 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Phase Segmentation Approach for Accurate Left Ventricle Segmentation in Cardiac MRI using Machine Learning
Jul 29, 2024
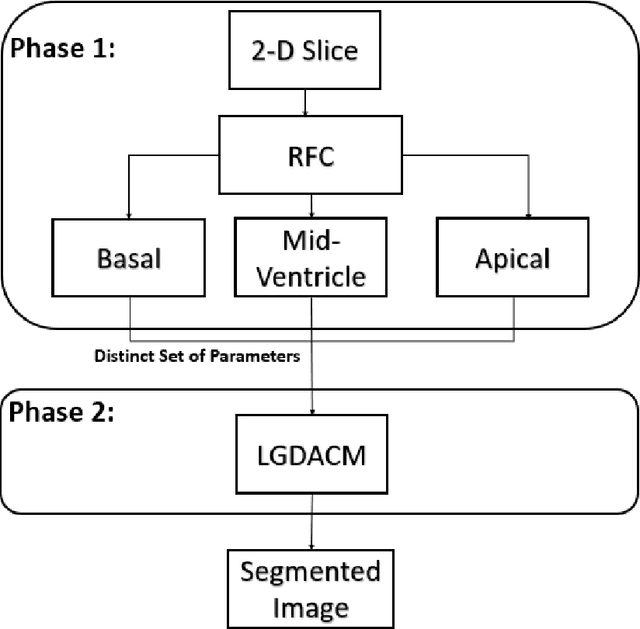


Accurate segmentation of the Left Ventricle (LV) holds substantial importance due to its implications in disease detection, regional analysis, and the development of complex models for cardiac surgical planning. CMR is a golden standard for diagnosis of serveral cardiac diseases. LV in CMR comprises of three distinct sections: Basal, Mid-Ventricle, and Apical. This research focuses on the precise segmentation of the LV from Cardiac MRI (CMR) scans, joining with the capabilities of Machine Learning (ML). The central challenge in this research revolves around the absence of a set of parameters applicable to all three types of LV slices. Parameters optimized for basal slices often fall short when applied to mid-ventricular and apical slices, and vice versa. To handle this issue, a new method is proposed to enhance LV segmentation. The proposed method involves using distinct sets of parameters for each type of slice, resulting in a two-phase segmentation approach. The initial phase categorizes images into three groups based on the type of LV slice, while the second phase aims to segment CMR images using parameters derived from the preceding phase. A publicly available dataset (Automated Cardiac Diagnosis Challenge (ACDC)) is used. 10-Fold Cross Validation is used and it achieved a mean score of 0.9228. Comprehensive testing indicates that the best parameter set for a particular type of slice does not perform adequately for the other slice types. All results show that the proposed approach fills a critical void in parameter standardization through a two-phase segmentation model for the LV, aiming to not only improve the accuracy of cardiac image analysis but also contribute advancements to the field of LV segmentation.
A Large and Diverse Arabic Corpus for Language Modeling
Jan 23, 2022Language models (LMs) have introduced a major paradigm shift in Natural Language Processing (NLP) modeling where large pre-trained LMs became integral to most of the NLP tasks. The LMs are intelligent enough to find useful and relevant representations of the language without any supervision. Perhaps, these models are used to fine-tune typical NLP tasks with significantly high accuracy as compared to the traditional approaches. Conversely, the training of these models requires a massively large corpus that is a good representation of the language. English LMs generally perform better than their other language counterparts, due to the availability of massive English corpora. This work elaborates on the design and development of a large Arabic corpus. It consists of over 500 GB of Arabic cleaned text targeted at improving cross-domain knowledge and downstream generalization capability of large-scale language models. Moreover, the corpus is utilized in the training of a large Arabic LM. In order to evaluate the effectiveness of the LM, a number of typical NLP tasks are fine-tuned. The tasks demonstrate a significant boost from 4.5 to 8.5% when compared to tasks fine-tuned on multi-lingual BERT (mBERT). To the best of my knowledge, this is currently the largest clean and diverse Arabic corpus ever collected.
