 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Switching Algorithms Helps: A Theoretical Study of Online Algorithm Selection
Apr 08, 2026Online algorithm selection (OAS) aims to adapt the optimization process to changes in the fitness landscape and is expected to outperform any single algorithm from a given portfolio. Although this expectation is supported by numerous empirical studies, there are currently no theoretical results proving that OAS can yield asymptotic speedups (apart from some artificial examples for hyper-heuristics). Moreover, theory-based guidelines for when and how to switch between algorithms are largely missing. In this paper, we present the first theoretical example in which switching between two algorithms -- the $(1+λ)$ EA and the $(1+(λ,λ))$ GA -- solves the OneMax problem asymptotically faster than either algorithm used in isolation. We show that an appropriate choice of population sizes for the two algorithms allows the optimum to be reached in $O(n\log\log n)$ expected time, faster than the $Θ(n\sqrt{\frac{\log n \log\log\log n}{\log\log n}})$ runtime of the best of these two algorithms with optimally tuned parameters. We first establish this bound under an idealized switching rule that changes from the $(1+λ)$ to the $(1+(λ,λ))$ GA at the optimal time. We then propose a realistic switching strategy that achieves the same performance. Our analysis combines fixed-start and fixed-target perspectives, illustrating how different algorithms dominate at different stages of the optimization process. This approach offers a promising path toward a deeper theoretical understanding of OAS.
Finding Low Star Discrepancy 3D Kronecker Point Sets Using Algorithm Configuration Techniques
Apr 01, 2026The L infinity star discrepancy is a measure for how uniformly a point set is distributed in a given space. Point sets of low star discrepancy are used as designs of experiments, as initial designs for Bayesian optimization algorithms, for quasi-Monte Carlo integration methods, and many other applications. Recent work has shown that classical constructions such as Sobol', Halton, or Hammersley sequences can be outperformed by large margins when considering point sets of fixed sizes rather than their convergence behavior. These results, highly relevant to the aforementioned applications, raise the question of how much existing constructions can be improved through size-specific optimization. In this work, we study this question for the so-called Kronecker construction. Focusing on the 3-dimensional setting, we show that optimizing the two configurable parameters of its construction yields point sets outperforming the state-of-the-art value for sets of at least 500 points. Using the algorithm configuration technique irace, we then derive parameters that yield new state-of-the-art discrepancy values for whole ranges of set sizes.
How Sequential Algorithm Portfolios can benefit Black Box Optimization
Jan 23, 2026In typical black-box optimization applications, the available computational budget is often allocated to a single algorithm, typically chosen based on user preference with limited knowledge about the problem at hand or according to some expert knowledge. However, we show that splitting the budget across several algorithms yield significantly better results. This approach benefits from both algorithm complementarity across diverse problems and variance reduction within individual functions, and shows that algorithm portfolios do NOT require parallel evaluation capabilities. To demonstrate the advantage of sequential algorithm portfolios, we apply it to the COCO data archive, using over 200 algorithms evaluated on the BBOB test suite. The proposed sequential portfolios consistently outperform single-algorithm baselines, achieving relative performance gains of over 14%, and offering new insights into restart mechanisms and potential for warm-started execution strategies.
MECHBench: A Set of Black-Box Optimization Benchmarks originated from Structural Mechanics
Nov 13, 2025Benchmarking is essential for developing and evaluating black-box optimization algorithms, providing a structured means to analyze their search behavior. Its effectiveness relies on carefully selected problem sets used for evaluation. To date, most established benchmark suites for black-box optimization consist of abstract or synthetic problems that only partially capture the complexities of real-world engineering applications, thereby severely limiting the insights that can be gained for application-oriented optimization scenarios and reducing their practical impact. To close this gap, we propose a new benchmarking suite that addresses it by presenting a curated set of optimization benchmarks rooted in structural mechanics. The current implemented benchmarks are derived from vehicle crashworthiness scenarios, which inherently require the use of gradient-free algorithms due to the non-smooth, highly non-linear nature of the underlying models. Within this paper, the reader will find descriptions of the physical context of each case, the corresponding optimization problem formulations, and clear guidelines on how to employ the suite.
