 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of LLMs in retrieving food and nutritional context for RAG systems
Mar 11, 2026In this article, we evaluate four Large Language Models (LLMs) and their effectiveness at retrieving data within a specialized Retrieval-Augmented Generation (RAG) system, using a comprehensive food composition database. Our method is focused on the LLMs ability to translate natural language queries into structured metadata filters, enabling efficient retrieval via a Chroma vector database. By achieving high accuracy in this critical retrieval step, we demonstrate that LLMs can serve as an accessible, high-performance tool, drastically reducing the manual effort and technical expertise previously required for domain experts, such as food compilers and nutritionists, to leverage complex food and nutrition data. However, despite the high performance on easy and moderately complex queries, our analysis of difficult questions reveals that reliable retrieval remains challenging when queries involve non-expressible constraints. These findings demonstrate that LLM-driven metadata filtering excels when constraints can be explicitly expressed, but struggles when queries exceed the representational scope of the metadata format.
Fusing Semantic, Lexical, and Domain Perspectives for Recipe Similarity Estimation
Mar 11, 2026This research focuses on developing advanced methods for assessing similarity between recipes by combining different sources of information and analytical approaches. We explore the semantic, lexical, and domain similarity of food recipes, evaluated through the analysis of ingredients, preparation methods, and nutritional attributes. A web-based interface was developed to allow domain experts to validate the combined similarity results. After evaluating 318 recipe pairs, experts agreed on 255 (80%). The evaluation of expert assessments enables the estimation of which similarity aspects--lexical, semantic, or nutritional--are most influential in expert decision-making. The application of these methods has broad implications in the food industry and supports the development of personalized diets, nutrition recommendations, and automated recipe generation systems.
Beyond Fine-Tuning: Robust Food Entity Linking under Ontology Drift with FoodOntoRAG
Mar 10, 2026Standardizing food terms from product labels and menus into ontology concepts is a prerequisite for trustworthy dietary assessment and safety reporting. The dominant approach to Named Entity Linking (NEL) in the food and nutrition domains fine-tunes Large Language Models (LLMs) on task-specific corpora. Although effective, fine-tuning incurs substantial computational cost, ties models to a particular ontology snapshot (i.e., version), and degrades under ontology drift. This paper presents FoodOntoRAG, a model- and ontology-agnostic pipeline that performs few-shot NEL by retrieving candidate entities from domain ontologies and conditioning an LLM on structured evidence (food labels, synonyms, definitions, and relations). A hybrid lexical--semantic retriever enumerates candidates; a selector agent chooses a best match with rationale; a separate scorer agent calibrates confidence; and, when confidence falls below a threshold, a synonym generator agent proposes reformulations to re-enter the loop. The pipeline approaches state-of-the-art accuracy while revealing gaps and inconsistencies in existing annotations. The design avoids fine-tuning, improves robustness to ontology evolution, and yields interpretable decisions through grounded justifications.
Quantifying the Impact of Modules and Their Interactions in the PSO-X Framework
Jan 07, 2026The PSO-X framework incorporates dozens of modules that have been proposed for solving single-objective continuous optimization problems using particle swarm optimization. While modular frameworks enable users to automatically generate and configure algorithms tailored to specific optimization problems, the complexity of this process increases with the number of modules in the framework and the degrees of freedom defined for their interaction. Understanding how modules affect the performance of algorithms for different problems is critical to making the process of finding effective implementations more efficient and identifying promising areas for further investigation. Despite their practical applications and scientific relevance, there is a lack of empirical studies investigating which modules matter most in modular optimization frameworks and how they interact. In this paper, we analyze the performance of 1424 particle swarm optimization algorithms instantiated from the PSO-X framework on the 25 functions in the CEC'05 benchmark suite with 10 and 30 dimensions. We use functional ANOVA to quantify the impact of modules and their combinations on performance in different problem classes. In practice, this allows us to identify which modules have greater influence on PSO-X performance depending on problem features such as multimodality, mathematical transformations and varying dimensionality. We then perform a cluster analysis to identify groups of problem classes that share similar module effect patterns. Our results show low variability in the importance of modules in all problem classes, suggesting that particle swarm optimization performance is driven by a few influential modules.