Demand-Driven Asset Reutilization Analytics
Dec 28, 2021Manufacturers have long benefited from reusing returned products and parts. This benevolent approach can minimize cost and help the manufacturer to play a role in sustaining the environment, something which is of utmost importance these days because of growing environment concerns. Reuse of returned parts and products aids environment sustainability because doing so helps reduce the use of raw materials, eliminate energy use to produce new parts, and minimize waste materials. However, handling returns effectively and efficiently can be difficult if the processes do not provide the visibility that is necessary to track, manage, and re-use the returns. This paper applies advanced analytics on procurement data to increase reutilization in new build by optimizing Equal-to-New (ETN) parts return. This will reduce 'the spend' on new buy parts for building new product units. The process involves forecasting and matching returns supply to demand for new build. Complexity in the process is the forecasting and matching while making sure a reutilization engineering process is available. Also, this will identify high demand/value/yield parts for development engineering to focus. Analytics has been applied on different levels to enhance the optimization process including forecast of upgraded parts. Machine Learning algorithms are used to build an automated infrastructure that can support the transformation of ETN parts utilization in the procurement parts planning process. This system incorporate returns forecast in the planning cycle to reduce suppliers liability from 9 weeks to 12 months planning cycle, e.g., reduce 5% of 10 million US dollars liability.
