 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoQML: A Framework for Automated Quantum Machine Learning
Feb 28, 2025



Automated Machine Learning (AutoML) has significantly advanced the efficiency of ML-focused software development by automating hyperparameter optimization and pipeline construction, reducing the need for manual intervention. Quantum Machine Learning (QML) offers the potential to surpass classical machine learning (ML) capabilities by utilizing quantum computing. However, the complexity of QML presents substantial entry barriers. We introduce \emph{AutoQML}, a novel framework that adapts the AutoML approach to QML, providing a modular and unified programming interface to facilitate the development of QML pipelines. AutoQML leverages the QML library sQUlearn to support a variety of QML algorithms. The framework is capable of constructing end-to-end pipelines for supervised learning tasks, ensuring accessibility and efficacy. We evaluate AutoQML across four industrial use cases, demonstrating its ability to generate high-performing QML pipelines that are competitive with both classical ML models and manually crafted quantum solutions.
auto-sktime: Automated Time Series Forecasting
Dec 19, 2023



In today's data-driven landscape, time series forecasting is pivotal in decision-making across various sectors. Yet, the proliferation of more diverse time series data, coupled with the expanding landscape of available forecasting methods, poses significant challenges for forecasters. To meet the growing demand for efficient forecasting, we introduce auto-sktime, a novel framework for automated time series forecasting. The proposed framework uses the power of automated machine learning (AutoML) techniques to automate the creation of the entire forecasting pipeline. The framework employs Bayesian optimization, to automatically construct pipelines from statistical, machine learning (ML) and deep neural network (DNN) models. Furthermore, we propose three essential improvements to adapt AutoML to time series data: First, pipeline templates to account for the different supported forecasting models. Second, a novel warm-starting technique to start the optimization from prior optimization runs. Third, we adapt multi-fidelity optimizations to make them applicable to a search space containing statistical, ML and DNN models. Experimental results on 64 diverse real-world time series datasets demonstrate the effectiveness and efficiency of the framework, outperforming traditional methods while requiring minimal human involvement.
Automated Machine Learning for Remaining Useful Life Predictions
Jun 21, 2023



Being able to predict the remaining useful life (RUL) of an engineering system is an important task in prognostics and health management. Recently, data-driven approaches to RUL predictions are becoming prevalent over model-based approaches since no underlying physical knowledge of the engineering system is required. Yet, this just replaces required expertise of the underlying physics with machine learning (ML) expertise, which is often also not available. Automated machine learning (AutoML) promises to build end-to-end ML pipelines automatically enabling domain experts without ML expertise to create their own models. This paper introduces AutoRUL, an AutoML-driven end-to-end approach for automatic RUL predictions. AutoRUL combines fine-tuned standard regression methods to an ensemble with high predictive power. By evaluating the proposed method on eight real-world and synthetic datasets against state-of-the-art hand-crafted models, we show that AutoML provides a viable alternative to hand-crafted data-driven RUL predictions. Consequently, creating RUL predictions can be made more accessible for domain experts using AutoML by eliminating ML expertise from data-driven model construction.
Benchmarking Automated Machine Learning Methods for Price Forecasting Applications
Apr 28, 2023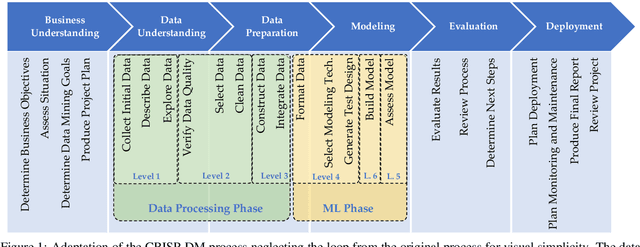
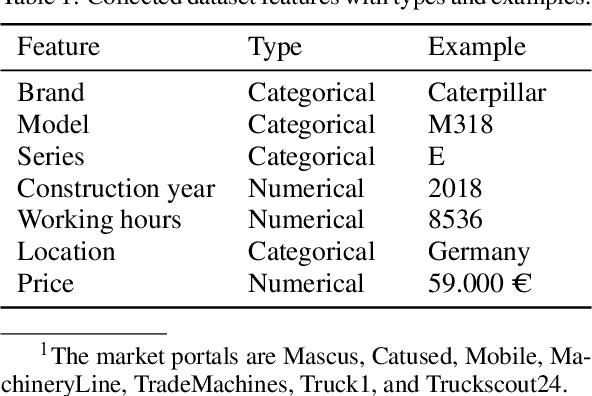
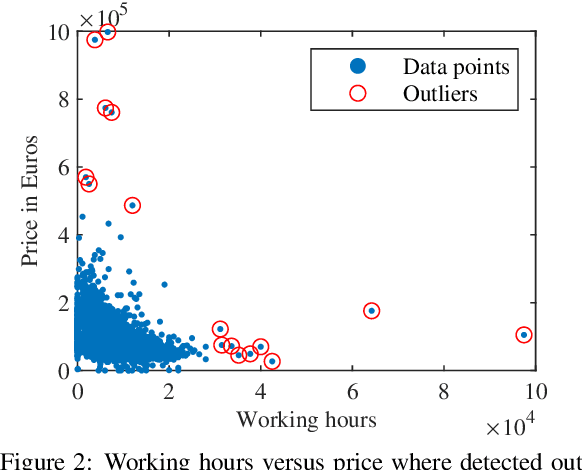

