 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Estimation of the Number of Algorithm Runs in Stochastic Optimization
Jul 02, 2025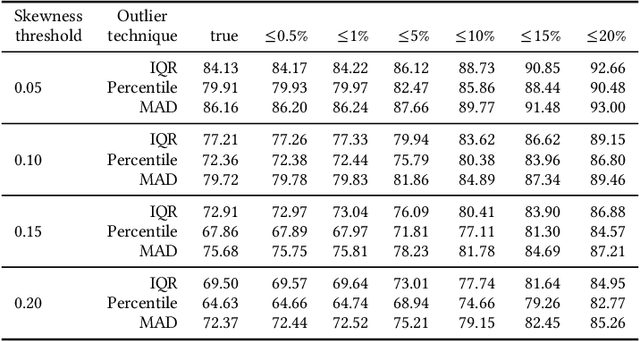
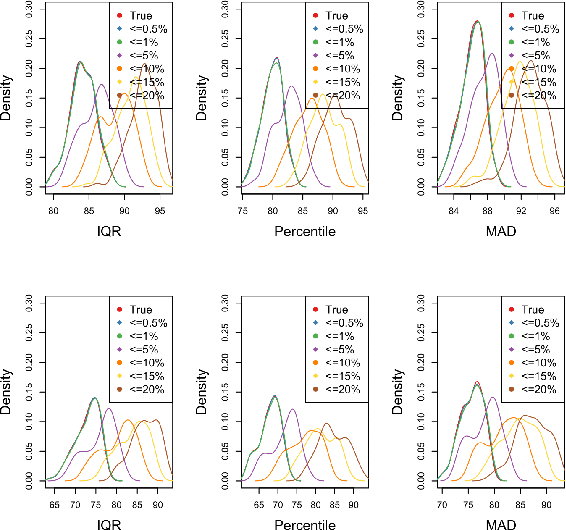
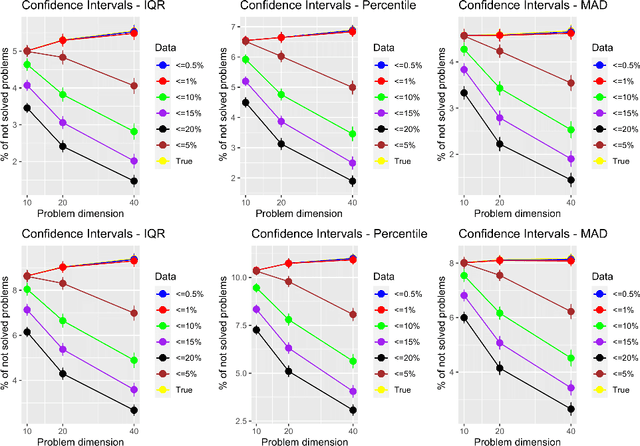
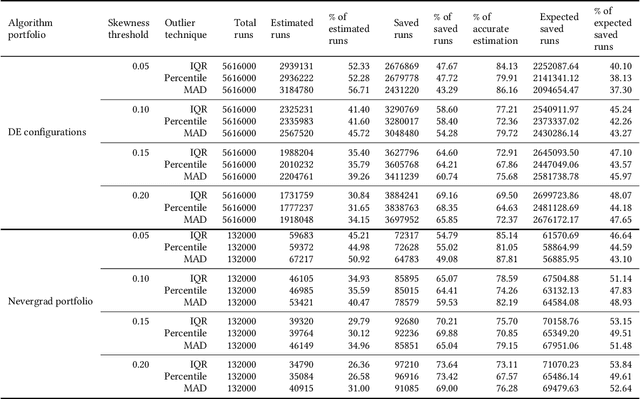
Determining the number of algorithm runs is a critical aspect of experimental design, as it directly influences the experiment's duration and the reliability of its outcomes. This paper introduces an empirical approach to estimating the required number of runs per problem instance for accurate estimation of the performance of the continuous single-objective stochastic optimization algorithm. The method leverages probability theory, incorporating a robustness check to identify significant imbalances in the data distribution relative to the mean, and dynamically adjusts the number of runs during execution as an online approach. The proposed methodology was extensively tested across two algorithm portfolios (104 Differential Evolution configurations and the Nevergrad portfolio) and the COCO benchmark suite, totaling 5748000 runs. The results demonstrate 82% - 95% accuracy in estimations across different algorithms, allowing a reduction of approximately 50% in the number of runs without compromising optimization outcomes. This online calculation of required runs not only improves benchmarking efficiency, but also contributes to energy reduction, fostering a more environmentally sustainable computing ecosystem.
