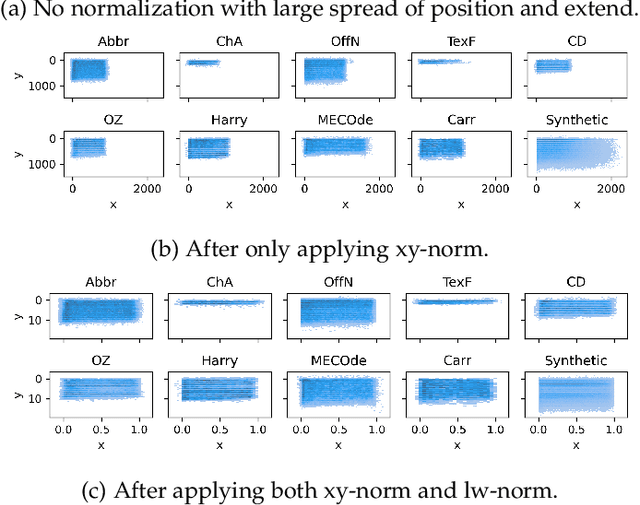

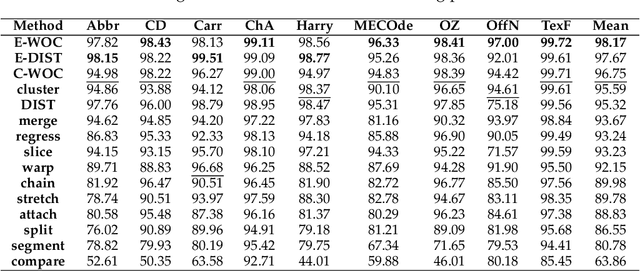
We introduce a novel Dual Input Stream Transformer (DIST) for the challenging problem of assigning fixation points from eye-tracking data collected during passage reading to the line of text that the reader was actually focused on. This post-processing step is crucial for analysis of the reading data due to the presence of noise in the form of vertical drift. We evaluate DIST against nine classical approaches on a comprehensive suite of nine diverse datasets, and demonstrate DIST's superiority. By combining multiple instances of the DIST model in an ensemble we achieve an average accuracy of 98.5\% across all datasets. Our approach presents a significant step towards addressing the bottleneck of manual line assignment in reading research. Through extensive model analysis and ablation studies, we identify key factors that contribute to DIST's success, including the incorporation of line overlap features and the use of a second input stream. Through evaluation on a set of diverse datasets we demonstrate that DIST is robust to various experimental setups, making it a safe first choice for practitioners in the field.
CLARA: Multilingual Contrastive Learning for Audio Representation Acquisition
Nov 01, 2023Multilingual speech processing requires understanding emotions, a task made difficult by limited labelled data. CLARA, minimizes reliance on labelled data, enhancing generalization across languages. It excels at fostering shared representations, aiding cross-lingual transfer of speech and emotions, even with little data. Our approach adeptly captures emotional nuances in speech, overcoming subjective assessment issues. Using a large multilingual audio corpus and self-supervised learning, CLARA develops speech representations enriched with emotions, advancing emotion-aware multilingual speech processing. Our method expands the data range using data augmentation, textual embedding for visual understanding, and transfers knowledge from high- to low-resource languages. CLARA demonstrates excellent performance in emotion recognition, language comprehension, and audio benchmarks, excelling in zero-shot and few-shot learning. It adapts to low-resource languages, marking progress in multilingual speech representation learning.