FoodSEM: Large Language Model Specialized in Food Named-Entity Linking
Sep 26, 2025This paper introduces FoodSEM, a state-of-the-art fine-tuned open-source large language model (LLM) for named-entity linking (NEL) to food-related ontologies. To the best of our knowledge, food NEL is a task that cannot be accurately solved by state-of-the-art general-purpose (large) language models or custom domain-specific models/systems. Through an instruction-response (IR) scenario, FoodSEM links food-related entities mentioned in a text to several ontologies, including FoodOn, SNOMED-CT, and the Hansard taxonomy. The FoodSEM model achieves state-of-the-art performance compared to related models/systems, with F1 scores even reaching 98% on some ontologies and datasets. The presented comparative analyses against zero-shot, one-shot, and few-shot LLM prompting baselines further highlight FoodSEM's superior performance over its non-fine-tuned version. By making FoodSEM and its related resources publicly available, the main contributions of this article include (1) publishing a food-annotated corpora into an IR format suitable for LLM fine-tuning/evaluation, (2) publishing a robust model to advance the semantic understanding of text in the food domain, and (3) providing a strong baseline on food NEL for future benchmarking.
ClustOpt: A Clustering-based Approach for Representing and Visualizing the Search Dynamics of Numerical Metaheuristic Optimization Algorithms
Jul 03, 2025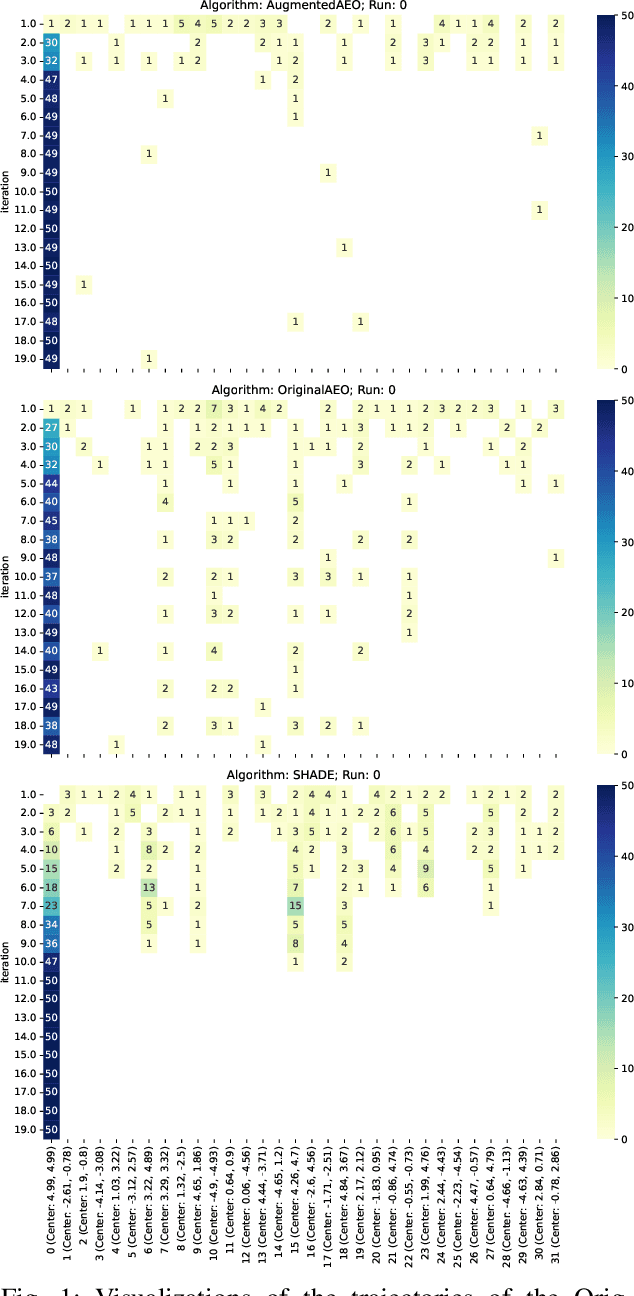
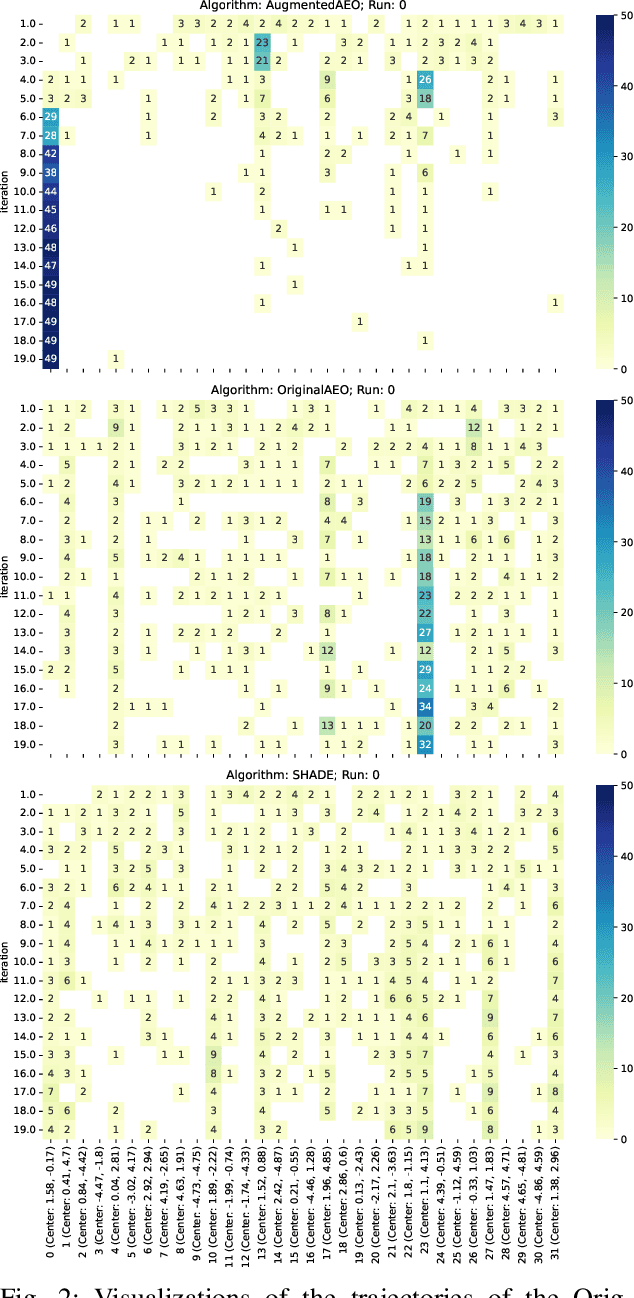
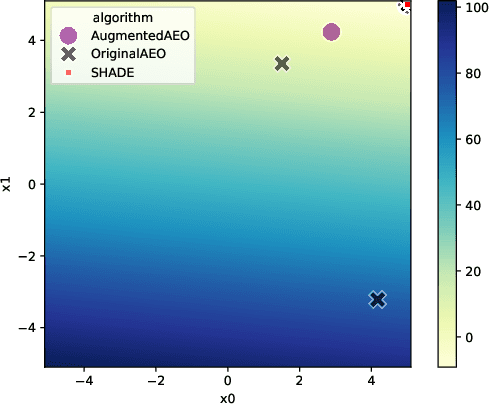
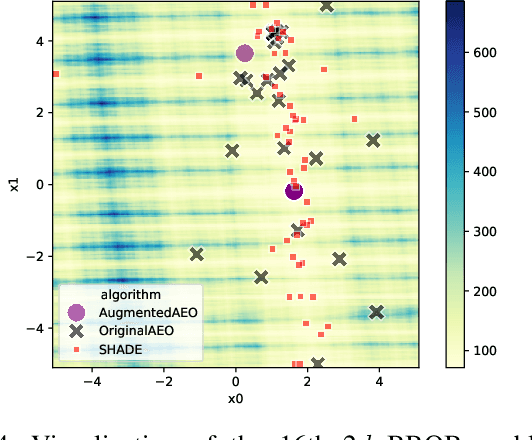
Understanding the behavior of numerical metaheuristic optimization algorithms is critical for advancing their development and application. Traditional visualization techniques, such as convergence plots, trajectory mapping, and fitness landscape analysis, often fall short in illustrating the structural dynamics of the search process, especially in high-dimensional or complex solution spaces. To address this, we propose a novel representation and visualization methodology that clusters solution candidates explored by the algorithm and tracks the evolution of cluster memberships across iterations, offering a dynamic and interpretable view of the search process. Additionally, we introduce two metrics - algorithm stability and algorithm similarity- to quantify the consistency of search trajectories across runs of an individual algorithm and the similarity between different algorithms, respectively. We apply this methodology to a set of ten numerical metaheuristic algorithms, revealing insights into their stability and comparative behaviors, thereby providing a deeper understanding of their search dynamics.
