 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultipath Adaptive Gated Bottleneck Latent ODE with Raman Data Fusion for Cell Culture Process Forecasting
Jun 25, 2026Mammalian cell-culture processes underpin the manufacture of many biopharmaceuticals, yet keeping a run on track is hard: critical process parameters drift over days, and an off-specification trend is often confirmed too late to intervene. Early-stage, multi-day forecasts could enable timely adjustment of feeding, sampling, and control, but bioprocess forecasting is challenging because measurements are sparse and irregularly sampled, operating conditions are heterogeneous across cell lines and media, and runs with near-identical early behaviour can diverge into different futures. We propose an adaptive framework combining a Gated Bottleneck Latent Ordinary Differential Equation (GB-Latent ODE) with Multi-Path Just-In-Time Fine Tuning (MP-JIT-FT). The GB-Latent ODE augments the stan dard Latent ODE with learnable variable-wise gating and a mask-aware bottleneck that compress high-dimensional sparse inputs, improving learning under limited data. Given a partially observed run, MP-JIT-FT retrieves similar historical trajectories, clusters the local neighbourhood into candidate regimes, and fine-tunes a separate model per regime to produce multiple plausible paths, each with a reconstruction-based confidence score, not a single averaged forecast. We further fuse Raman spectroscopy data: a machine-learning soft sensor turns dense Raman spectra into pseudo-observations that enrich the sparse offline measurements for more robust training. On 38 fed-batch 5L bioreactor runs spanning 14 conditions, MP-JIT-FT with Raman fusion achieves the best average rank and outperforms a global Latent ODE baseline on 8 of 9 target variables. Using local-divergence metrics, we show the multi-path gains are largest when locally similar prefixes diverge, whereas Raman fusion helps most when early dynamics are representative of later behaviour.
Twinning Complex Networked Systems: Data-Driven Calibration of the mABCD Synthetic Graph Generator
Feb 02, 2026The increasing availability of relational data has contributed to a growing reliance on network-based representations of complex systems. Over time, these models have evolved to capture more nuanced properties, such as the heterogeneity of relationships, leading to the concept of multilayer networks. However, the analysis and evaluation of methods for these structures is often hindered by the limited availability of large-scale empirical data. As a result, graph generators are commonly used as a workaround, albeit at the cost of introducing systematic biases. In this paper, we address the inverse-generator problem by inferring the configuration parameters of a multilayer network generator, mABCD, from a real-world system. Our goal is to identify parameter settings that enable the generator to produce synthetic networks that act as digital twins of the original structure. We propose a method for estimating matching configurations and for quantifying the associated error. Our results demonstrate that this task is non-trivial, as strong interdependencies between configuration parameters weaken independent estimation and instead favour a joint-prediction approach.
Machine Learning Methods for Small Data and Upstream Bioprocessing Applications: A Comprehensive Review
Jun 14, 2025Data is crucial for machine learning (ML) applications, yet acquiring large datasets can be costly and time-consuming, especially in complex, resource-intensive fields like biopharmaceuticals. A key process in this industry is upstream bioprocessing, where living cells are cultivated and optimised to produce therapeutic proteins and biologics. The intricate nature of these processes, combined with high resource demands, often limits data collection, resulting in smaller datasets. This comprehensive review explores ML methods designed to address the challenges posed by small data and classifies them into a taxonomy to guide practical applications. Furthermore, each method in the taxonomy was thoroughly analysed, with a detailed discussion of its core concepts and an evaluation of its effectiveness in tackling small data challenges, as demonstrated by application results in the upstream bioprocessing and other related domains. By analysing how these methods tackle small data challenges from different perspectives, this review provides actionable insights, identifies current research gaps, and offers guidance for leveraging ML in data-constrained environments.