DynamoRep: Trajectory-Based Population Dynamics for Classification of Black-box Optimization Problems
Jun 08, 2023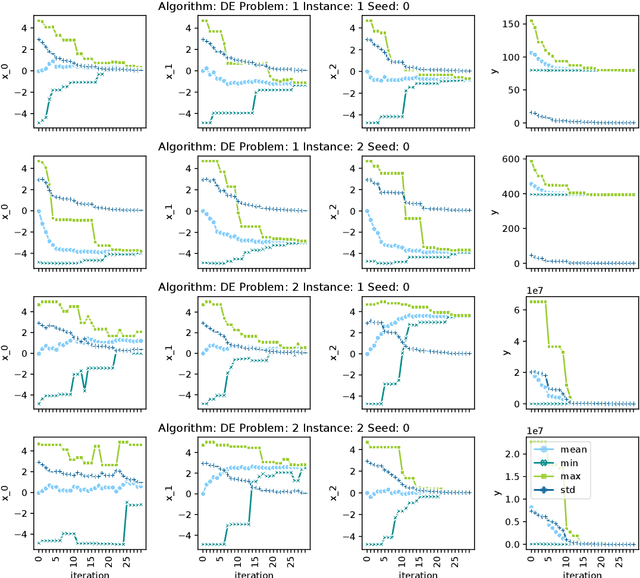
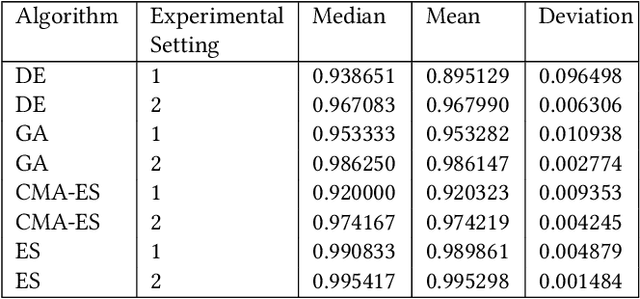
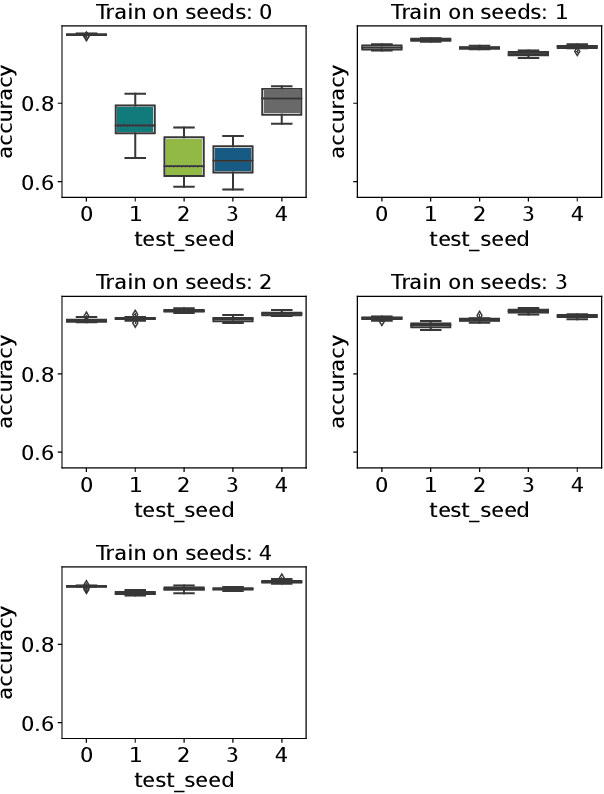
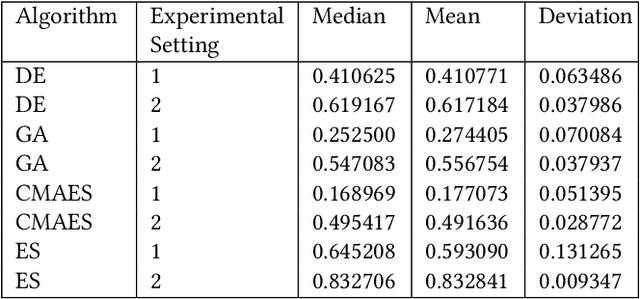
The application of machine learning (ML) models to the analysis of optimization algorithms requires the representation of optimization problems using numerical features. These features can be used as input for ML models that are trained to select or to configure a suitable algorithm for the problem at hand. Since in pure black-box optimization information about the problem instance can only be obtained through function evaluation, a common approach is to dedicate some function evaluations for feature extraction, e.g., using random sampling. This approach has two key downsides: (1) It reduces the budget left for the actual optimization phase, and (2) it neglects valuable information that could be obtained from a problem-solver interaction. In this paper, we propose a feature extraction method that describes the trajectories of optimization algorithms using simple descriptive statistics. We evaluate the generated features for the task of classifying problem classes from the Black Box Optimization Benchmarking (BBOB) suite. We demonstrate that the proposed DynamoRep features capture enough information to identify the problem class on which the optimization algorithm is running, achieving a mean classification accuracy of 95% across all experiments.
Algorithm Instance Footprint: Separating Easily Solvable and Challenging Problem Instances
Jun 01, 2023



In black-box optimization, it is essential to understand why an algorithm instance works on a set of problem instances while failing on others and provide explanations of its behavior. We propose a methodology for formulating an algorithm instance footprint that consists of a set of problem instances that are easy to be solved and a