Sexing Caucasian 2D footprints using convolutional neural networks
Jul 23, 2021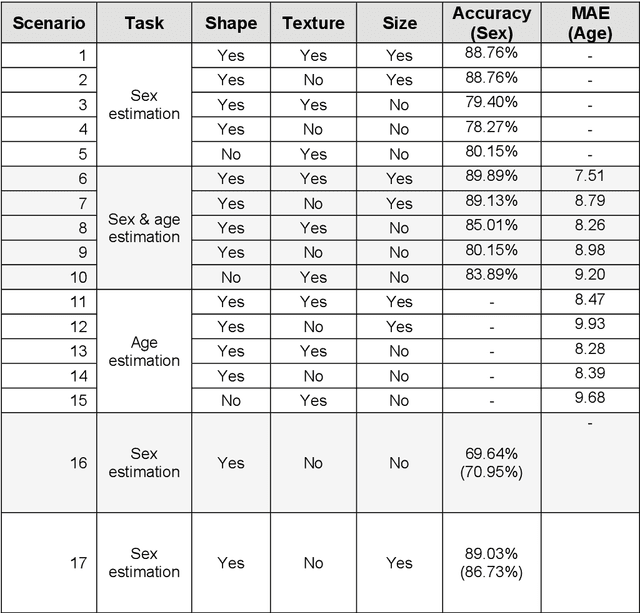
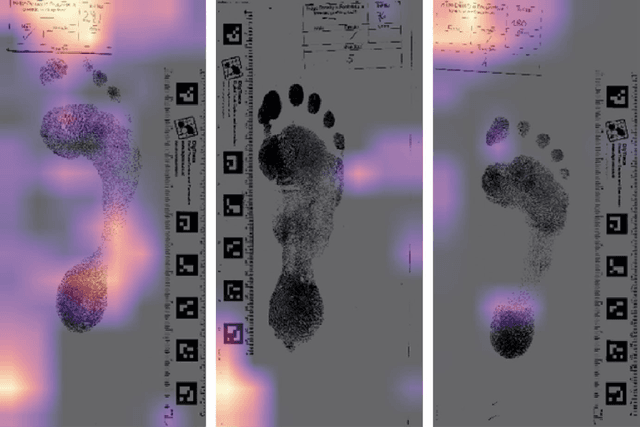
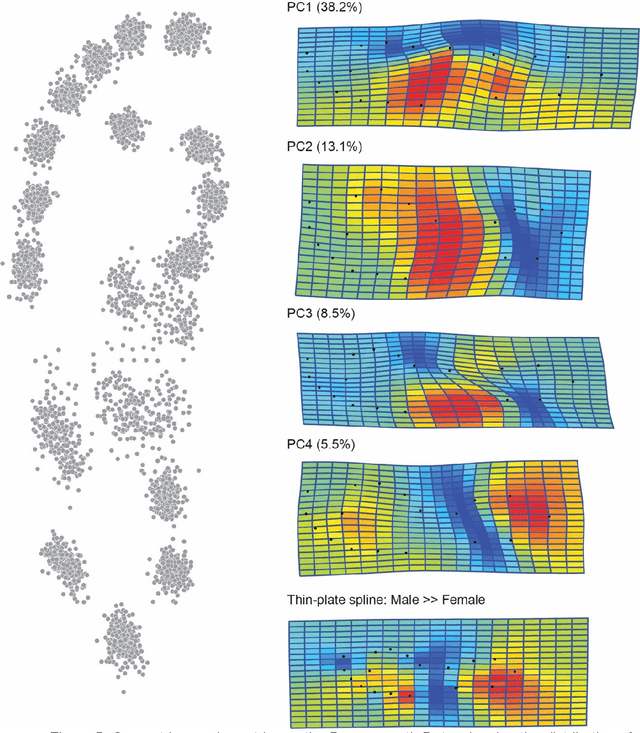
Footprints are left, or obtained, in a variety of scenarios from crime scenes to anthropological investigations. Determining the sex of a footprint can be useful in screening such impressions and attempts have been made to do so using single or multi landmark distances, shape analyses and via the density of friction ridges. Here we explore the relative importance of different components in sexing two-dimensional foot impressions namely, size, shape and texture. We use a machine learning approach and compare this to more traditional methods of discrimination. Two datasets are used, a pilot data set collected from students at Bournemouth University (N=196) and a larger data set collected by podiatrists at Sheffield NHS Teaching Hospital (N=2677). Our convolutional neural network can sex a footprint with accuracy of around 90% on a test set of N=267 footprint images using all image components, which is better than an expert can achieve. However, the quality of the impressions impacts on this success rate, but the results are promising and in time it may be possible to create an automated screening algorithm in which practitioners of whatever sort (medical or forensic) can obtain a first order sexing of a two-dimensional footprint.