Cognitive Computing to Optimize IT Services
Dec 28, 2021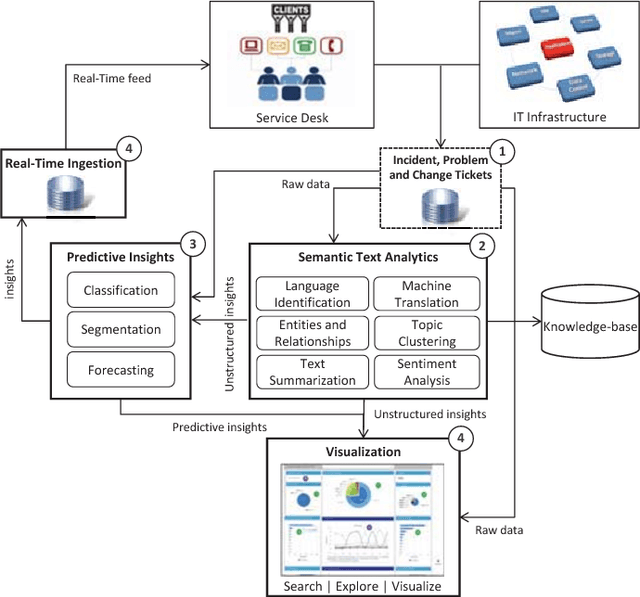
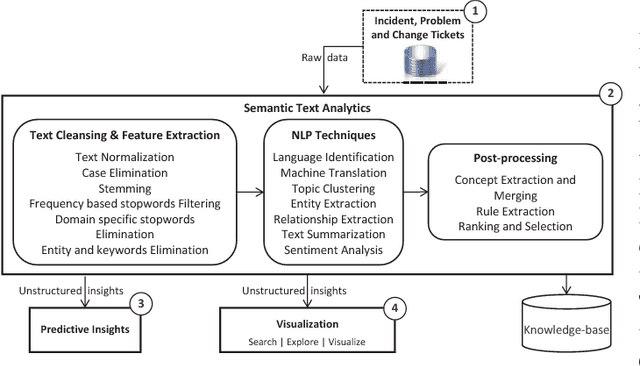
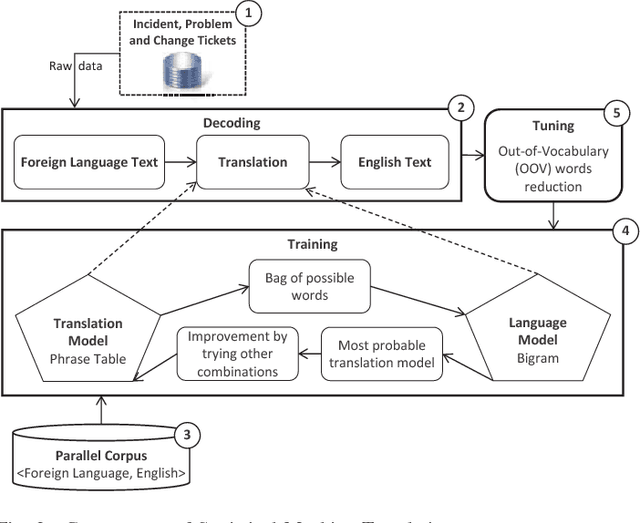
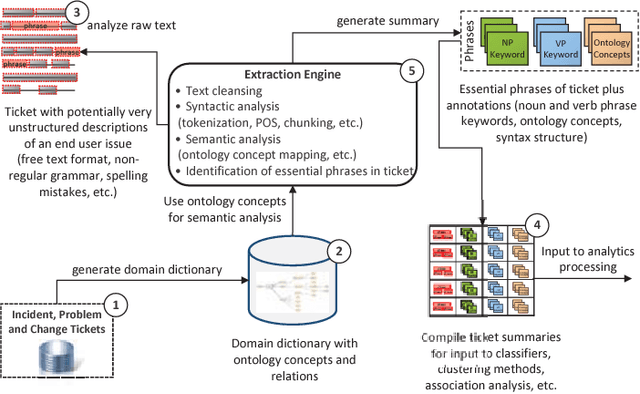
In this paper, the challenges of maintaining a healthy IT operational environment have been addressed by proactively analyzing IT Service Desk tickets, customer satisfaction surveys, and social media data. A Cognitive solution goes beyond the traditional structured data analysis by deep analyses of both structured and unstructured text. The salient features of the proposed platform include language identification, translation, hierarchical extraction of the most frequently occurring topics, entities and their relationships, text summarization, sentiments, and knowledge extraction from the unstructured text using Natural Language Processing techniques. Moreover, the insights from unstructured text combined with structured data allow the development of various classification, segmentation, and time-series forecasting use-cases on the incident, problem, and change datasets. Further, the text and predictive insights together with raw data are used for visualization and exploration of actionable insights on a rich and interactive dashboard. However, it is hard not only to find these insights using traditional structured data analysis but it might also take a very long time to discover them, especially while dealing with a massive amount of unstructured data. By taking action on these insights, organizations can benefit from a significant reduction of ticket volume, reduced operational costs, and increased customer satisfaction. In various experiments, on average, upto 18-25% of yearly ticket volume has been reduced using the proposed approach.