How the use of feature selection methods influences the efficiency and accuracy of complex network simulations
Dec 02, 2024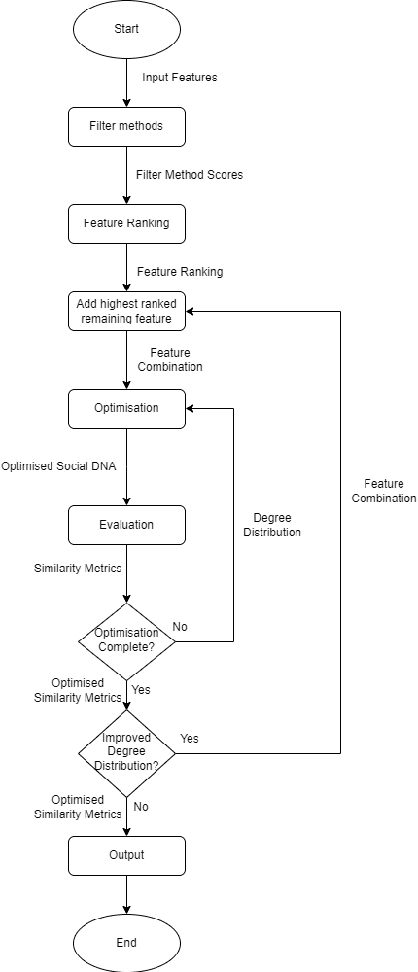
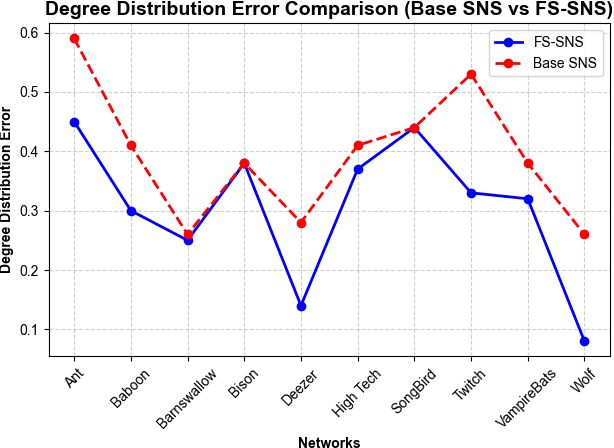
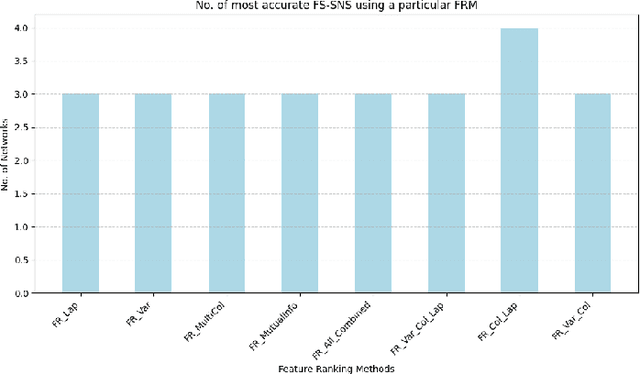
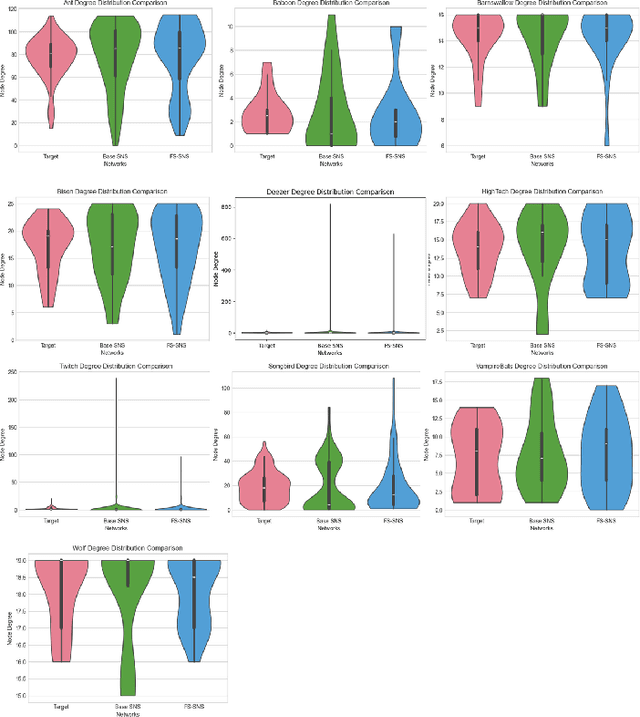
Complex network systems' models are designed to perfectly emulate real-world networks through the use of simulation and link prediction. Complex network systems are defined by nodes and their connections where both have real-world features that result in a heterogeneous network in which each of the nodes has distinct characteristics. Thus, incorporating real-world features is an important component to achieve a simulation which best represents the real-world. Currently very few complex network systems implement real-world features, thus this study proposes feature selection methods which utilise unsupervised filtering techniques to rank real-world node features alongside a wrapper function to test combinations of the ranked features. The chosen method was coined FS-SNS which improved 8 out of 10 simulations of real-world networks. A consistent threshold of included features was also discovered which saw a threshold of 4 features to achieve the most accurate simulation for all networks. Through these findings the study also proposes future work and discusses how the findings can be used to further the Digital Twin and complex network system field.
