 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Taking Advantage of Opportunistic Meta-knowledge to Reduce Configuration Spaces for Automated Machine Learning
Aug 08, 2022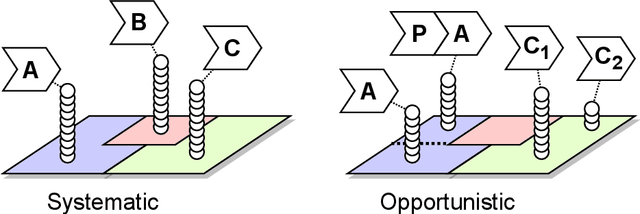
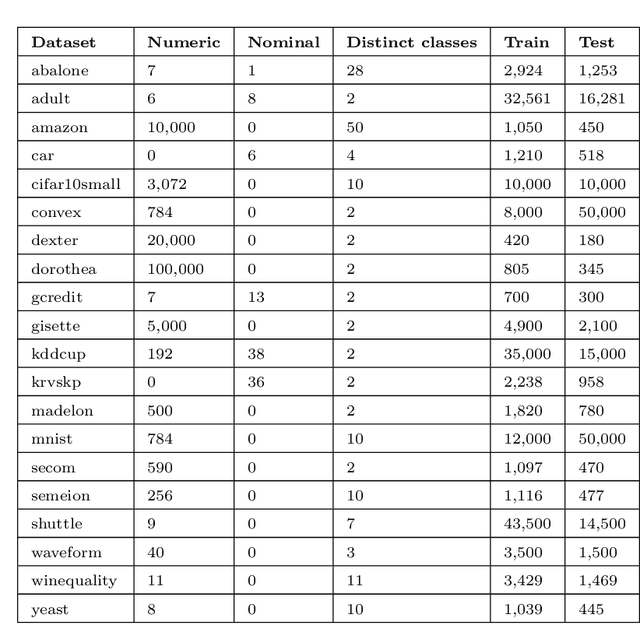
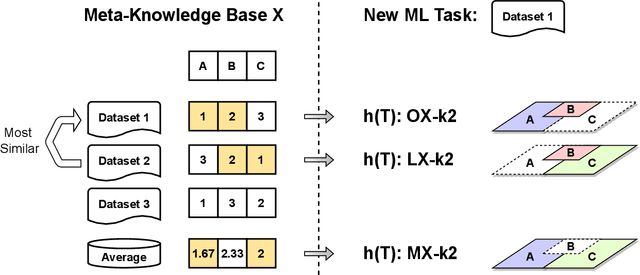
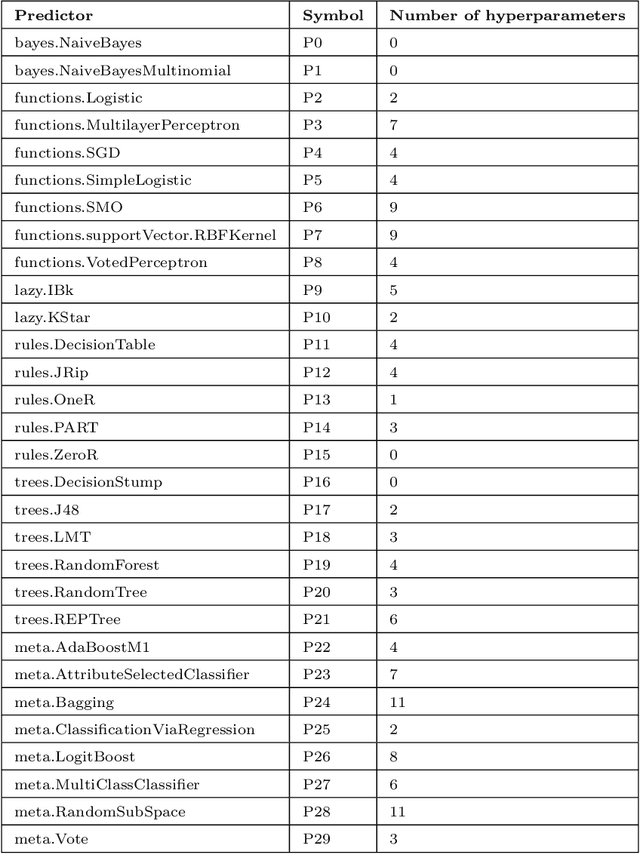
The automated machine learning (AutoML) process can require searching through complex configuration spaces of not only machine learning (ML) components and their hyperparameters but also ways of composing them together, i.e. forming ML pipelines. Optimisation efficiency and the model accuracy attainable for a fixed time budget suffer if this pipeline configuration space is excessively large. A key research question is whether it is both possible and practical to preemptively avoid costly evaluations of poorly performing ML pipelines by leveraging their historical performance for various ML tasks, i.e. meta-knowledge. The previous experience comes in the form of classifier/regressor accuracy rankings derived from either (1) a substantial but non-exhaustive number of pipeline evaluations made during historical AutoML runs, i.e. 'opportunistic' meta-knowledge, or (2) comprehensive cross-validated evaluations of classifiers/regressors with default hyperparameters, i.e. 'systematic' meta-knowledge. Numerous experiments with the AutoWeka4MCPS package suggest that (1) opportunistic/systematic meta-knowledge can improve ML outcomes, typically in line with how relevant that meta-knowledge is, and (2) configuration-space culling is optimal when it is neither too conservative nor too radical. However, the utility and impact of meta-knowledge depend critically on numerous facets of its generation and exploitation, warranting extensive analysis; these are often overlooked/underappreciated within AutoML and meta-learning literature. In particular, we observe strong sensitivity to the `challenge' of a dataset, i.e. whether specificity in choosing a predictor leads to significantly better performance. Ultimately, identifying `difficult' datasets, thus defined, is crucial to both generating informative meta-knowledge bases and understanding optimal search-space reduction strategies.
