 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Meta-level Learning in the Context of Multi-component, Multi-level Evolving Prediction Systems
Paper and Code
Jul 17, 2020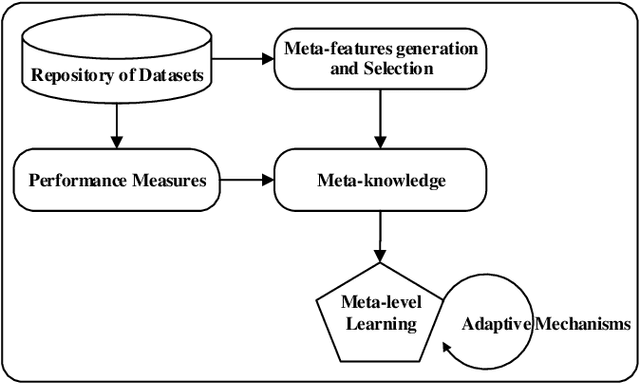
The exponential growth of volume, variety and velocity of data is raising the need for investigations of automated or semi-automated ways to extract useful patterns from the data. It requires deep expert knowledge and extensive computational resources to find the most appropriate mapping of learning methods for a given problem. It becomes a challenge in the presence of numerous configurations of learning algorithms on massive amounts of data. So there is a need for an intelligent recommendation engine that can advise what is the best learning algorithm for a dataset. The techniques that are commonly used by experts are based on a trial and error approach evaluating and comparing a number of possible solutions against each other, using their prior experience on a specific domain, etc. The trial and error approach combined with the expert's prior knowledge, though computationally and time expensive, have been often shown to work for stationary problems where the processing is usually performed off-line. However, this approach would not normally be feasible to apply to non-stationary problems where streams of data are continuously arriving. Furthermore, in a non-stationary environment, the manual analysis of data and testing of various methods whenever there is a change in the underlying data distribution would be very difficult or simply infeasible. In that scenario and within an on-line predictive system, there are several tasks where Meta-learning can be used to effectively facilitate best recommendations including 1) pre-processing steps, 2) learning algorithms or their combination, 3) adaptivity mechanisms and their parameters, 4) recurring concept extraction, and 5) concept drift detection.