 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecarps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025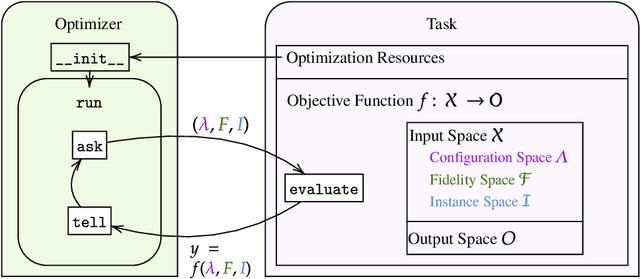

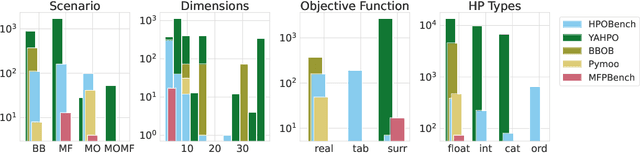
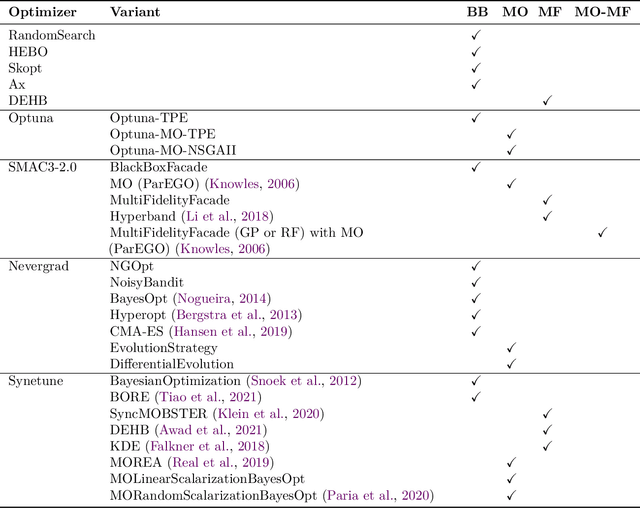
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
Frozen Layers: Memory-efficient Many-fidelity Hyperparameter Optimization
Apr 14, 2025As model sizes grow, finding efficient and cost-effective hyperparameter optimization (HPO) methods becomes increasingly crucial for deep learning pipelines. While multi-fidelity HPO (MF-HPO) trades off computational resources required for DL training with lower fidelity estimations, existing fidelity sources often fail under lower compute and memory constraints. We propose a novel fidelity source: the number of layers that are trained or frozen during training. For deep networks, this approach offers significant compute and memory savings while preserving rank correlations between hyperparameters at low fidelities compared to full model training. We demonstrate this in our empirical evaluation across ResNets and Transformers and additionally analyze the utility of frozen layers as a fidelity in using GPU resources as a fidelity in HPO, and for a combined MF-HPO with other fidelity sources. This contribution opens new applications for MF-HPO with hardware resources as a fidelity and creates opportunities for improved algorithms navigating joint fidelity spaces.