An Efficient Video Streaming Architecture with QoS Control for Virtual Desktop Infrastructure in Cloud Computing
Mar 11, 2022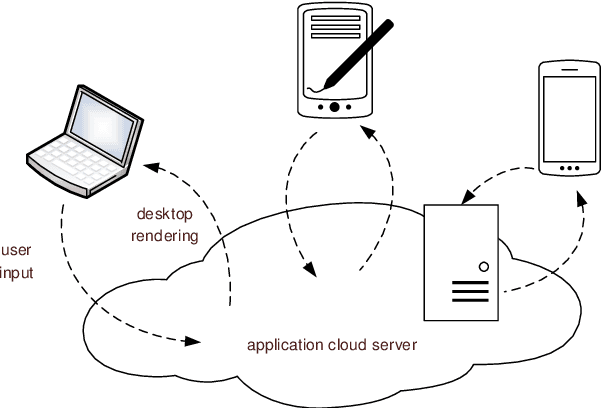

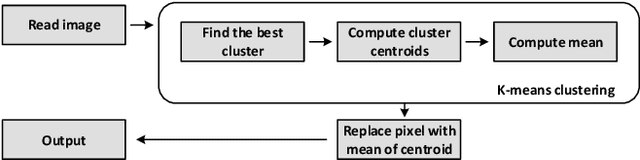
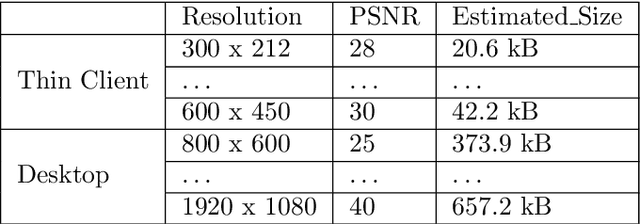
In virtual desktop infrastructure (VDI) environments, the remote display protocol has a big responsibility to transmit video data from a data center-hosted desktop to the endpoint. The protocol must ensure a high level of client perceived end-to-end quality of service (QoS) under heavy work load conditions. Each remote display protocol works differently depending on the network and which applications are being delivered. In healthcare applications, doctors and nurses can use mobile devices directly to monitor patients. Moreover, the ability to implement tasks requiring high consumption of CPU and other resources is applicable to a variety of applications including research and cloud gaming. Such computer games and complex processes will run on powerful cloud servers and the screen contents will be transmitted to the client. TO enable such applications, remote display technology requires further enhancements to meet more stringent requirements on bandwidth and QoS, an to allow realtime operation. In this paper, we present an architecture including flexible QoS control to improve the user quality of experience (QoE). The QoS control is developed based on linear regression modeling using historical network data. Additionally, the architecture includes a novel compression algorithm of 2D images, designed to guarantee the best image quality and to reduce video delay; this algorithm is based on k-means clustering and can satisfy the requirements of realtime onboard processing. Through simulations with a real work dataset collected by the MIT Computer Science and Artificial Lab, we present experimental as well as explain the performance of the QoS system.
