 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetraJet-v2: Accurate NVFP4 Training for Large Language Models with Oscillation Suppression and Outlier Control
Oct 31, 2025Large Language Models (LLMs) training is prohibitively expensive, driving interest in low-precision fully-quantized training (FQT). While novel 4-bit formats like NVFP4 offer substantial efficiency gains, achieving near-lossless training at such low precision remains challenging. We introduce TetraJet-v2, an end-to-end 4-bit FQT method that leverages NVFP4 for activations, weights, and gradients in all linear layers. We identify two critical issues hindering low-precision LLM training: weight oscillation and outliers. To address these, we propose: 1) an unbiased double-block quantization method for NVFP4 linear layers, 2) OsciReset, an algorithm to suppress weight oscillation, and 3) OutControl, an algorithm to retain outlier accuracy. TetraJet-v2 consistently outperforms prior FP4 training methods on pre-training LLMs across varying model sizes up to 370M and data sizes up to 200B tokens, reducing the performance gap to full-precision training by an average of 51.3%.
confopt: A Library for Implementation and Evaluation of Gradient-based One-Shot NAS Methods
Jul 22, 2025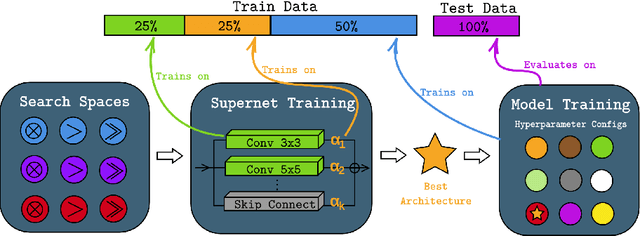
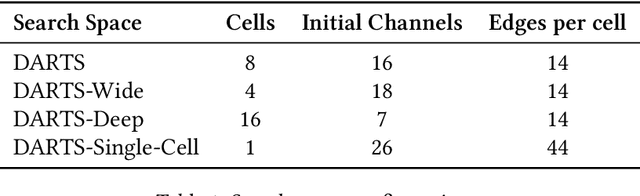
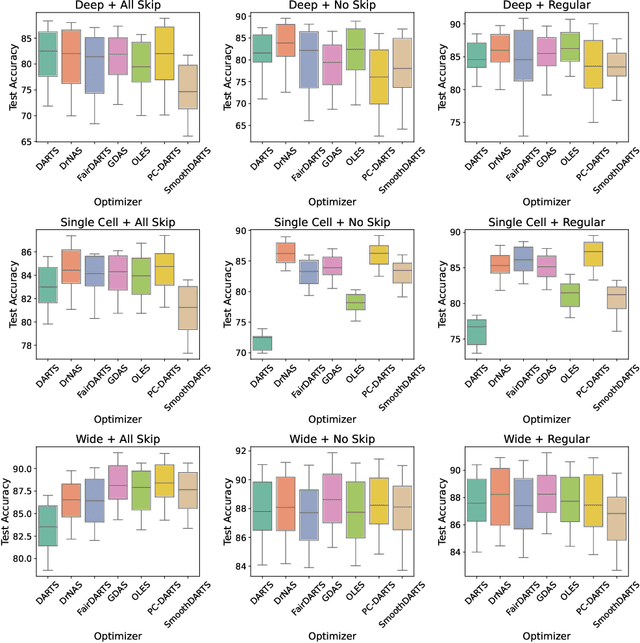
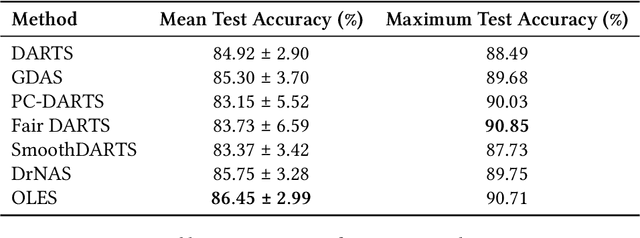
Gradient-based one-shot neural architecture search (NAS) has significantly reduced the cost of exploring architectural spaces with discrete design choices, such as selecting operations within a model. However, the field faces two major challenges. First, evaluations of gradient-based NAS methods heavily rely on the DARTS benchmark, despite the existence of other available benchmarks. This overreliance has led to saturation, with reported improvements often falling within the margin of noise. Second, implementations of gradient-based one-shot NAS methods are fragmented across disparate repositories, complicating fair and reproducible comparisons and further development. In this paper, we introduce Configurable Optimizer (confopt), an extensible library designed to streamline the development and evaluation of gradient-based one-shot NAS methods. Confopt provides a minimal API that makes it easy for users to integrate new search spaces, while also supporting the decomposition of NAS optimizers into their core components. We use this framework to create a suite of new DARTS-based benchmarks, and combine them with a novel evaluation protocol to reveal a critical flaw in how gradient-based one-shot NAS methods are currently assessed. The code can be found at https://github.com/automl/ConfigurableOptimizer.