Tracing the Interactions of Modular CMA-ES Configurations Across Problem Landscapes
Jul 03, 2025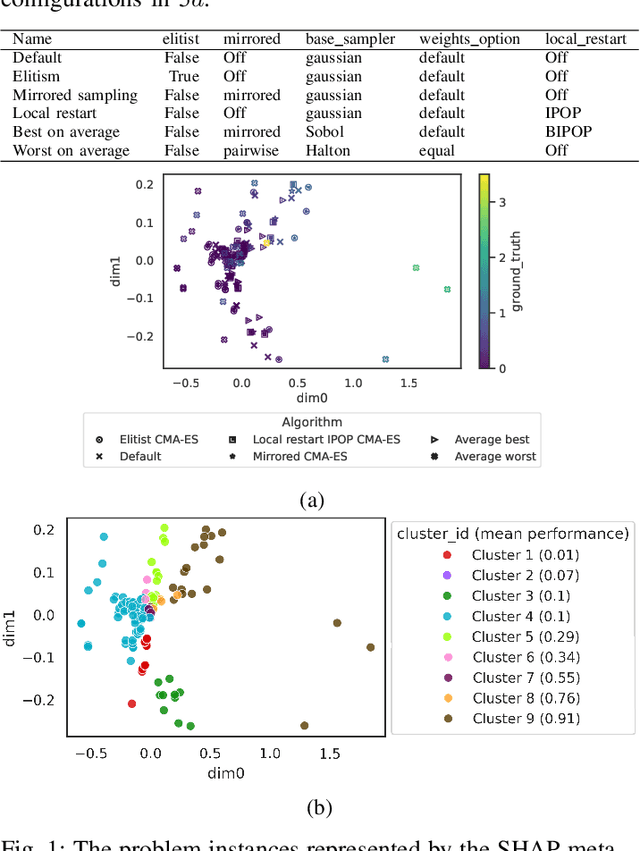
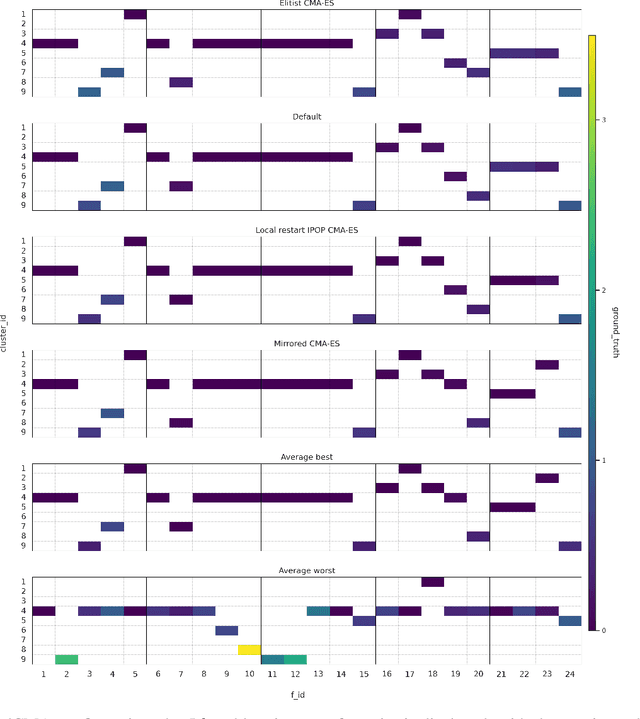
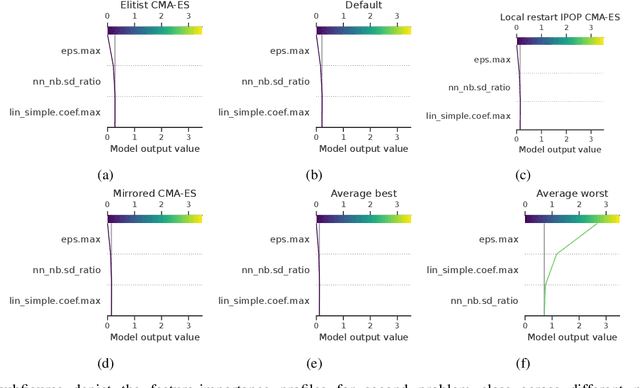
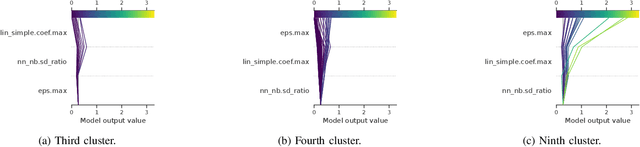
This paper leverages the recently introduced concept of algorithm footprints to investigate the interplay between algorithm configurations and problem characteristics. Performance footprints are calculated for six modular variants of the CMA-ES algorithm (modCMA), evaluated on 24 benchmark problems from the BBOB suite, across two-dimensional settings: 5-dimensional and 30-dimensional. These footprints provide insights into why different configurations of the same algorithm exhibit varying performance and identify the problem features influencing these outcomes. Our analysis uncovers shared behavioral patterns across configurations due to common interactions with problem properties, as well as distinct behaviors on the same problem driven by differing problem features. The results demonstrate the effectiveness of algorithm footprints in enhancing interpretability and guiding configuration choices.
Adaptive Estimation of the Number of Algorithm Runs in Stochastic Optimization
Jul 02, 2025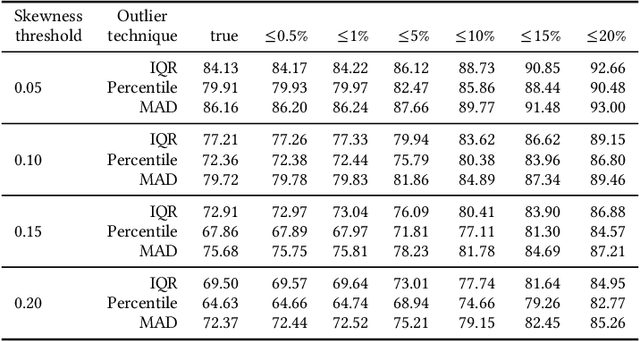
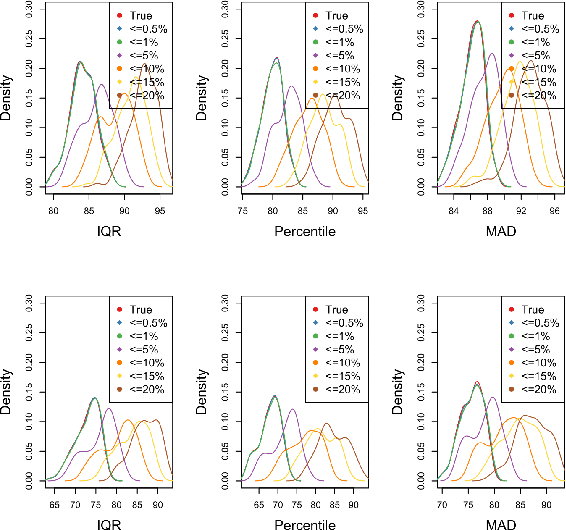
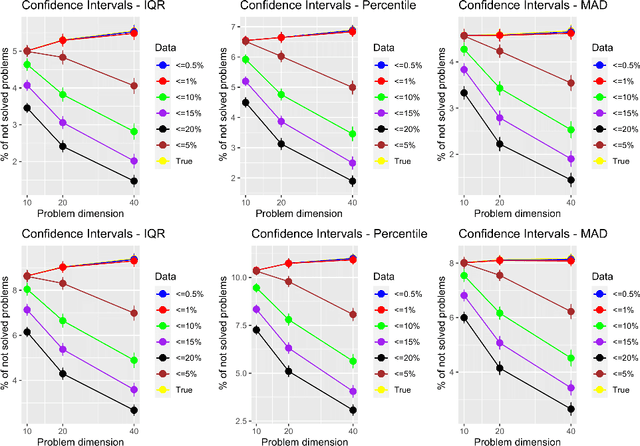
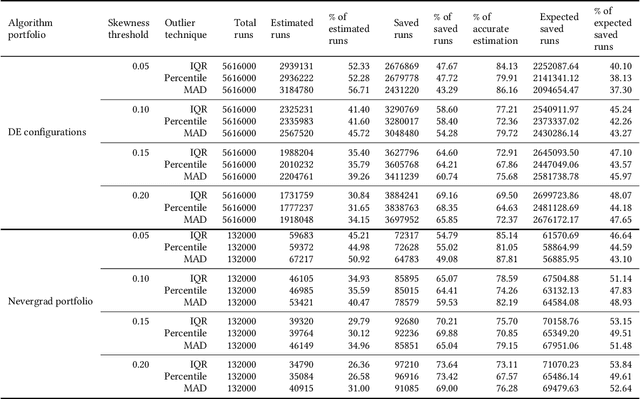