Exploring Opportunistic Meta-knowledge to Reduce Search Spaces for Automated Machine Learning
May 01, 2021
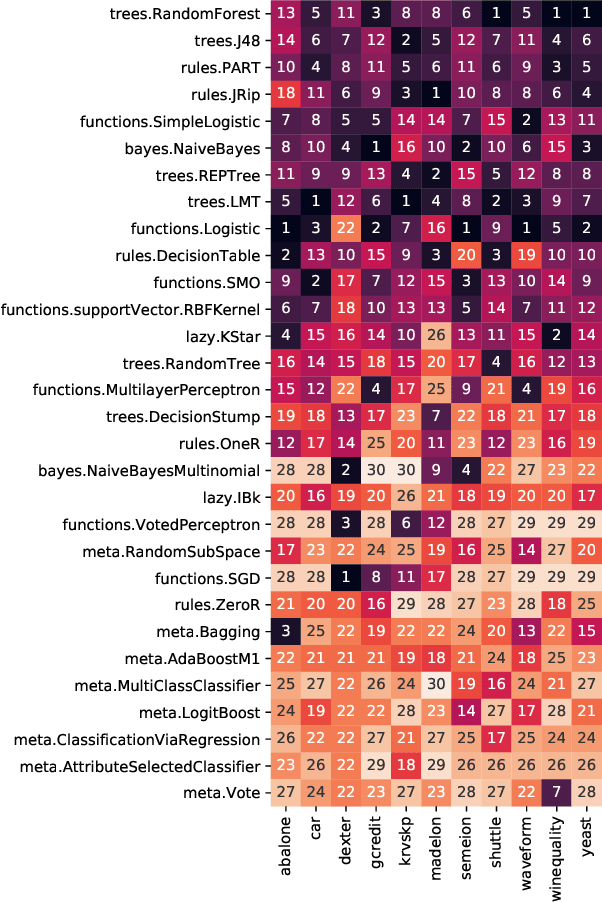
Machine learning (ML) pipeline composition and optimisation have been studied to seek multi-stage ML models, i.e. preprocessor-inclusive, that are both valid and well-performing. These processes typically require the design and traversal of complex configuration spaces consisting of not just individual ML components and their hyperparameters, but also higher-level pipeline structures that link these components together. Optimisation efficiency and resulting ML-model accuracy both suffer if this pipeline search space is unwieldy and excessively large; it becomes an appealing notion to avoid costly evaluations of poorly performing ML components ahead of time. Accordingly, this paper investigates whether, based on previous experience, a pool of available classifiers/regressors can be preemptively culled ahead of initiating a pipeline composition/optimisation process for a new ML problem, i.e. dataset. The previous experience comes in the form of classifier/regressor accuracy rankings derived, with loose assumptions, from a substantial but non-exhaustive number of pipeline evaluations; this meta-knowledge is considered 'opportunistic'. Numerous experiments with the AutoWeka4MCPS package, including ones leveraging similarities between datasets via the relative landmarking method, show that, despite its seeming unreliability, opportunistic meta-knowledge can improve ML outcomes. However, results also indicate that the culling of classifiers/regressors should not be too severe either. In effect, it is better to search through a 'top tier' of recommended predictors than to pin hopes onto one previously supreme performer.