An Automated Approach for Timely Diagnosis and Prognosis of Coronavirus Disease
Apr 29, 2021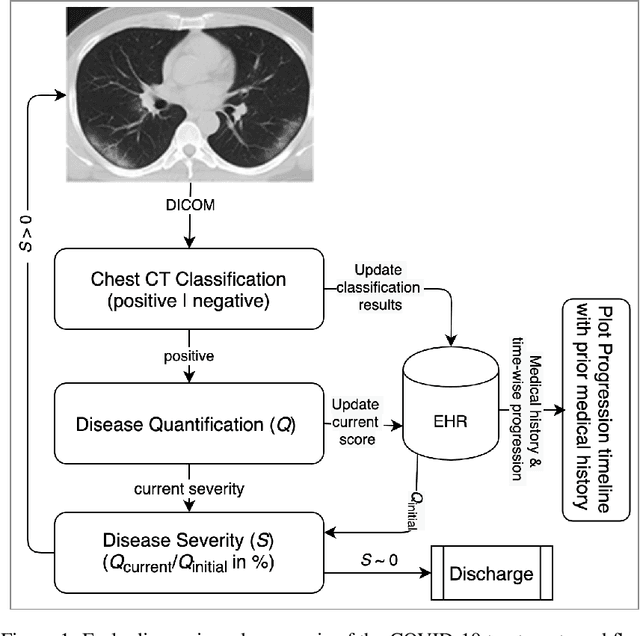


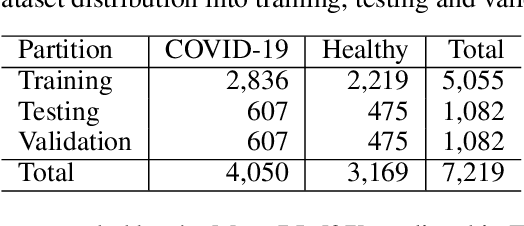
Since the outbreak of Coronavirus Disease 2019 (COVID-19), most of the impacted patients have been diagnosed with high fever, dry cough, and soar throat leading to severe pneumonia. Hence, to date, the diagnosis of COVID-19 from lung imaging is proved to be a major evidence for early diagnosis of the disease. Although nucleic acid detection using real-time reverse-transcriptase polymerase chain reaction (rRT-PCR) remains a gold standard for the detection of COVID-19, the proposed approach focuses on the automated diagnosis and prognosis of the disease from a non-contrast chest computed tomography (CT)scan for timely diagnosis and triage of the patient. The prognosis covers the quantification and assessment of the disease to help hospitals with the management and planning of crucial resources, such as medical staff, ventilators and intensive care units (ICUs) capacity. The approach utilises deep learning techniques for automated quantification of the severity of COVID-19 disease via measuring the area of multiple rounded ground-glass opacities (GGO) and consolidations in the periphery (CP) of the lungs and accumulating them to form a severity score. The severity of the disease can be correlated with the medicines prescribed during the triage to assess the effectiveness of the treatment. The proposed approach shows promising results where the classification model achieved 93% accuracy on hold-out data.
* to be published in IJCNN 2021
Deep Multilabel CNN for Forensic Footwear Impression Descriptor Identification
Feb 09, 2021


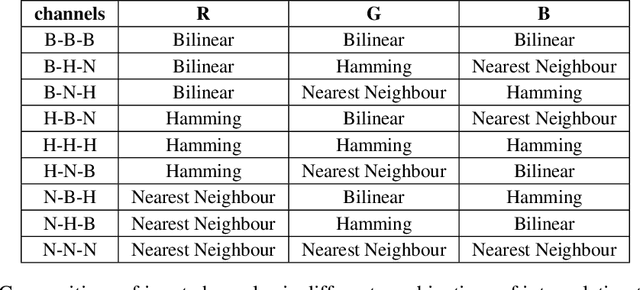
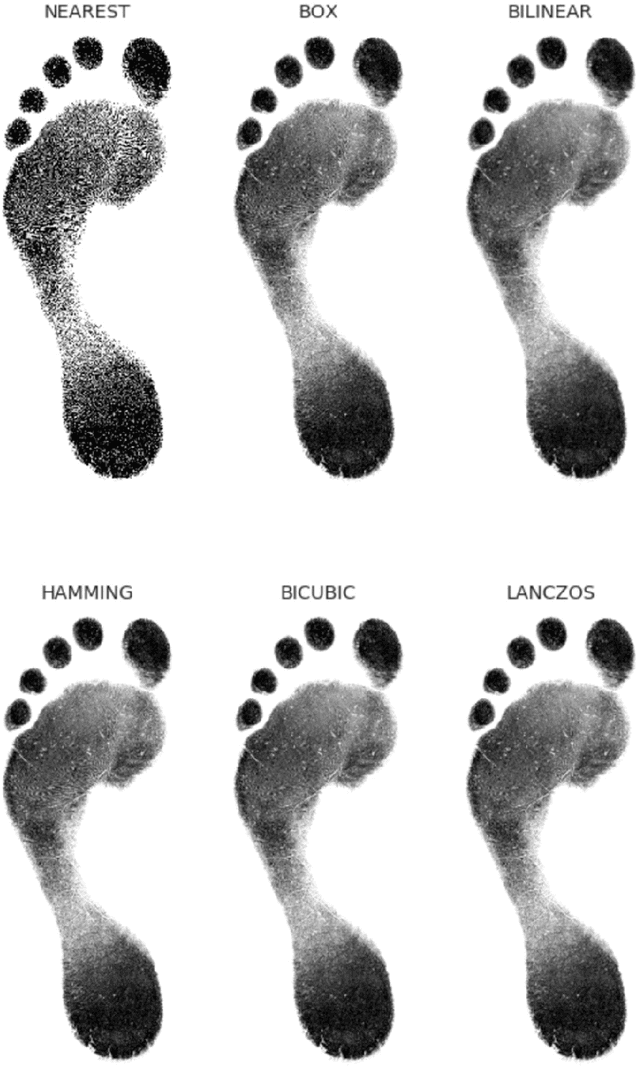
In recent years deep neural networks have become the workhorse of computer vision. In this paper, we employ a deep learning approach to classify footwear impression's features known as \emph{descriptors} for forensic use cases. Within this process, we develop and evaluate an effective technique for feeding downsampled greyscale impressions to a neural network pre-trained on data from a different domain. Our