Price forecasting for used construction equipment is a challenging task due to spatial and temporal price fluctuations. It is thus of high interest to automate the forecasting process based on current market data. Even though applying machine learning (ML) to these data represents a promising approach to predict the residual value of certain tools, it is hard to implement for small and medium-sized enterprises due to their insufficient ML expertise. To this end, we demonstrate the possibility of substituting manually created ML pipelines with automated machine learning (AutoML) solutions, which automatically generate the underlying pipelines. We combine AutoML methods with the domain knowledge of the companies. Based on the CRISP-DM process, we split the manual ML pipeline into a machine learning and non-machine learning part. To take all complex industrial requirements into account and to demonstrate the applicability of our new approach, we designed a novel metric named method evaluation score, which incorporates the most important technical and non-technical metrics for quality and usability. Based on this metric, we show in a case study for the industrial use case of price forecasting, that domain knowledge combined with AutoML can weaken the dependence on ML experts for innovative small and medium-sized enterprises which are interested in conducting such solutions.
XAutoML: A Visual Analytics Tool for Establishing Trust in Automated Machine Learning
Feb 24, 2022
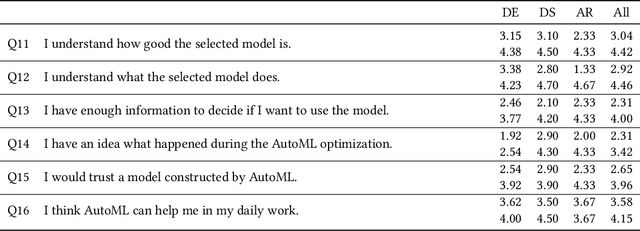
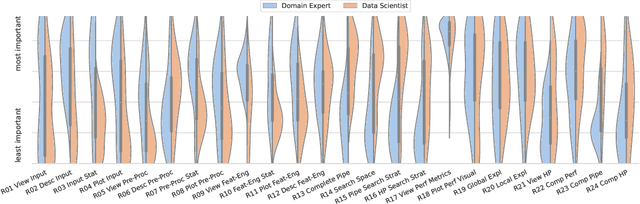