carps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025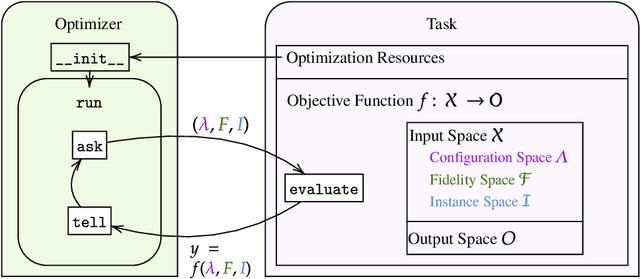

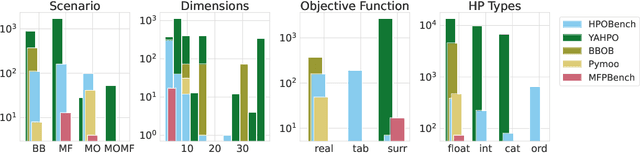
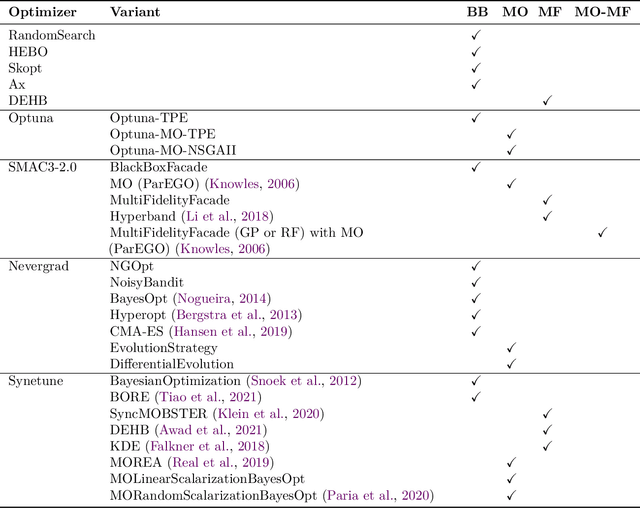
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
Multi-parameter Control for the (1+($λ$,$λ$))-GA on OneMax via Deep Reinforcement Learning
May 19, 2025It is well known that evolutionary algorithms can benefit from dynamic choices of the key parameters that control their behavior, to adjust their search strategy to the different stages of the optimization process. A prominent example where dynamic parameter choices have shown a provable super-constant speed-up is the $(1+(\lambda,\lambda))$ Genetic Algorithm optimizing the OneMax function. While optimal parameter control policies result in linear expected running times, this is not possible with static parameter choices. This result has spurred a lot of interest in parameter control policies. However, many works, in particular theoretical running time analyses, focus on controlling one single parameter. Deriving policies for controlling multiple parameters remains very challenging. In this work we reconsider the problem of the $(1+(\lambda,\lambda))$ Genetic Algorithm optimizing OneMax. We decouple its four main parameters and investigate how well state-of-the-art deep reinforcement learning techniques can approximate good control policies. We show that although making deep reinforcement learning learn effectively is a challenging task, once it works, it is very powerful and is able to find policies that outperform all previously known control policies on the same benchmark. Based on the results found through reinforcement learning, we derive a simple control policy that consistently outperforms the default theory-recommended setting by $27\%$ and the irace-tuned policy, the strongest existing control policy on this benchmark, by $13\%$, for all tested problem sizes up to $40{,}000$.
On the Importance of Reward Design in Reinforcement Learning-based Dynamic Algorithm Configuration: A Case Study on OneMax with (1+($λ$,$λ$))-GA
Feb 27, 2025Dynamic Algorithm Configuration (DAC) has garnered significant attention in recent years, particularly in the prevalence of machine learning and deep learning algorithms. Numerous studies have leveraged the robustness of decision-making in Reinforcement Learning (RL) to address the optimization challenges associated with algorithm configuration. However, making an RL agent work properly is a non-trivial task, especially in reward design, which necessitates a substantial amount of handcrafted knowledge based on domain expertise. In this work, we study the importance of reward design in the context of DAC via a case study on controlling the population size of the $(1+(\lambda,\lambda))$-GA optimizing OneMax. We observed that a poorly designed reward can hinder the RL agent's ability to learn an optimal policy because of a lack of exploration, leading to both scalability and learning divergence issues. To address those challenges, we propose the application of a reward shaping mechanism to facilitate enhanced exploration of the environment by the RL agent. Our work not only demonstrates the ability of RL in dynamically configuring the $(1+(\lambda,\lambda))$-GA, but also confirms the advantages of reward shaping in the scalability of RL agents across various sizes of OneMax problems.