Warmstarting for Scaling Language Models
Nov 11, 2024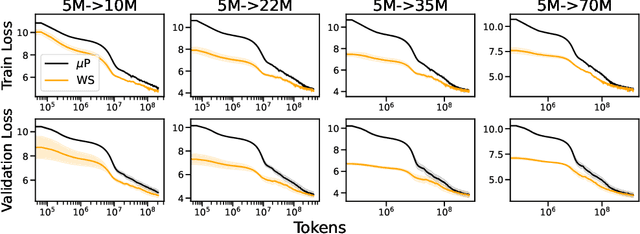
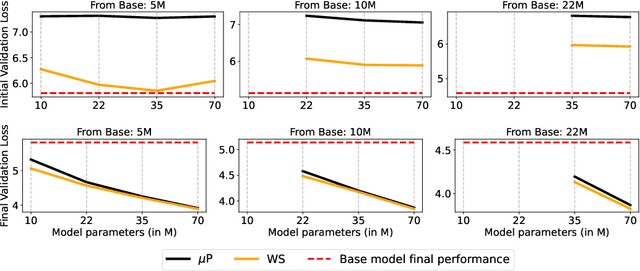
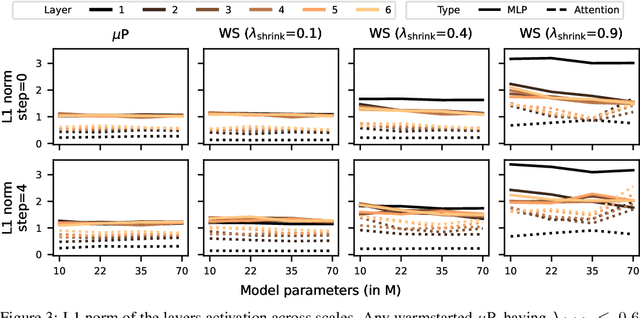
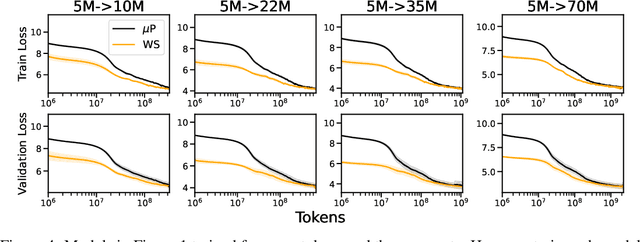
Scaling model sizes to scale performance has worked remarkably well for the current large language models paradigm. The research and empirical findings of various scaling studies led to novel scaling results and laws that guides subsequent research. High training costs for contemporary scales of data and models result in a lack of thorough understanding of how to tune and arrive at such training setups. One direction to ameliorate the cost of pretraining large models is to warmstart the large-scale training from smaller models that are cheaper to tune. In this work, we attempt to understand if the behavior of optimal hyperparameters can be retained under warmstarting for scaling. We explore simple operations that allow the application of theoretically motivated methods of zero-shot transfer of optimal hyperparameters using {\mu}Transfer. We investigate the aspects that contribute to the speedup in convergence and the preservation of stable training dynamics under warmstarting with {\mu}Transfer. We find that shrinking smaller model weights, zero-padding, and perturbing the resulting larger model with scaled initialization from {\mu}P enables effective warmstarting of $\mut{}$.
LMEMs for post-hoc analysis of HPO Benchmarking
Aug 05, 2024The importance of tuning hyperparameters in Machine Learning (ML) and Deep Learning (DL) is established through empirical research and applications, evident from the increase in new hyperparameter optimization (HPO) algorithms and benchmarks steadily added by the community. However, current benchmarking practices using averaged performance across many datasets may obscure key differences between HPO methods, especially for pairwise comparisons. In this work, we apply Linear Mixed-Effect Models-based (LMEMs) significance testing for post-hoc analysis of HPO benchmarking runs. LMEMs allow flexible and expressive modeling on the entire experiment data, including information such as benchmark meta-features, offering deeper insights than current analysis practices. We demonstrate this through a case study on the PriorBand paper's experiment data to find insights not reported in the original work.
In-Context Freeze-Thaw Bayesian Optimization for Hyperparameter Optimization
Apr 25, 2024



With the increasing computational costs associated with deep learning, automated hyperparameter optimization methods, strongly relying on black-box Bayesian optimization (BO), face limitations. Freeze-thaw BO offers a promising grey-box alternative, strategically allocating scarce resources incrementally to different configurations. However, the frequent surrogate model updates inherent to this approach pose challenges for existing methods, requiring retraining or fine-tuning their neural network surrogates online, introducing overhead, instability, and hyper-hyperparameters. In this work, we propose FT-PFN, a novel surrogate for Freeze-thaw style BO. FT-PFN is a prior-data fitted network (PFN) that leverages the transformers' in-context learning ability to efficiently and reliably do Bayesian learning curve extrapolation in a single forward pass. Our empirical analysis across three benchmark suites shows that the predictions made by FT-PFN are more accurate and 10-100 times faster than those of the deep Gaussian process and deep ensemble surrogates used in previous work. Furthermore, we show that, when combined with our novel acquisition mechanism (MFPI-random), the resulting in-context freeze-thaw BO method (ifBO), yields new state-of-the-art performance in the same three families of deep learning HPO benchmarks considered in prior work.