approach relies on learnable preprocessing layer paired with multiple interpolation methods used in parallel. We empirically show that this technique outperforms using a single type of interpolated image without learnable preprocessing, and can help to avoid the computational penalty related to using high resolution inputs, by making more efficient use of the low resolution inputs. We also investigate the effect of preserving the aspect ratio of the inputs, which leads to considerable boost in accuracy without increasing the computational budget with respect to squished rectangular images. Finally, we formulate a set of best practices for transfer learning with greyscale inputs, potentially widely applicable in computer vision tasks ranging from footwear impression classification to medical imaging.
A Review of Meta-level Learning in the Context of Multi-component, Multi-level Evolving Prediction Systems
Jul 17, 2020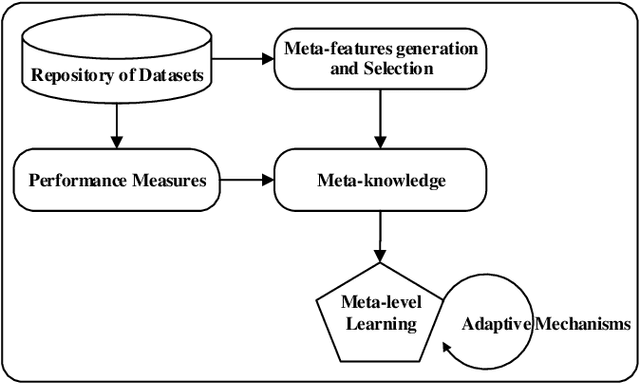
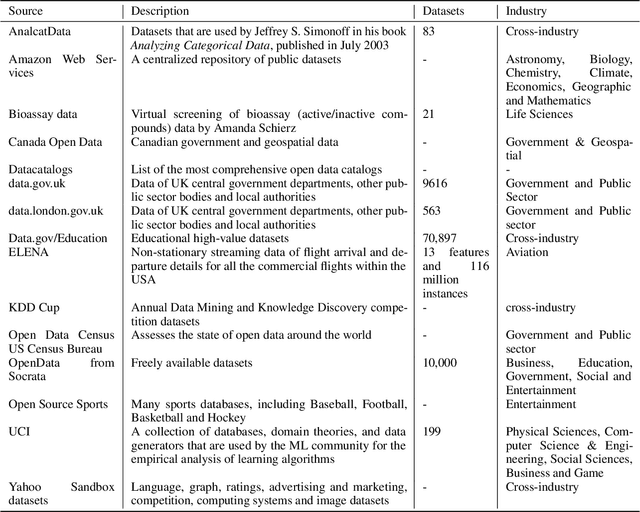
The exponential growth of volume, variety and velocity of data is raising the need for investigations of automated or semi-automated ways to extract useful patterns from the data. It requires deep expert knowledge and extensive computational resources to find the most appropriate mapping of learning methods for a given problem. It becomes a challenge in the presence of numerous configurations of learning algorithms on massive amounts of data. So there is a need for an intelligent recommendation engine that can advise what is the best learning algorithm for a dataset. The techniques that are commonly used by experts are based on a trial and error approach evaluating and comparing a number of possible solutions against each other, using their prior experience on a specific domain, etc. The trial and error approach combined with the expert's prior knowledge, though computationally and time expensive, have been often shown to work for stationary problems where the processing is usually performed off-line. However, this approach would not normally be feasible to apply to non-stationary problems where streams of data are continuously arriving. Furthermore, in a non-stationary environment, the