set of problem instances that are difficult to be solved, for an algorithm instance. This behavior of the algorithm instance is further linked to the landscape properties of the problem instances to provide explanations of which properties make some problem instances easy or challenging. The proposed methodology uses meta-representations that embed the landscape properties of the problem instances and the performance of the algorithm into the same vector space. These meta-representations are obtained by training a supervised machine learning regression model for algorithm performance prediction and applying model explainability techniques to assess the importance of the landscape features to the performance predictions. Next, deterministic clustering of the meta-representations demonstrates that using them captures algorithm performance across the space and detects regions of poor and good algorithm performance, together with an explanation of which landscape properties are leading to it.
Assessing the Generalizability of a Performance Predictive Model
May 31, 2023



A key component of automated algorithm selection and configuration, which in most cases are performed using supervised machine learning (ML) methods is a good-performing predictive model. The predictive model uses the feature representation of a set of problem instances as input data and predicts the algorithm performance achieved on them. Common machine learning models struggle to make predictions for instances with feature representations not covered by the training data, resulting in poor generalization to unseen problems. In this study, we propose a workflow to estimate the generalizability of a predictive model for algorithm performance, trained on one benchmark suite to another. The workflow has been tested by training predictive models across benchmark suites and the results show that generalizability patterns in the landscape feature space are reflected in the performance space.