Incremental Search Space Construction for Machine Learning Pipeline Synthesis
Jan 26, 2021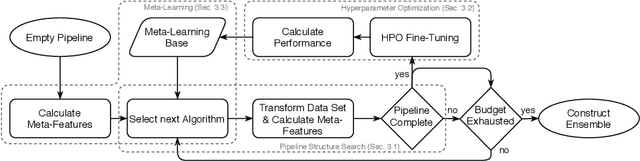
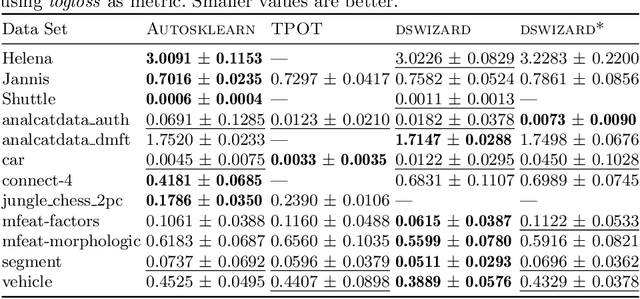
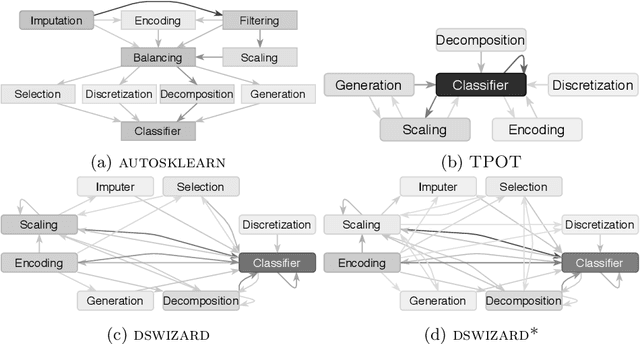
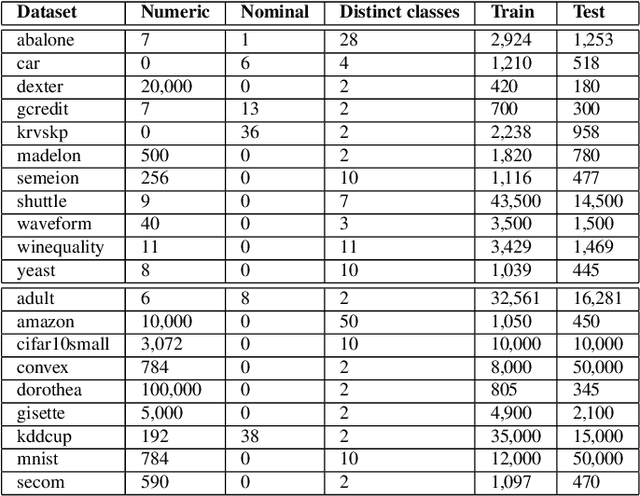
Automated machine learning (AutoML) aims for constructing machine learning (ML) pipelines automatically. Many studies have investigated efficient methods for algorithm selection and hyperparameter optimization. However, methods for ML pipeline synthesis and optimization considering the impact of complex pipeline structures containing multiple preprocessing and classification algorithms have not been studied thoroughly. In this paper, we propose a data-centric approach based on meta-features for pipeline construction and hyperparameter optimization inspired by human behavior. By expanding the pipeline search space incrementally in combination with meta-features of intermediate data sets, we are able to prune the pipeline structure search space efficiently. Consequently, flexible and data set specific ML pipelines can be constructed. We prove the effectiveness and competitiveness of our approach on 28 data sets used in well-established AutoML benchmarks in comparison with state-of-the-art AutoML frameworks.