manual analysis of data and testing of various methods whenever there is a change in the underlying data distribution would be very difficult or simply infeasible. In that scenario and within an on-line predictive system, there are several tasks where Meta-learning can be used to effectively facilitate best recommendations including 1) pre-processing steps, 2) learning algorithms or their combination, 3) adaptivity mechanisms and their parameters, 4) recurring concept extraction, and 5) concept drift detection.
Simulation and Augmentation of Social Networks for Building Deep Learning Models
May 27, 2019



A limitation of the Graph Convolutional Networks (GCNs) is that it assumes at a particular $l^{th}$ layer of the neural network model only the $l^{th}$ order neighbourhood nodes of a social network are influential. Furthermore, the GCN has been evaluated on citation and knowledge graphs, but not extensively on friendship-based social graphs. The drawback associated with the dependencies between layers and the order of node neighbourhood for the GCN can be more prevalent for friendship-based graphs. The evaluation of the full potential of the GCN on friendship-based social network requires openly available datasets in larger quantities. However, most available social network datasets are not complete. Also, the majority of the available social network datasets do not contain both the features and ground truth labels. In this work, firstly, we provide a guideline on simulating dynamic social networks, with ground truth labels and features, both coupled with the topology. Secondly, we introduce an open-source Python-based simulation library. We argue that the topology of the network is driven by a set of latent variables, termed as the social DNA (sDNA). We consider the sDNA as labels for the nodes. Finally, by evaluating on our simulated datasets, we propose four new variants of the GCN, mainly to overcome the limitation of dependency between the order of node-neighbourhood and a particular layer of the model. We then evaluate the performance of all the models and our results show that on 27 out of the 30 simulated datasets our proposed GCN variants outperform the original model.