Deep Reinforcement Learning for Digital Twin-Oriented Complex Networked Systems
Nov 09, 2024The Digital Twin Oriented Complex Networked System (DT-CNS) aims to build and extend a Complex Networked System (CNS) model with progressively increasing dynamics complexity towards an accurate reflection of reality -- a Digital Twin of reality. Our previous work proposed evolutionary DT-CNSs to model the long-term adaptive network changes in an epidemic outbreak. This study extends this framework by proposeing the temporal DT-CNS model, where reinforcement learning-driven nodes make decisions on temporal directed interactions in an epidemic outbreak. We consider cooperative nodes, as well as egocentric and ignorant "free-riders" in the cooperation. We describe this epidemic spreading process with the Susceptible-Infected-Recovered ($SIR$) model and investigate the impact of epidemic severity on the epidemic resilience for different types of nodes. Our experimental results show that (i) the full cooperation leads to a higher reward and lower infection number than a cooperation with egocentric or ignorant "free-riders"; (ii) an increasing number of "free-riders" in a cooperation leads to a smaller reward, while an increasing number of egocentric "free-riders" further escalate the infection numbers and (iii) higher infection rates and a slower recovery weakens networks' resilience to severe epidemic outbreaks. These findings also indicate that promoting cooperation and reducing "free-riders" can improve public health during epidemics.
Heterogeneous Feature Representation for Digital Twin-Oriented Complex Networked Systems
Sep 23, 2023
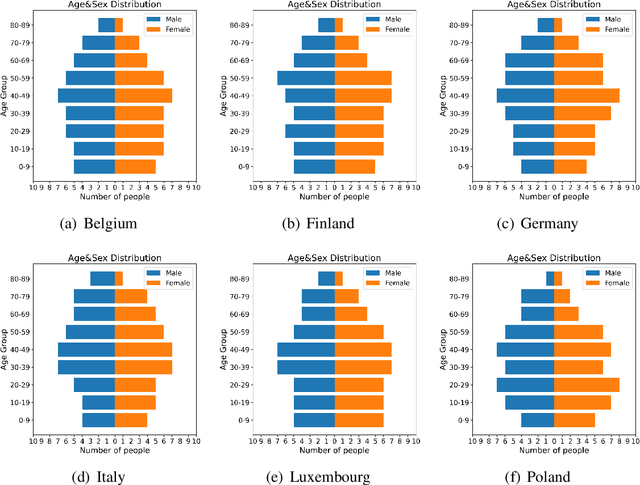
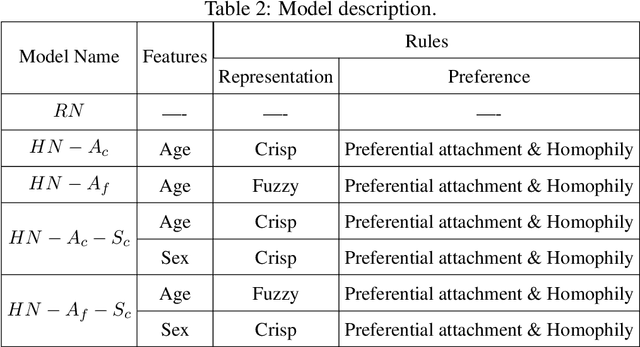
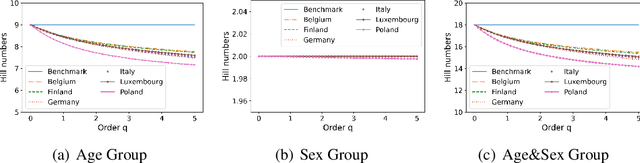
Building models of Complex Networked Systems (CNS) that can accurately represent reality forms an important research area. To be able to reflect real world systems, the modelling needs to consider not only the intensity of interactions between the entities but also features of all the elements of the system. This study aims to improve the expressive power of node features in Digital Twin-Oriented Complex Networked Systems (DT-CNSs) with heterogeneous feature representation principles. This involves representing features with crisp feature values and fuzzy sets, each describing the objective and the subjective inductions of the nodes' features and feature differences. Our empirical analysis builds DT-CNSs to recreate realistic physical contact networks in different countries from real node feature distributions based on various representation principles and an optimised feature preference. We also investigate their respective disaster resilience to an epidemic outbreak starting from the most popular node. The results suggest that the increasing flexibility of feature representation with fuzzy sets improves the expressive power and enables more accurate modelling. In addition, the heterogeneous features influence the network structure and the speed of the epidemic outbreak, requiring various mitigation policies targeted at different people.