Cascading CMA-ES Instances for Generating Input-diverse Solution Batches
Feb 19, 2025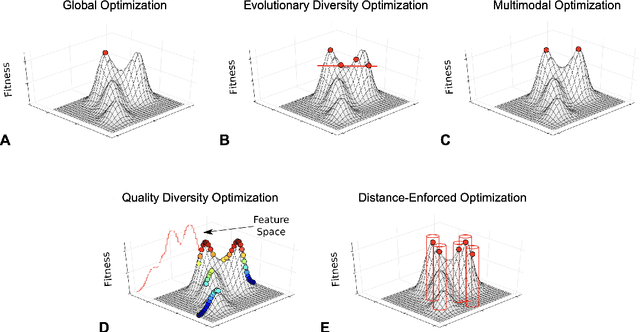
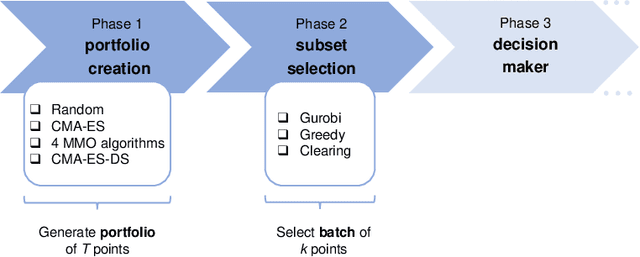
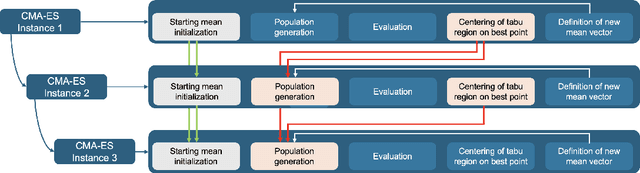
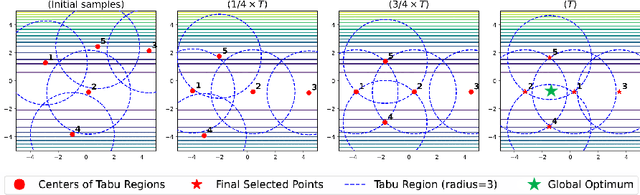
Rather than obtaining a single good solution for a given optimization problem, users often seek alternative design choices, because the best-found solution may perform poorly with respect to additional objectives or constraints that are difficult to capture into the modeling process. Aiming for batches of diverse solutions of high quality is often desirable, as it provides flexibility to accommodate post-hoc user preferences. At the same time, it is crucial that the quality of the best solution found is not compromised. One particular problem setting balancing high quality and diversity is fixing the required minimum distance between solutions while simultaneously obtaining the best possible fitness. Recent work by Santoni et al. [arXiv 2024] revealed that this setting is not well addressed by state-of-the-art algorithms, performing in par or worse than pure random sampling. Driven by this important limitation, we propose a new approach, where parallel runs of the covariance matrix adaptation evolution strategy (CMA-ES) inherit tabu regions in a cascading fashion. We empirically demonstrate that our CMA-ES-Diversity Search (CMA-ES-DS) algorithm generates trajectories that allow to extract high-quality solution batches that respect a given minimum distance requirement, clearly outperforming those obtained from off-the-shelf random sampling, multi-modal optimization algorithms, and standard CMA-ES.
MO-IOHinspector: Anytime Benchmarking of Multi-Objective Algorithms using IOHprofiler
Dec 10, 2024



Benchmarking is one of the key ways in which we can gain insight into the strengths and weaknesses of optimization algorithms. In sampling-based optimization, considering the anytime behavior of an algorithm can provide valuable insights for further developments. In the context of multi-objective optimization, this anytime perspective is not as widely adopted as in the single-objective context. In this paper, we propose a new software tool which uses principles from unbounded archiving as a logging structure. This leads to a clearer separation between experimental design and subsequent analysis decisions. We integrate this approach as a new Python module into the IOHprofiler framework and demonstrate the benefits of this approach by showcasing the ability to change indicators, aggregations, and ranking procedures during the analysis pipeline.
Illuminating the Diversity-Fitness Trade-Off in Black-Box Optimization
Aug 29, 2024



In real-world applications, users often favor structurally diverse design choices over one high-quality solution. It is hence important to consider more solutions that decision-makers can compare and further explore based on additional criteria. Alongside the existing approaches of evolutionary diversity optimization, quality diversity, and multimodal optimization, this paper presents a fresh perspective on this challenge by considering the problem of identifying a fixed number of solutions with a pairwise distance above a specified threshold while maximizing their average quality. We obtain first insight into these objectives by performing a subset selection on the search trajectories of different well-established search heuristics, whether specifically designed with diversity in mind or not. We emphasize that the main goal of our work is not to present a new algorithm but to look at the problem in a more fundamental and theoretically tractable way by asking the question: What trade-off exists between the minimum distance within batches of solutions and the average quality of their fitness? These insights also provide us with a way of making general claims concerning the properties of optimization problems that shall be useful in turn for benchmarking algorithms of the approaches enumerated above. A possibly surprising outcome of our empirical study is the observation that naive uniform random sampling establishes a very strong baseline for our problem, hardly ever outperformed by the search trajectories of the considered heuristics. We interpret these results as a motivation to develop algorithms tailored to produce diverse solutions of high average quality.