 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Are RL Hyperparameters Benign? A Study in Offline Goal-Conditioned RL
Feb 05, 2026Hyperparameter sensitivity in Deep Reinforcement Learning (RL) is often accepted as unavoidable. However, it remains unclear whether it is intrinsic to the RL problem or exacerbated by specific training mechanisms. We investigate this question in offline goal-conditioned RL, where data distributions are fixed, and non-stationarity can be explicitly controlled via scheduled shifts in data quality. Additionally, we study varying data qualities under both stationary and non-stationary regimes, and cover two representative algorithms: HIQL (bootstrapped TD-learning) and QRL (quasimetric representation learning). Overall, we observe substantially greater robustness to changes in hyperparameter configurations than commonly reported for online RL, even under controlled non-stationarity. Once modest expert data is present ($\approx$ 20\%), QRL maintains broad, stable near-optimal regions, while HIQL exhibits sharp optima that drift significantly across training phases. To explain this divergence, we introduce an inter-goal gradient alignment diagnostic. We find that bootstrapped objectives exhibit stronger destructive gradient interference, which coincides directly with hyperparameter sensitivity. These results suggest that high sensitivity to changes in hyperparameter configurations during training is not inevitable in RL, but is amplified by the dynamics of bootstrapping, offering a pathway toward more robust algorithmic objective design.
Evolutionary Mapping of Neural Networks to Spatial Accelerators
Feb 04, 2026Spatial accelerators, composed of arrays of compute-memory integrated units, offer an attractive platform for deploying inference workloads with low latency and low energy consumption. However, fully exploiting their architectural advantages typically requires careful, expert-driven mapping of computational graphs to distributed processing elements. In this work, we automate this process by framing the mapping challenge as a black-box optimization problem. We introduce the first evolutionary, hardware-in-the-loop mapping framework for neuromorphic accelerators, enabling users without deep hardware knowledge to deploy workloads more efficiently. We evaluate our approach on Intel Loihi 2, a representative spatial accelerator featuring 152 cores per chip in a 2D mesh. Our method achieves up to 35% reduction in total latency compared to default heuristics on two sparse multi-layer perceptron networks. Furthermore, we demonstrate the scalability of our approach to multi-chip systems and observe an up to 40% improvement in energy efficiency, without explicitly optimizing for it.
Neural Attention Search Linear: Towards Adaptive Token-Level Hybrid Attention Models
Feb 03, 2026The quadratic computational complexity of softmax transformers has become a bottleneck in long-context scenarios. In contrast, linear attention model families provide a promising direction towards a more efficient sequential model. These linear attention models compress past KV values into a single hidden state, thereby efficiently reducing complexity during both training and inference. However, their expressivity remains limited by the size of their hidden state. Previous work proposed interleaving softmax and linear attention layers to reduce computational complexity while preserving expressivity. Nevertheless, the efficiency of these models remains bottlenecked by their softmax attention layers. In this paper, we propose Neural Attention Search Linear (NAtS-L), a framework that applies both linear attention and softmax attention operations within the same layer on different tokens. NAtS-L automatically determines whether a token can be handled by a linear attention model, i.e., tokens that have only short-term impact and can be encoded into fixed-size hidden states, or require softmax attention, i.e., tokens that contain information related to long-term retrieval and need to be preserved for future queries. By searching for optimal Gated DeltaNet and softmax attention combinations across tokens, we show that NAtS-L provides a strong yet efficient token-level hybrid architecture.
Dynamic Hyperparameter Importance for Efficient Multi-Objective Optimization
Jan 06, 2026Choosing a suitable ML model is a complex task that can depend on several objectives, e.g., accuracy, model size, fairness, inference time, or energy consumption. In practice, this requires trading off multiple, often competing, objectives through multi-objective optimization (MOO). However, existing MOO methods typically treat all hyperparameters as equally important, overlooking that hyperparameter importance (HPI) can vary significantly depending on the trade-off between objectives. We propose a novel dynamic optimization approach that prioritizes the most influential hyperparameters based on varying objective trade-offs during the search process, which accelerates empirical convergence and leads to better solutions. Building on prior work on HPI for MOO post-analysis, we now integrate HPI, calculated with HyperSHAP, into the optimization. For this, we leverage the objective weightings naturally produced by the MOO algorithm ParEGO and adapt the configuration space by fixing the unimportant hyperparameters, allowing the search to focus on the important ones. Eventually, we validate our method with diverse tasks from PyMOO and YAHPO-Gym. Empirical results demonstrate improvements in convergence speed and Pareto front quality compared to baselines.
Moments Matter:Stabilizing Policy Optimization using Return Distributions
Jan 05, 2026Deep Reinforcement Learning (RL) agents often learn policies that achieve the same episodic return yet behave very differently, due to a combination of environmental (random transitions, initial conditions, reward noise) and algorithmic (minibatch selection, exploration noise) factors. In continuous control tasks, even small parameter shifts can produce unstable gaits, complicating both algorithm comparison and real-world transfer. Previous work has shown that such instability arises when policy updates traverse noisy neighborhoods and that the spread of post-update return distribution $R(θ)$, obtained by repeatedly sampling minibatches, updating $θ$, and measuring final returns, is a useful indicator of this noise. Although explicitly constraining the policy to maintain a narrow $R(θ)$ can improve stability, directly estimating $R(θ)$ is computationally expensive in high-dimensional settings. We propose an alternative that takes advantage of environmental stochasticity to mitigate update-induced variability. Specifically, we model state-action return distribution through a distributional critic and then bias the advantage function of PPO using higher-order moments (skewness and kurtosis) of this distribution. By penalizing extreme tail behaviors, our method discourages policies from entering parameter regimes prone to instability. We hypothesize that in environments where post-update critic values align poorly with post-update returns, standard PPO struggles to produce a narrow $R(θ)$. In such cases, our moment-based correction narrows $R(θ)$, improving stability by up to 75% in Walker2D, while preserving comparable evaluation returns.