Sensitivity Analysis of RF+clust for Leave-one-problem-out Performance Prediction
May 30, 2023Leave-one-problem-out (LOPO) performance prediction requires machine learning (ML) models to extrapolate algorithms' performance from a set of training problems to a previously unseen problem. LOPO is a very challenging task even for state-of-the-art approaches. Models that work well in the easier leave-one-instance-out scenario often fail to generalize well to the LOPO setting. To address the LOPO problem, recent work suggested enriching standard random forest (RF) performance regression models with a weighted average of algorithms' performance on training problems that are considered similar to a test problem. More precisely, in this RF+clust approach, the weights are chosen proportionally to the distances of the problems in some feature space. Here in this work, we extend the RF+clust approach by adjusting the distance-based weights with the importance of the features for performance regression. That is, instead of considering cosine distance in the feature space, we consider a weighted distance measure, with weights depending on the relevance of the feature for the regression model. Our empirical evaluation of the modified RF+clust approach on the CEC 2014 benchmark suite confirms its advantages over the naive distance measure. However, we also observe room for improvement, in particular with respect to more expressive feature portfolios.
SELECTOR: Selecting a Representative Benchmark Suite for Reproducible Statistical Comparison
Apr 25, 2022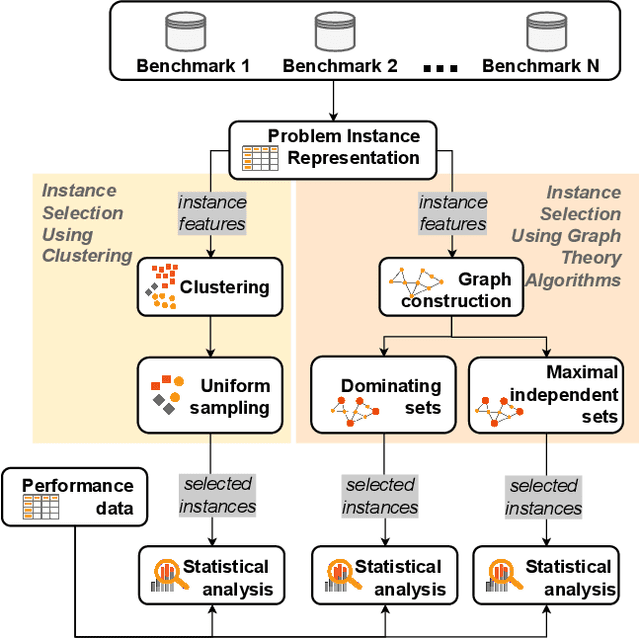

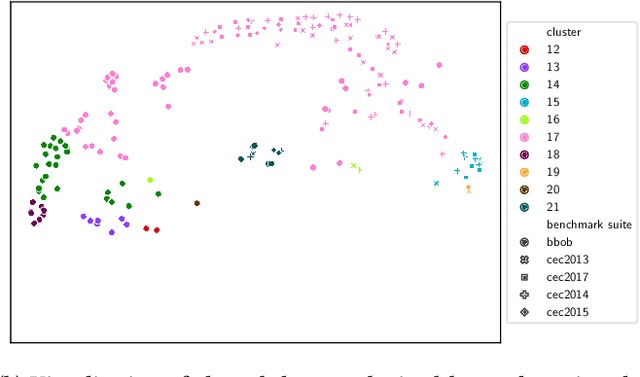
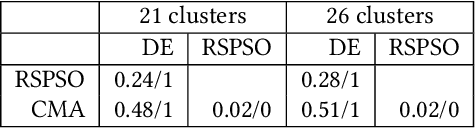
Fair algorithm evaluation is conditioned on the existence of high-quality benchmark datasets that are non-redundant and are representative of typical optimization scenarios. In this paper, we evaluate three heuristics for selecting diverse problem instances which should be involved in the comparison of optimization algorithms in order to ensure robust statistical algorithm performance analysis. The first approach employs clustering to identify similar groups of problem instances and subsequent sampling from each cluster to construct new benchmarks, while the other two approaches use graph algorithms for identifying dominating and maximal independent sets of nodes. We demonstrate the applicability of the proposed heuristics by performing a statistical performance analysis of five portfolios consisting of three optimization algorithms on five of the most commonly used optimization benchmarks. The results indicate that the statistical analyses of the algorithms' performance, conducted on each benchmark separately, produce conflicting outcomes, which can be used to give a false indication of the superiority of one algorithm over another. On the other hand, when the analysis is conducted on the problem instances selected with the proposed heuristics, which uniformly cover the problem landscape, the statistical outcomes are robust and consistent.