AutoWeka4MCPS-AVATAR: Accelerating Automated Machine Learning Pipeline Composition and Optimisation
Nov 21, 2020
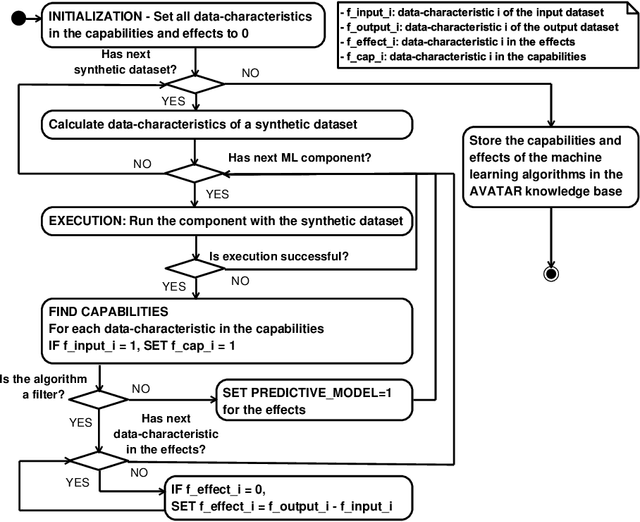
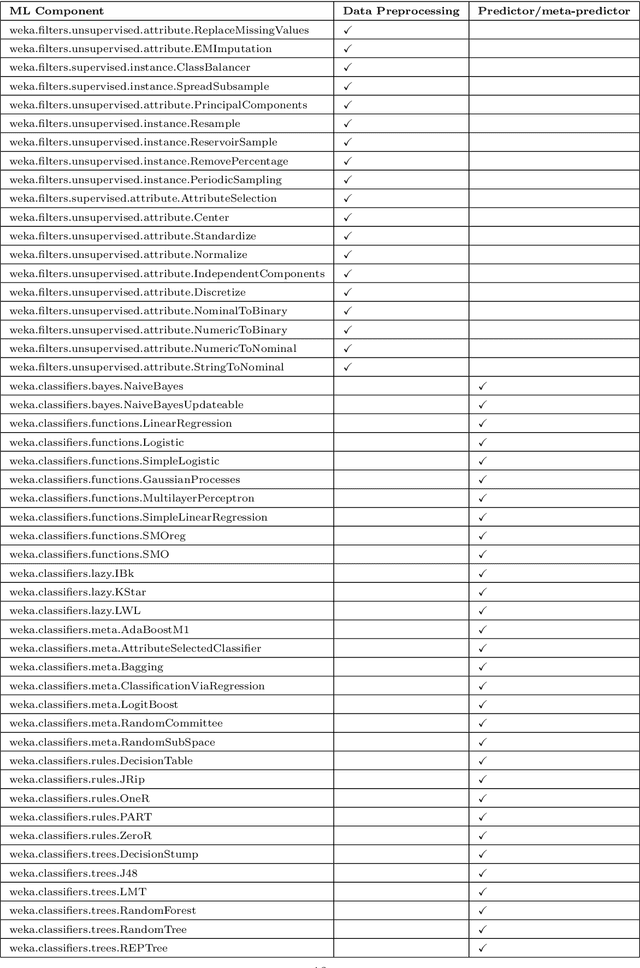
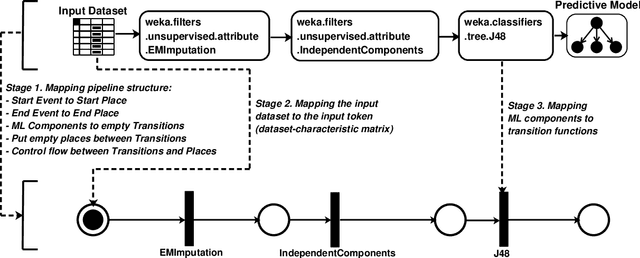
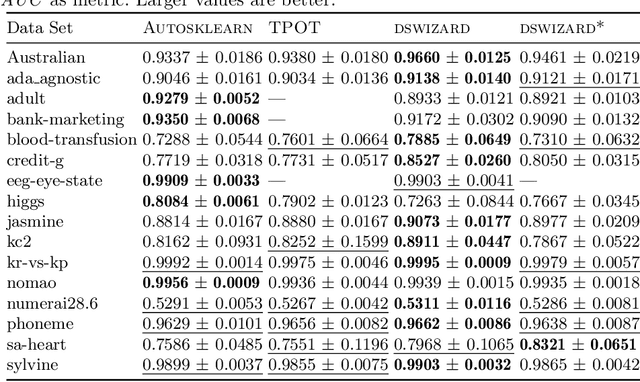
Automated machine learning pipeline (ML) composition and optimisation aim at automating the process of finding the most promising ML pipelines within allocated resources (i.e., time, CPU and memory). Existing methods, such as Bayesian-based and genetic-based optimisation, which are implemented in Auto-Weka, Auto-sklearn and TPOT, evaluate pipelines by executing them. Therefore, the pipeline composition and optimisation of these methods frequently require a tremendous amount of time that prevents them from exploring complex pipelines to find better predictive models. To further explore this research challenge, we have conducted experiments showing that many of the generated pipelines are invalid in the first place, and attempting to execute them is a waste of time and resources. To address this issue, we propose a novel method to evaluate the validity of ML pipelines, without their execution, using a surrogate model (AVATAR). The AVATAR generates a knowledge base by automatically learning the capabilities and effects of ML algorithms on datasets' characteristics. This knowledge base is used for a simplified mapping from an original ML pipeline to a surrogate model which is a Petri net based pipeline. Instead of executing the original ML pipeline to evaluate its validity, the