In the last ten years, various automated machine learning (AutoML) systems have been proposed to build end-to-end machine learning (ML) pipelines with minimal human interaction. Even though such automatically synthesized ML pipelines are able to achieve a competitive performance, recent studies have shown that users do not trust models constructed by AutoML due to missing transparency of AutoML systems and missing explanations for the constructed ML pipelines. In a requirements analysis study with 26 domain experts, data scientists, and AutoML researchers from different professions with vastly different expertise in ML, we collect detailed informational needs to establish trust in AutoML. We propose XAutoML, an interactive visual analytics tool for explaining arbitrary AutoML optimization procedures and ML pipelines constructed by AutoML. XAutoML combines interactive visualizations with established techniques from explainable artificial intelligence (XAI) to make the complete AutoML procedure transparent and explainable. By integrating XAutoML with JupyterLab, experienced users can extend the visual analytics with ad-hoc visualizations based on information extracted from XAutoML. We validate our approach in a user study with the same diverse user group from the requirements analysis. All participants were able to extract useful information from XAutoML, leading to a significantly increased trust in ML pipelines produced by AutoML and the AutoML optimization itself.
Incremental Search Space Construction for Machine Learning Pipeline Synthesis
Jan 26, 2021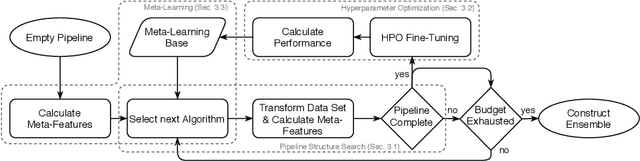
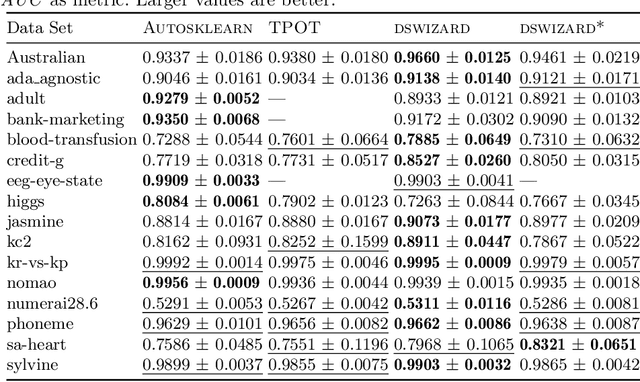
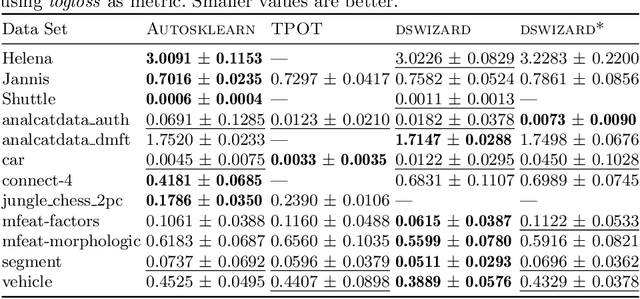
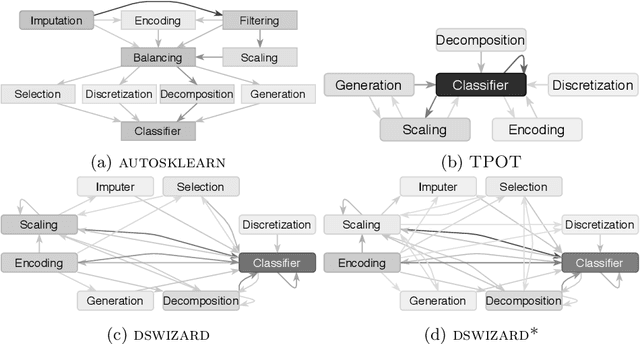
Automated machine learning (AutoML) aims for constructing machine learning (ML) pipelines automatically. Many studies have investigated efficient methods for algorithm selection and hyperparameter optimization. However, methods for ML pipeline synthesis and optimization considering the impact of complex pipeline structures containing multiple preprocessing and classification algorithms have not been studied thoroughly. In this paper, we propose a data-centric approach based on meta-features for pipeline construction and hyperparameter optimization inspired by human behavior. By expanding the pipeline search space incrementally in combination with meta-features of intermediate data sets, we are able to prune the pipeline structure search space efficiently. Consequently, flexible and data set specific ML pipelines can be constructed. We prove the effectiveness and competitiveness of our approach on 28 data sets used in well-established AutoML benchmarks in comparison with state-of-the-art AutoML frameworks.
Survey on Automated Machine Learning
Apr 26, 2019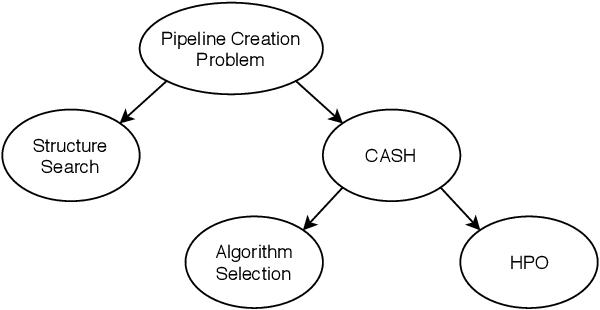

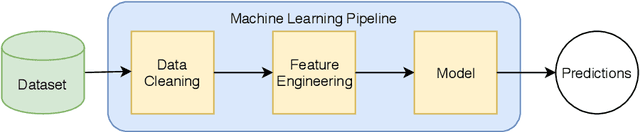
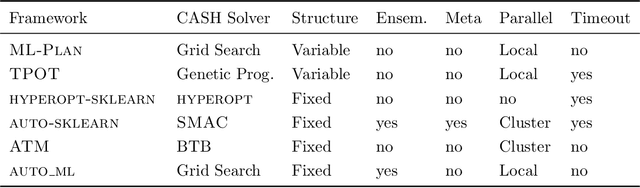
Machine learning has become a vital part in many aspects of our daily life. However, building well performing machine learning applications requires highly specialized data scientists and domain experts. Automated machine learning (AutoML) aims to reduce the demand for data scientists by enabling domain experts to automatically build machine learning applications without extensive knowledge of statistics and machine learning. In this survey, we summarize the recent developments in academy and industry regarding AutoML. First, we introduce a holistic problem formulation. Next, approaches for solving various subproblems of AutoML are presented. Finally, we provide an extensive empirical evaluation of the presented approaches on synthetic and real data.