Inferring Actual Treatment Pathways from Patient Records
Sep 05, 2023



Treatment pathways are step-by-step plans outlining the recommended medical care for specific diseases; they get revised when different treatments are found to improve patient outcomes. Examining health records is an important part of this revision process, but inferring patients' actual treatments from health data is challenging due to complex event-coding schemes and the absence of pathway-related annotations. This study aims to infer the actual treatment steps for a particular patient group from administrative health records (AHR) - a common form of tabular healthcare data - and address several technique- and methodology-based gaps in treatment pathway-inference research. We introduce Defrag, a method for examining AHRs to infer the real-world treatment steps for a particular patient group. Defrag learns the semantic and temporal meaning of healthcare event sequences, allowing it to reliably infer treatment steps from complex healthcare data. To our knowledge, Defrag is the first pathway-inference method to utilise a neural network (NN), an approach made possible by a novel, self-supervised learning objective. We also developed a testing and validation framework for pathway inference, which we use to characterise and evaluate Defrag's pathway inference ability and compare against baselines. We demonstrate Defrag's effectiveness by identifying best-practice pathway fragments for breast cancer, lung cancer, and melanoma in public healthcare records. Additionally, we use synthetic data experiments to demonstrate the characteristics of the Defrag method, and to compare Defrag to several baselines where it significantly outperforms non-NN-based methods. Defrag significantly outperforms several existing pathway-inference methods and offers an innovative and effective approach for inferring treatment pathways from AHRs. Open-source code is provided to encourage further research in this area.
Machine Learning for Administrative Health Records: A Systematic Review of Techniques and Applications
Aug 27, 2023



Machine learning provides many powerful and effective techniques for analysing heterogeneous electronic health records (EHR). Administrative Health Records (AHR) are a subset of EHR collected for administrative purposes, and the use of machine learning on AHRs is a growing subfield of EHR analytics. Existing reviews of EHR analytics emphasise that the data-modality of the EHR limits the breadth of suitable machine learning techniques, and pursuable healthcare applications. Despite emphasising the importance of data modality, the literature fails to analyse which techniques and applications are relevant to AHRs. AHRs contain uniquely well-structured, categorically encoded records which are distinct from other data-modalities captured by EHRs, and they can provide valuable information pertaining to how patients interact with the healthcare system. This paper systematically reviews AHR-based research, analysing 70 relevant studies and spanning multiple databases. We identify and analyse which machine learning techniques are applied to AHRs and which health informatics applications are pursued in AHR-based research. We also analyse how these techniques are applied in pursuit of each application, and identify the limitations of these approaches. We find that while AHR-based studies are disconnected from each other, the use of AHRs in health informatics research is substantial and accelerating. Our synthesis of these studies highlights the utility of AHRs for pursuing increasingly complex and diverse research objectives despite a number of pervading data- and technique-based limitations. Finally, through our findings, we propose a set of future research directions that can enhance the utility of AHR data and machine learning techniques for health informatics research.
Digital Twin-Oriented Complex Networked Systems based on Heterogeneous node features and interaction rules
Aug 18, 2023This study proposes an extendable modelling framework for Digital Twin-Oriented Complex Networked Systems (DT-CNSs) with a goal of generating networks that faithfully represent real systems. Modelling process focuses on (i) features of nodes and (ii) interaction rules for creating connections that are built based on individual node's preferences. We conduct experiments on simulation-based DT-CNSs that incorporate various features and rules about network growth and different transmissibilities related to an epidemic spread on these networks. We present a case study on disaster resilience of social networks given an epidemic outbreak by investigating the infection occurrence within specific time and social distance. The experimental results show how different levels of the structural and dynamics complexities, concerned with feature diversity and flexibility of interaction rules respectively, influence network growth and epidemic spread. The analysis revealed that, to achieve maximum disaster resilience, mitigation policies should be targeted at nodes with preferred features as they have higher infection risks and should be the focus of the epidemic control.
A Network Science perspective of Graph Convolutional Networks: A survey
Jan 12, 2023The mining and exploitation of graph structural information have been the focal points in the study of complex networks. Traditional structural measures in Network Science focus on the analysis and modelling of complex networks from the perspective of network structure, such as the centrality measures, the clustering coefficient, and motifs and graphlets, and they have become basic tools for studying and understanding graphs. In comparison, graph neural networks, especially graph convolutional networks (GCNs), are particularly effective at integrating node features into graph structures via neighbourhood aggregation and message passing, and have been shown to significantly improve the performances in a variety of learning tasks. These two classes of methods are, however, typically treated separately with limited references to each other. In this work, aiming to establish relationships between them, we provide a network science perspective of GCNs. Our novel taxonomy classifies GCNs from three structural information angles, i.e., the layer-wise message aggregation scope, the message content, and the overall learning scope. Moreover, as a prerequisite for reviewing GCNs via a network science perspective, we also summarise traditional structural measures and propose a new taxonomy for them. Finally and most importantly, we draw connections between traditional structural approaches and graph convolutional networks, and discuss potential directions for future research.