Fast Benchmarking of Asynchronous Multi-Fidelity Optimization on Zero-Cost Benchmarks
Mar 04, 2024While deep learning has celebrated many successes, its results often hinge on the meticulous selection of hyperparameters (HPs). However, the time-consuming nature of deep learning training makes HP optimization (HPO) a costly endeavor, slowing down the development of efficient HPO tools. While zero-cost benchmarks, which provide performance and runtime without actual training, offer a solution for non-parallel setups, they fall short in parallel setups as each worker must communicate its queried runtime to return its evaluation in the exact order. This work addresses this challenge by introducing a user-friendly Python package that facilitates efficient parallel HPO with zero-cost benchmarks. Our approach calculates the exact return order based on the information stored in file system, eliminating the need for long waiting times and enabling much faster HPO evaluations. We first verify the correctness of our approach through extensive testing and the experiments with 6 popular HPO libraries show its applicability to diverse libraries and its ability to achieve over 1000x speedup compared to a traditional approach. Our package can be installed via pip install mfhpo-simulator.
PriorBand: Practical Hyperparameter Optimization in the Age of Deep Learning
Jun 21, 2023
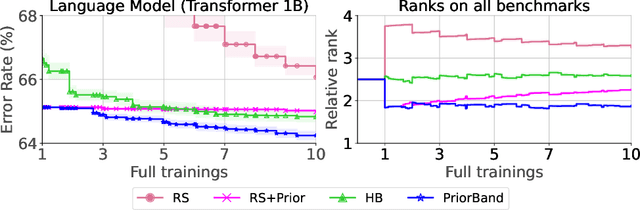


Hyperparameters of Deep Learning (DL) pipelines are crucial for their downstream performance. While a large number of methods for Hyperparameter Optimization (HPO) have been developed, their incurred costs are often untenable for modern DL. Consequently, manual experimentation is still the most prevalent approach to optimize hyperparameters, relying on the researcher's intuition, domain knowledge, and cheap preliminary explorations. To resolve this misalignment between HPO algorithms and DL researchers, we propose PriorBand, an HPO algorithm tailored to DL, able to utilize both expert beliefs and cheap proxy tasks. Empirically, we demonstrate PriorBand's efficiency across a range of DL benchmarks and show its gains under informative expert input and robustness against poor expert beliefs
HPOBench: A Collection of Reproducible Multi-Fidelity Benchmark Problems for HPO
Sep 14, 2021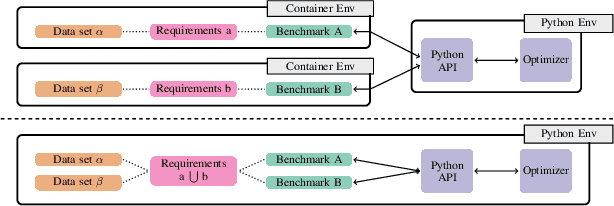
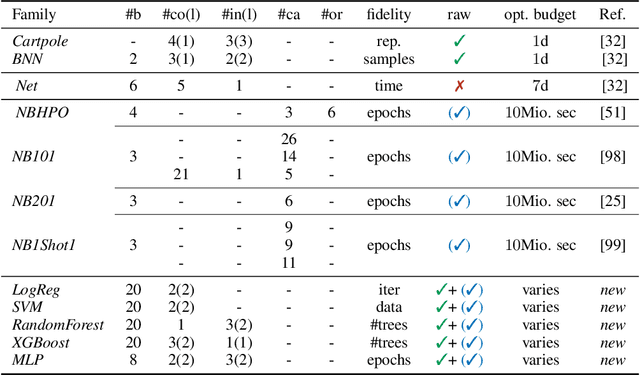

To achieve peak predictive performance, hyperparameter optimization (HPO) is a crucial component of machine learning and its applications. Over the last years,the number of efficient algorithms and tools for HPO grew substantially. At the same time, the community is still lacking realistic, diverse, computationally cheap,and standardized benchmarks. This is especially the case for multi-fidelity HPO methods. To close this gap, we propose HPOBench, which includes 7 existing and 5 new benchmark families, with in total more than 100 multi-fidelity benchmark problems. HPOBench allows to run this extendable set of multi-fidelity HPO benchmarks in a reproducible way by isolating and packaging the individual benchmarks in containers. It also provides surrogate and tabular benchmarks for computationally affordable yet statistically sound evaluations. To demonstrate the broad compatibility of HPOBench and its usefulness, we conduct an exemplary large-scale study evaluating 6 well known multi-fidelity HPO tools.