Multi-Dialect Arabic Speech Recognition
Dec 25, 2021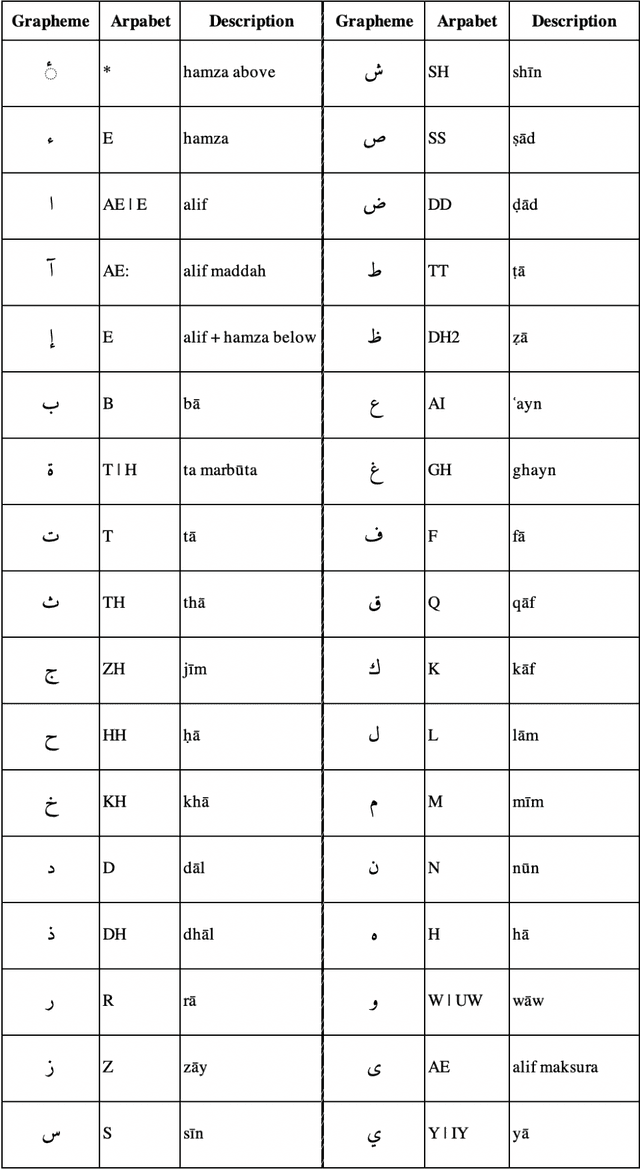
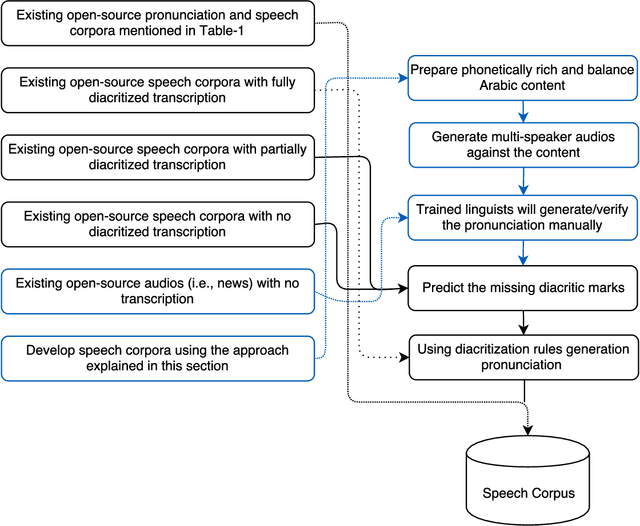
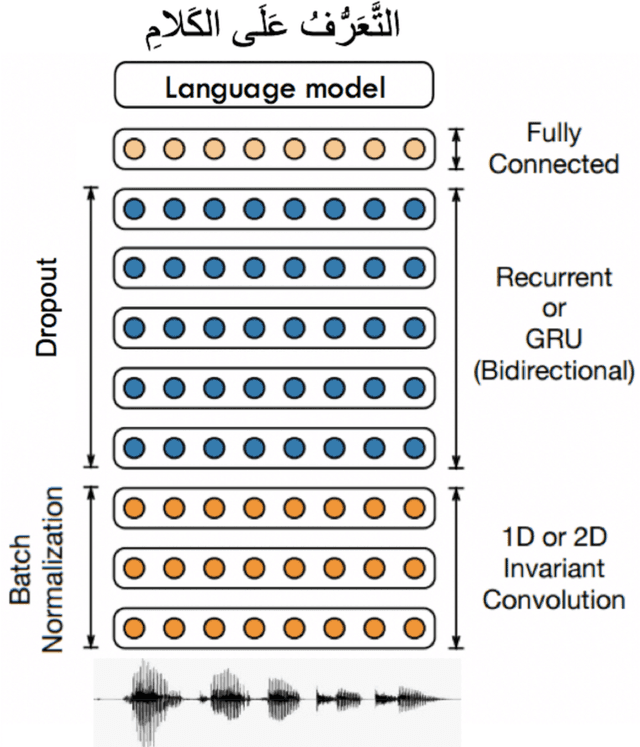

This paper presents the design and development of multi-dialect automatic speech recognition for Arabic. Deep neural networks are becoming an effective tool to solve sequential data problems, particularly, adopting an end-to-end training of the system. Arabic speech recognition is a complex task because of the existence of multiple dialects, non-availability of large corpora, and missing vocalization. Thus, the first contribution of this work is the development of a large multi-dialectal corpus with either full or at least partially vocalized transcription. Additionally, the open-source corpus has been gathered from multiple sources that bring non-standard Arabic alphabets in transcription which are normalized by defining a common character-set. The second contribution is the development of a framework to train an acoustic model achieving state-of-the-art performance. The network architecture comprises of a combination of convolutional and recurrent layers. The spectrogram features of the audio data are extracted in the frequency vs time domain and fed in the network. The output frames, produced by the recurrent model, are further trained to align the audio features with its corresponding transcription sequences. The sequence alignment is performed using a beam search decoder with a tetra-gram language model. The proposed system achieved a 14% error rate which outperforms previous systems.