The Importance of Landscape Features for Performance Prediction of Modular CMA-ES Variants
Apr 15, 2022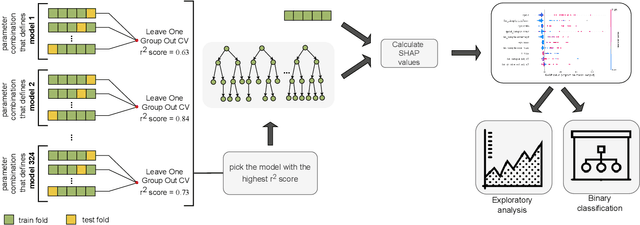

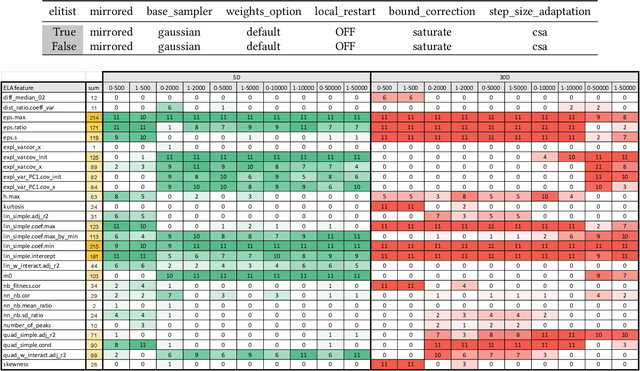
Selecting the most suitable algorithm and determining its hyperparameters for a given optimization problem is a challenging task. Accurately predicting how well a certain algorithm could solve the problem is hence desirable. Recent studies in single-objective numerical optimization show that supervised machine learning methods can predict algorithm performance using landscape features extracted from the problem instances. Existing approaches typically treat the algorithms as black-boxes, without consideration of their characteristics. To investigate in this work if a selection of landscape features that depends on algorithms properties could further improve regression accuracy, we regard the modular CMA-ES framework and estimate how much each landscape feature contributes to the best algorithm performance regression models. Exploratory data analysis performed on this data indicate that the set of most relevant features does not depend on the configuration of individual modules, but the influence that these features have on regression accuracy does. In addition, we have shown that by using classifiers that take the features relevance on the model accuracy, we are able to predict the status of individual modules in the CMA-ES configurations.
Explainable Landscape Analysis in Automated Algorithm Performance Prediction
Mar 22, 2022
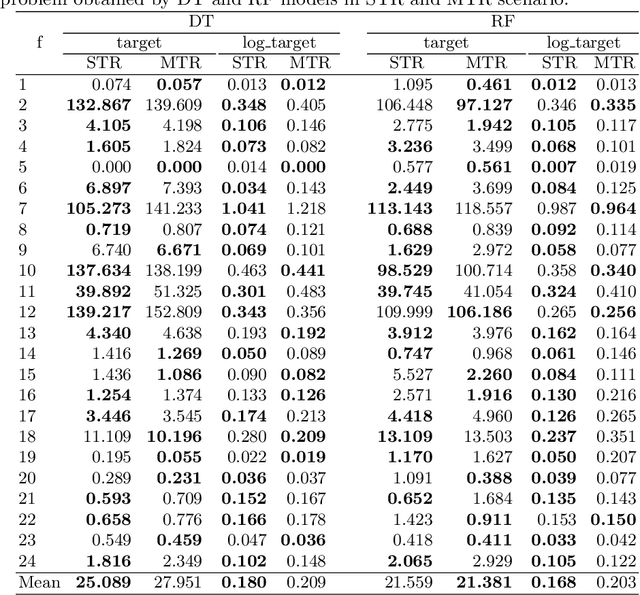

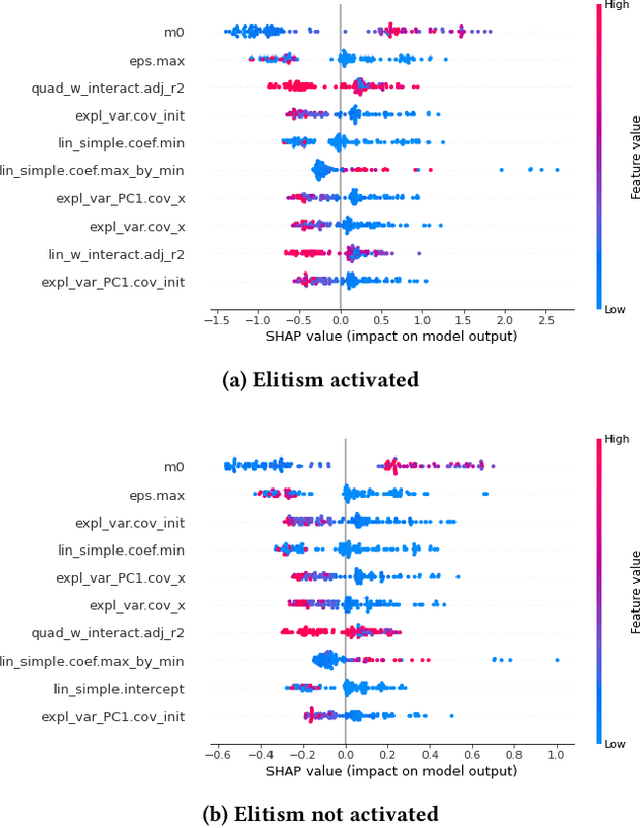