Best Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
Revisiting Learning Rate Control
Jul 02, 2025The learning rate is one of the most important hyperparameters in deep learning, and how to control it is an active area within both AutoML and deep learning research. Approaches for learning rate control span from classic optimization to online scheduling based on gradient statistics. This paper compares paradigms to assess the current state of learning rate control. We find that methods from multi-fidelity hyperparameter optimization, fixed-hyperparameter schedules, and hyperparameter-free learning often perform very well on selected deep learning tasks but are not reliable across settings. This highlights the need for algorithm selection methods in learning rate control, which have been neglected so far by both the AutoML and deep learning communities. We also observe a trend of hyperparameter optimization approaches becoming less effective as models and tasks grow in complexity, even when combined with multi-fidelity approaches for more expensive model trainings. A focus on more relevant test tasks and new promising directions like finetunable methods and meta-learning will enable the AutoML community to significantly strengthen its impact on this crucial factor in deep learning.
Growing with Experience: Growing Neural Networks in Deep Reinforcement Learning
Jun 13, 2025While increasingly large models have revolutionized much of the machine learning landscape, training even mid-sized networks for Reinforcement Learning (RL) is still proving to be a struggle. This, however, severely limits the complexity of policies we are able to learn. To enable increased network capacity while maintaining network trainability, we propose GrowNN, a simple yet effective method that utilizes progressive network growth during training. We start training a small network to learn an initial policy. Then we add layers without changing the encoded function. Subsequent updates can utilize the added layers to learn a more expressive policy, adding capacity as the policy's complexity increases. GrowNN can be seamlessly integrated into most existing RL agents. Our experiments on MiniHack and Mujoco show improved agent performance, with incrementally GrowNN-deeper networks outperforming their respective static counterparts of the same size by up to 48% on MiniHack Room and 72% on Ant.
carps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025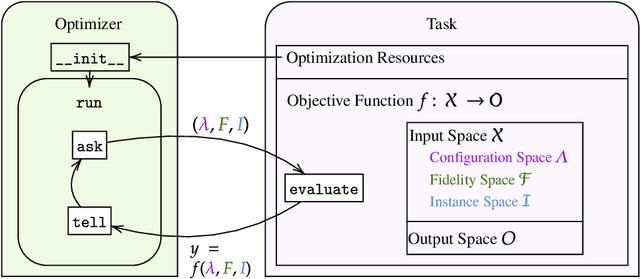

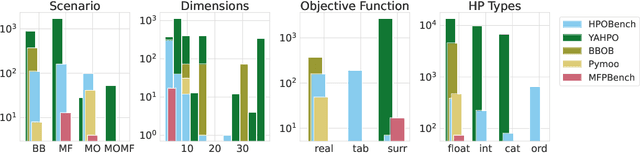
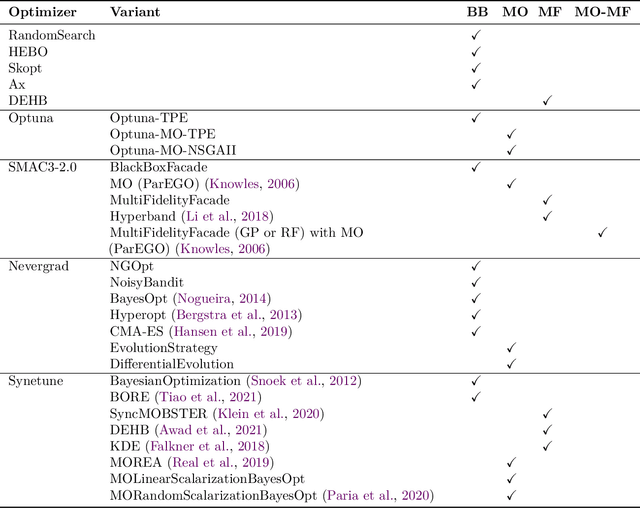
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
Auto-nnU-Net: Towards Automated Medical Image Segmentation
May 22, 2025Medical Image Segmentation (MIS) includes diverse tasks, from bone to organ segmentation, each with its own challenges in finding the best segmentation model. The state-of-the-art AutoML-related MIS-framework nnU-Net automates many aspects of model configuration but remains constrained by fixed hyperparameters and heuristic design choices. As a full-AutoML framework for MIS, we propose Auto-nnU-Net, a novel nnU-Net variant enabling hyperparameter optimization (HPO), neural architecture search (NAS), and hierarchical NAS (HNAS). Additionally, we propose Regularized PriorBand to balance model accuracy with the computational resources required for training, addressing the resource constraints often faced in real-world medical settings that limit the feasibility of extensive training procedures. We evaluate our approach across diverse MIS datasets from the well-established Medical Segmentation Decathlon, analyzing the impact of AutoML techniques on segmentation performance, computational efficiency, and model design choices. The results demonstrate that our AutoML approach substantially improves the segmentation performance of nnU-Net on 6 out of 10 datasets and is on par on the other datasets while maintaining practical resource requirements. Our code is available at https://github.com/LUH-AI/AutonnUNet.