AVATAR evaluates its surrogate model constructed by capabilities and effects of the ML pipeline components and input/output simplified mappings. Evaluating this surrogate model is less resource-intensive than the execution of the original pipeline. As a result, the AVATAR enables the pipeline composition and optimisation methods to evaluate more pipelines by quickly rejecting invalid pipelines. We integrate the AVATAR into the sequential model-based algorithm configuration (SMAC). Our experiments show that when SMAC employs AVATAR, it finds better solutions than on its own.
Improving The Performance Of The K-means Algorithm
May 10, 2020
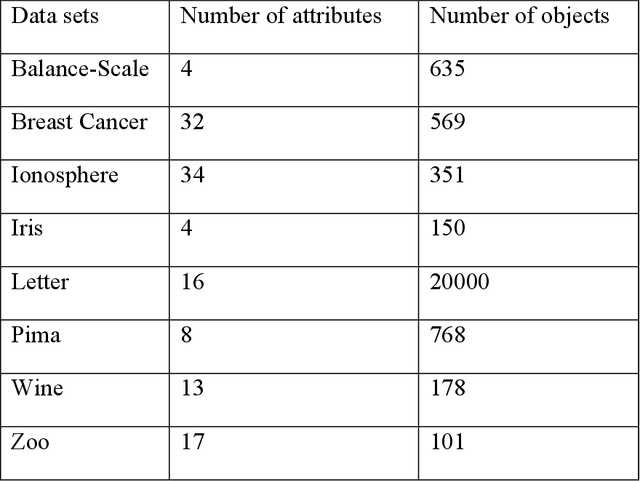

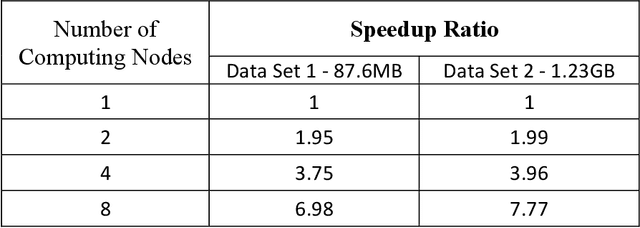
The Incremental K-means (IKM), an improved version of K-means (KM), was introduced to improve the clustering quality of KM significantly. However, the speed of IKM is slower than KM. My thesis proposes two algorithms to speed up IKM while remaining the quality of its clustering result approximately. The first algorithm, called Divisive K-means, improves the speed of IKM by speeding up its splitting process of clusters. Testing with UCI Machine Learning data sets, the new algorithm achieves the empirically global optimum as IKM and has lower complexity, $O(k*log_{2}k*n)$, than IKM, $O(k^{2}n)$. The second algorithm, called Parallel Two-Phase K-means (Par2PK-means), parallelizes IKM by employing the model of Two-Phase K-means. Testing with large data sets, this algorithm attains a good speedup ratio, closing to the linearly speed-up ratio.