Predicting the performance of an optimization algorithm on a new problem instance is crucial in order to select the most appropriate algorithm for solving that problem instance. For this purpose, recent studies learn a supervised machine learning (ML) model using a set of problem landscape features linked to the performance achieved by the optimization algorithm. However, these models are black-box with the only goal of achieving good predictive performance, without providing explanations which landscape features contribute the most to the prediction of the performance achieved by the optimization algorithm. In this study, we investigate the expressiveness of problem landscape features utilized by different supervised ML models in automated algorithm performance prediction. The experimental results point out that the selection of the supervised ML method is crucial, since different supervised ML regression models utilize the problem landscape features differently and there is no common pattern with regard to which landscape features are the most informative.
Explainable Landscape-Aware Optimization Performance Prediction
Oct 22, 2021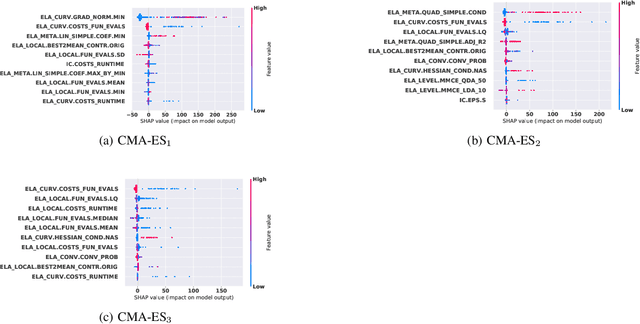
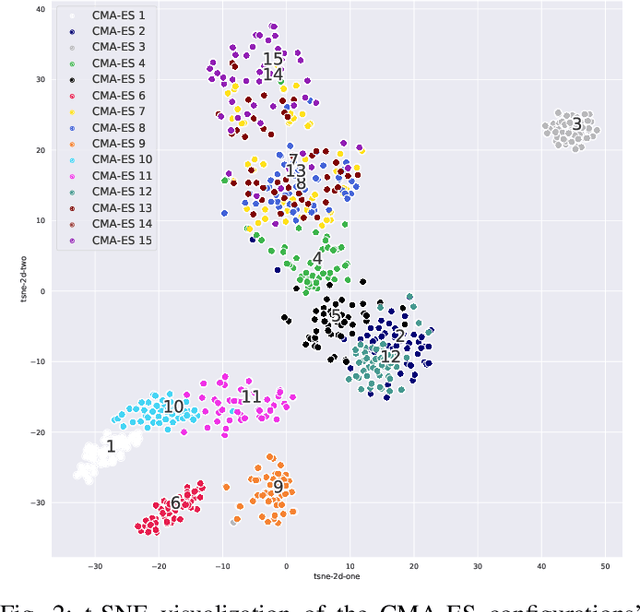
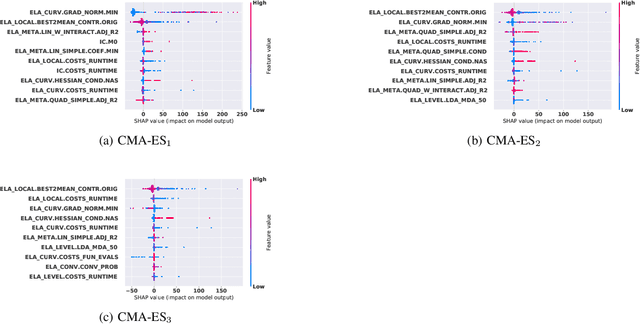

Efficient solving of an unseen optimization problem is related to appropriate selection of an optimization algorithm and its hyper-parameters. For this purpose, automated algorithm performance prediction should be performed that in most commonly-applied practices involves training a supervised ML algorithm using a set of problem landscape features. However, the main issue of training such models is their limited explainability since they only provide information about the joint impact of the set of landscape features to the end prediction results. In this study, we are investigating