DEHB: Evolutionary Hyberband for Scalable, Robust and Efficient Hyperparameter Optimization
May 20, 2021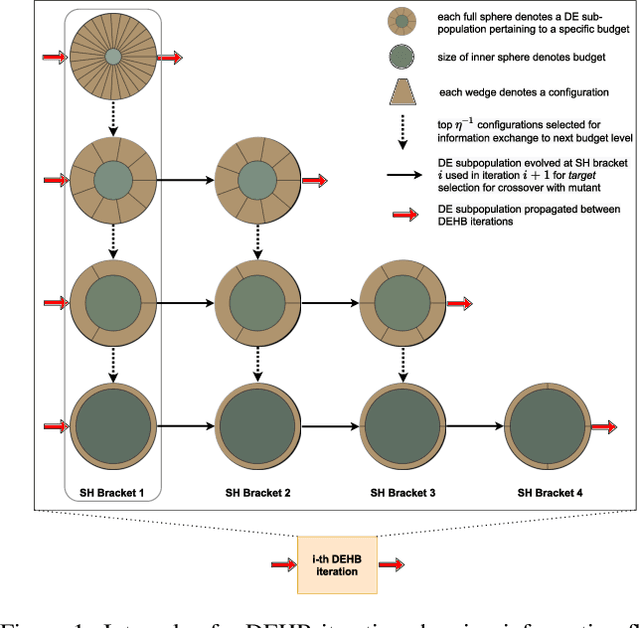
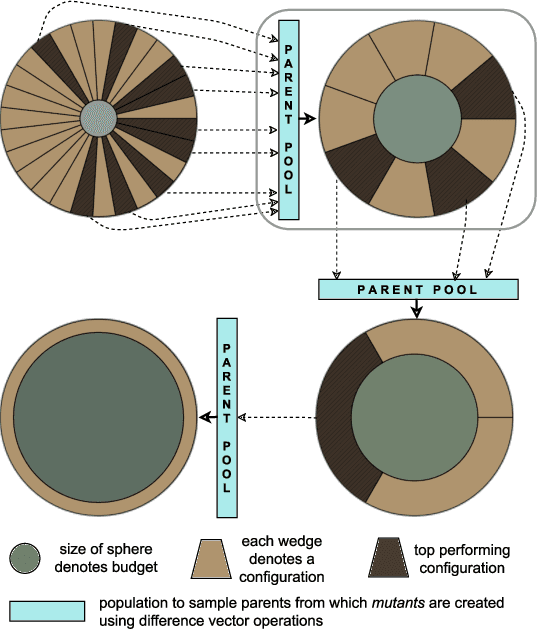


Modern machine learning algorithms crucially rely on several design decisions to achieve strong performance, making the problem of Hyperparameter Optimization (HPO) more important than ever. Here, we combine the advantages of the popular bandit-based HPO method Hyperband (HB) and the evolutionary search approach of Differential Evolution (DE) to yield a new HPO method which we call DEHB. Comprehensive results on a very broad range of HPO problems, as well as a wide range of tabular benchmarks from neural architecture search, demonstrate that DEHB achieves strong performance far more robustly than all previous HPO methods we are aware of, especially for high-dimensional problems with discrete input dimensions. For example, DEHB is up to 1000x faster than random search. It is also efficient in computational time, conceptually simple and easy to implement, positioning it well to become a new default HPO method.
Squirrel: A Switching Hyperparameter Optimizer
Dec 16, 2020In this short note, we describe our submission to the NeurIPS 2020 BBO challenge. Motivated by the fact that different optimizers work well on different problems, our approach switches between different optimizers. Since the team names on the competition's leaderboard were randomly generated "alliteration nicknames", consisting of an adjective and an animal with the same initial letter, we called our approach the Switching Squirrel, or here, short, Squirrel.