An Automated Approach for Timely Diagnosis and Prognosis of Coronavirus Disease
Apr 29, 2021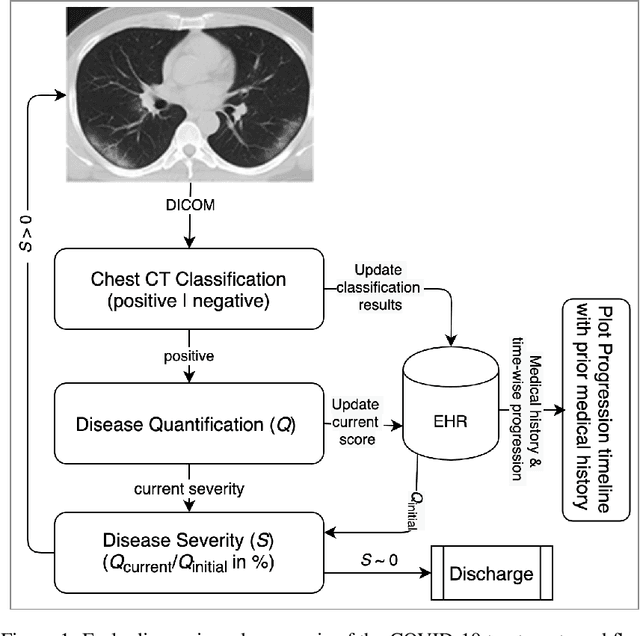


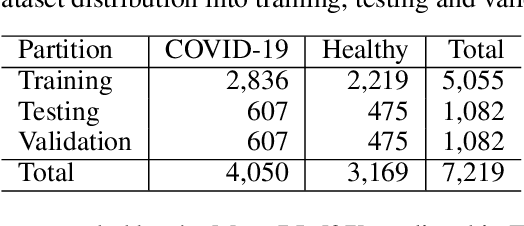
Since the outbreak of Coronavirus Disease 2019 (COVID-19), most of the impacted patients have been diagnosed with high fever, dry cough, and soar throat leading to severe pneumonia. Hence, to date, the diagnosis of COVID-19 from lung imaging is proved to be a major evidence for early diagnosis of the disease. Although nucleic acid detection using real-time reverse-transcriptase polymerase chain reaction (rRT-PCR) remains a gold standard for the detection of COVID-19, the proposed approach focuses on the automated diagnosis and prognosis of the disease from a non-contrast chest computed tomography (CT)scan for timely diagnosis and triage of the patient. The prognosis covers the quantification and assessment of the disease to help hospitals with the management and planning of crucial resources, such as medical staff, ventilators and intensive care units (ICUs) capacity. The approach utilises deep learning techniques for automated quantification of the severity of COVID-19 disease via measuring the area of multiple rounded ground-glass opacities (GGO) and consolidations in the periphery (CP) of the lungs and accumulating them to form a severity score. The severity of the disease can be correlated with the medicines prescribed during the triage to assess the effectiveness of the treatment. The proposed approach shows promising results where the classification model achieved 93% accuracy on hold-out data.