explainable landscape-aware regression models where the contribution of each landscape feature to the prediction of the optimization algorithm performance is estimated on a global and local level. The global level provides information about the impact of the feature across all benchmark problems' instances, while the local level provides information about the impact on a specific problem instance. The experimental results are obtained using the COCO benchmark problems and three differently configured modular CMA-ESs. The results show a proof of concept that different set of features are important for different problem instances, which indicates that further personalization of the landscape space is required when training an automated algorithm performance prediction model.
A Complementarity Analysis of the COCO Benchmark Problems and Artificially Generated Problems
Apr 27, 2021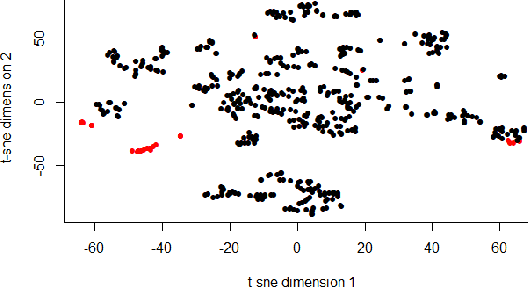
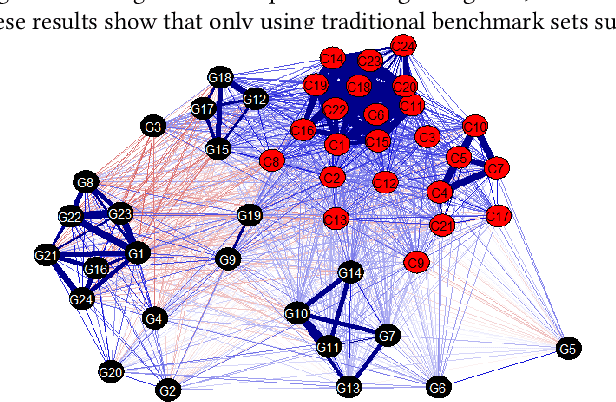
When designing a benchmark problem set, it is important to create a set of benchmark problems that are a good generalization of the set of all possible problems. One possible way of easing this difficult task is by using artificially generated problems. In this paper, one such single-objective continuous problem generation approach is analyzed and compared with the COCO benchmark problem set, a well know problem set for benchmarking numerical optimization algorithms. Using Exploratory Landscape Analysis and Singular Value Decomposition, we show that such representations allow us to further explore the relations between the problems by applying visualization and correlation analysis techniques, with the goal of decreasing the bias in benchmark problem assessment.