Determining the number of algorithm runs is a critical aspect of experimental design, as it directly influences the experiment's duration and the reliability of its outcomes. This paper introduces an empirical approach to estimating the required number of runs per problem instance for accurate estimation of the performance of the continuous single-objective stochastic optimization algorithm. The method leverages probability theory, incorporating a robustness check to identify significant imbalances in the data distribution relative to the mean, and dynamically adjusts the number of runs during execution as an online approach. The proposed methodology was extensively tested across two algorithm portfolios (104 Differential Evolution configurations and the Nevergrad portfolio) and the COCO benchmark suite, totaling 5748000 runs. The results demonstrate 82% - 95% accuracy in estimations across different algorithms, allowing a reduction of approximately 50% in the number of runs without compromising optimization outcomes. This online calculation of required runs not only improves benchmarking efficiency, but also contributes to energy reduction, fostering a more environmentally sustainable computing ecosystem.
Customized Exploration of Landscape Features Driving Multi-Objective Combinatorial Optimization Performance
Jul 02, 2025We present an analysis of landscape features for predicting the performance of multi-objective combinatorial optimization algorithms. We consider features from the recently proposed compressed Pareto Local Optimal Solutions Networks (C-PLOS-net) model of combinatorial landscapes. The benchmark instances are a set of rmnk-landscapes with 2 and 3 objectives and various levels of ruggedness and objective correlation. We consider the performance of three algorithms -- Pareto Local Search (PLS), Global Simple EMO Optimizer (GSEMO), and Non-dominated Sorting Genetic Algorithm (NSGA-II) - using the resolution and hypervolume metrics. Our tailored analysis reveals feature combinations that influence algorithm performance specific to certain landscapes. This study provides deeper insights into feature importance, tailored to specific rmnk-landscapes and algorithms.
Comparing Optimization Algorithms Through the Lens of Search Behavior Analysis
Jul 02, 2025The field of numerical optimization has recently seen a surge in the development of "novel" metaheuristic algorithms, inspired by metaphors derived from natural or human-made processes, which have been widely criticized for obscuring meaningful innovations and failing to distinguish themselves from existing approaches. Aiming to address these concerns, we investigate the applicability of statistical tests for comparing algorithms based on their search behavior. We utilize the cross-match statistical test to compare multivariate distributions and assess the solutions produced by 114 algorithms from the MEALPY library. These findings are incorporated into an empirical analysis aiming to identify algorithms with similar search behaviors.