AVATAR -- Machine Learning Pipeline Evaluation Using Surrogate Model
Feb 03, 2020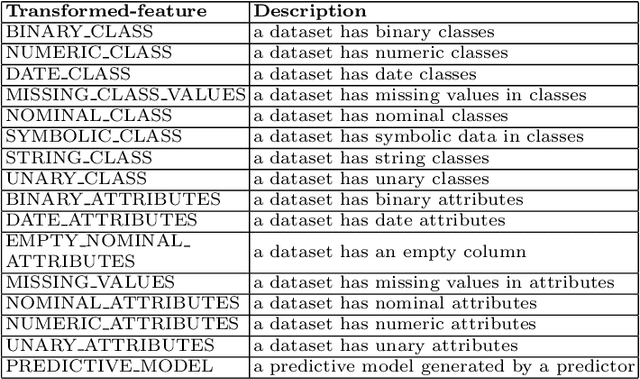
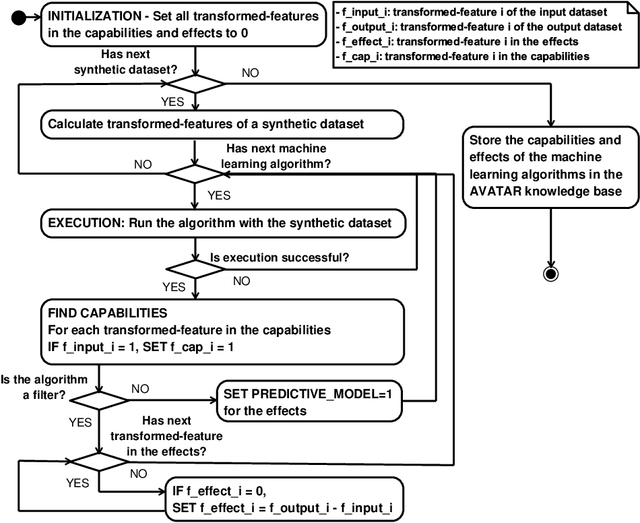
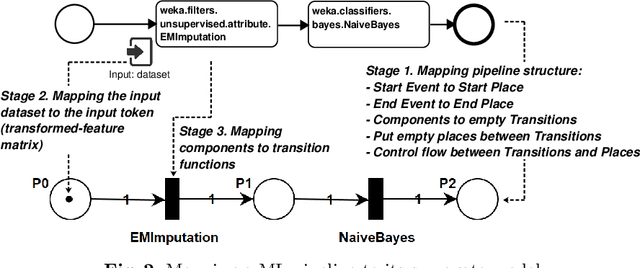
The evaluation of machine learning (ML) pipelines is essential during automatic ML pipeline composition and optimisation. The previous methods such as Bayesian-based and genetic-based optimisation, which are implemented in Auto-Weka, Auto-sklearn and TPOT, evaluate pipelines by executing them. Therefore, the pipeline composition and optimisation of these methods requires a tremendous amount of time that prevents them from exploring complex pipelines to find better predictive models. To further explore this research challenge, we have conducted experiments showing that many of the generated pipelines are invalid, and it is unnecessary to execute them to find out whether they are good pipelines. To address this issue, we propose a novel method to evaluate the validity of ML pipelines using a surrogate model (AVATAR). The AVATAR enables to accelerate automatic ML pipeline composition and optimisation by quickly ignoring invalid pipelines. Our experiments show that the AVATAR is more efficient in evaluating complex pipelines in comparison with the traditional evaluation approaches requiring their execution.