Automatic composition and optimisation of multicomponent predictive systems
Dec 28, 2016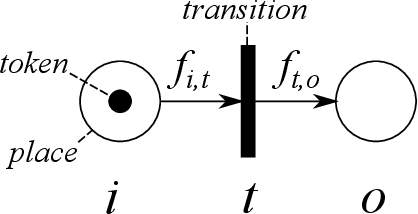
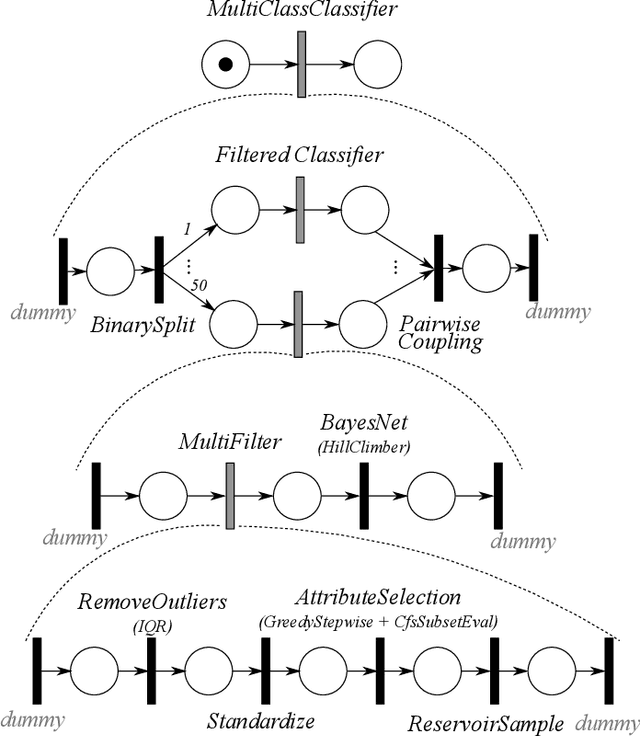
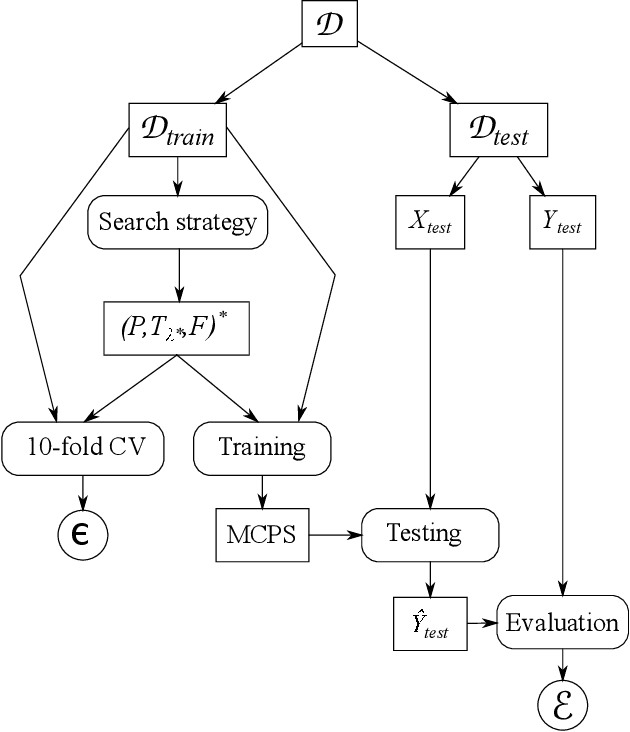
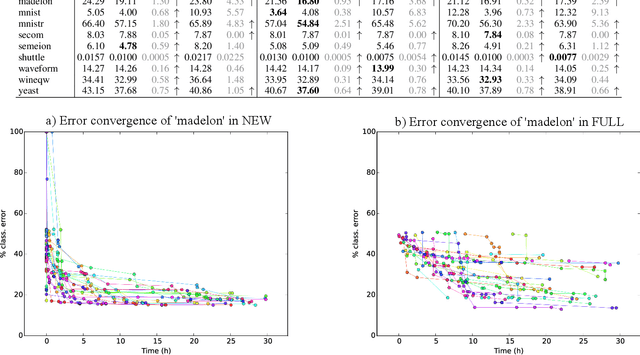
Composition and parametrisation of multicomponent predictive systems (MCPSs) consisting of chains of data transformation steps is a challenging task. This paper is concerned with theoretical considerations and extensive experimental analysis for automating the task of building such predictive systems. In the theoretical part of the paper, we first propose to adopt the Well-handled and Acyclic Workflow (WA-WF) Petri net as a formal representation of MCPSs. We then define the optimisation problem in which the search space consists of suitably parametrised directed acyclic graphs (i.e. WA-WFs) forming the sought MCPS solutions. In the experimental analysis we focus on examining the impact of considerably extending the search space resulting from incorporating multiple sequential data cleaning and preprocessing steps in the process of composing optimised MCPSs, and the quality of the solutions found. In a range of extensive experiments three different optimisation strategies are used to automatically compose MCPSs for 21 publicly available datasets and 7 datasets from real chemical processes. The diversity of the composed MCPSs found is an indication that fully and automatically exploiting different combinations of data cleaning and preprocessing techniques is possible and highly beneficial for different predictive models. Our findings can have a major impact on development of high quality predictive models as well as their maintenance and scalability aspects needed in modern applications and deployment scenarios.