* to be published in IJCNN 2021
A Review of Meta-level Learning in the Context of Multi-component, Multi-level Evolving Prediction Systems
Jul 17, 2020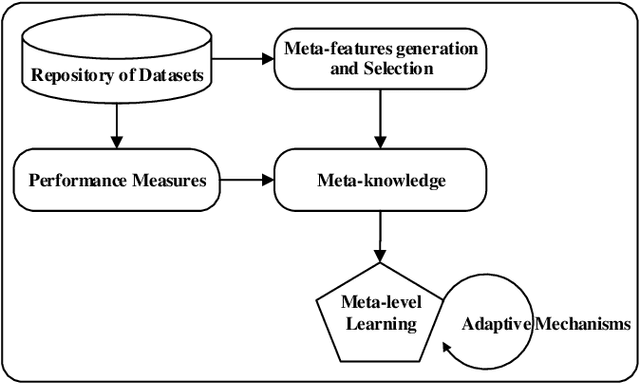
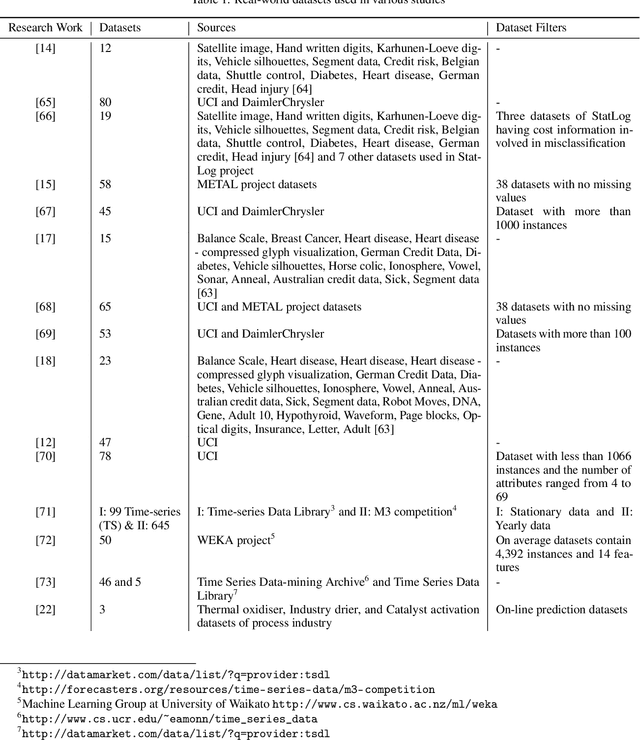
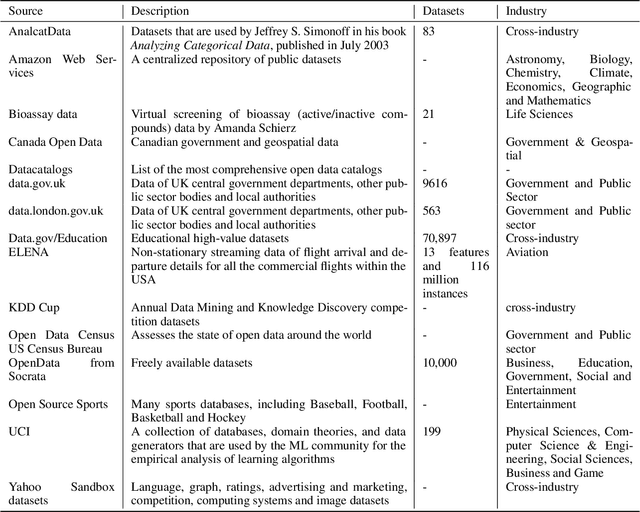
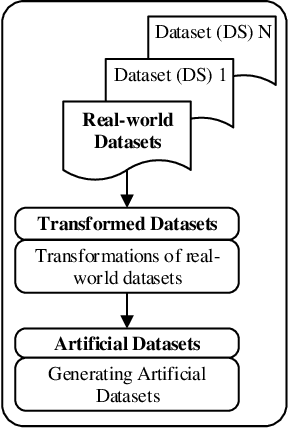
The exponential growth of volume, variety and velocity of data is raising the need for investigations of automated or semi-automated ways to extract useful patterns from the data. It requires deep expert knowledge and extensive computational resources to find the most appropriate mapping of learning methods for a given problem. It becomes a challenge in the presence of numerous configurations of learning algorithms on massive amounts of data. So there is a need for an intelligent recommendation engine that can advise what is the best learning algorithm for a dataset. The techniques that are commonly used by experts are based on a trial and error approach evaluating and comparing a number of possible solutions against each other, using their prior experience on a specific domain, etc. The trial and error approach combined with the expert's prior knowledge, though computationally and time expensive, have been often shown to work for stationary problems where the processing is usually performed off-line. However, this approach would not normally be feasible to apply to non-stationary problems where streams of data are continuously arriving. Furthermore, in a non-stationary environment, the manual analysis of data and testing of various methods whenever there is a change in the underlying data distribution would be very difficult or simply infeasible. In that scenario and within an on-line predictive system, there are several tasks where Meta-learning can be used to effectively facilitate best recommendations including 1) pre-processing steps, 2) learning algorithms or their combination, 3) adaptivity mechanisms and their parameters, 4) recurring concept extraction, and 5) concept drift detection.