Frozen Layers: Memory-efficient Many-fidelity Hyperparameter Optimization
Apr 14, 2025As model sizes grow, finding efficient and cost-effective hyperparameter optimization (HPO) methods becomes increasingly crucial for deep learning pipelines. While multi-fidelity HPO (MF-HPO) trades off computational resources required for DL training with lower fidelity estimations, existing fidelity sources often fail under lower compute and memory constraints. We propose a novel fidelity source: the number of layers that are trained or frozen during training. For deep networks, this approach offers significant compute and memory savings while preserving rank correlations between hyperparameters at low fidelities compared to full model training. We demonstrate this in our empirical evaluation across ResNets and Transformers and additionally analyze the utility of frozen layers as a fidelity in using GPU resources as a fidelity in HPO, and for a combined MF-HPO with other fidelity sources. This contribution opens new applications for MF-HPO with hardware resources as a fidelity and creates opportunities for improved algorithms navigating joint fidelity spaces.
Attention Is All You Need For Mixture-of-Depths Routing
Dec 30, 2024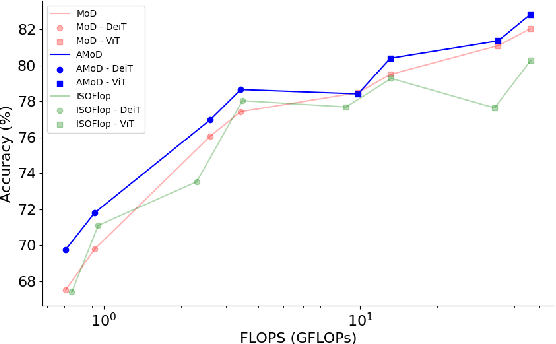
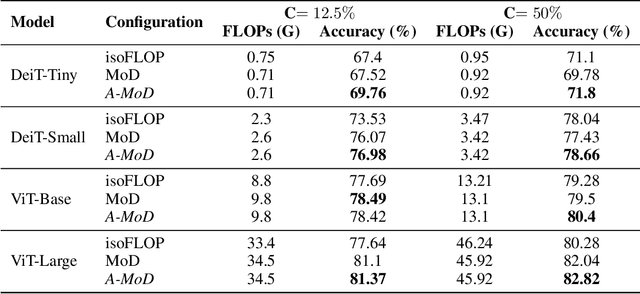
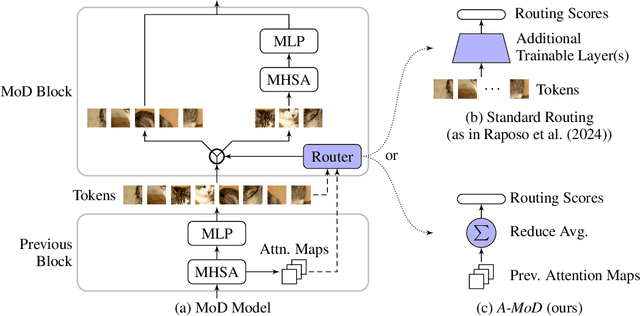
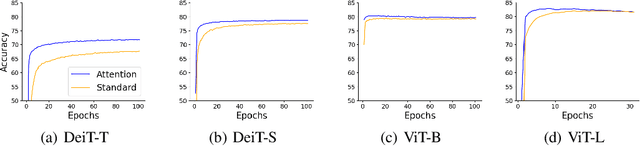
Advancements in deep learning are driven by training models with increasingly larger numbers of parameters, which in turn heightens the computational demands. To address this issue, Mixture-of-Depths (MoD) models have been proposed to dynamically assign computations only to the most relevant parts of the inputs, thereby enabling the deployment of large-parameter models with high efficiency during inference and training. These MoD models utilize a routing mechanism to determine which tokens should be processed by a layer, or skipped. However, conventional MoD models employ additional network layers specifically for the routing which are difficult to train, and add complexity and deployment overhead to the model. In this paper, we introduce a novel attention-based routing mechanism A-MoD that leverages the existing attention map of the preceding layer for routing decisions within the current layer. Compared to standard routing, A-MoD allows for more efficient training as it introduces no additional trainable parameters and can be easily adapted from pretrained transformer models. Furthermore, it can increase the performance of the MoD model. For instance, we observe up to 2% higher accuracy on ImageNet compared to standard routing and isoFLOP ViT baselines. Furthermore, A-MoD improves the MoD training convergence, leading to up to 2x faster transfer learning.
Federated Learning for Computationally-Constrained Heterogeneous Devices: A Survey
Jul 18, 2023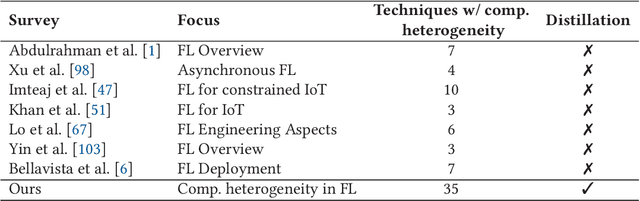
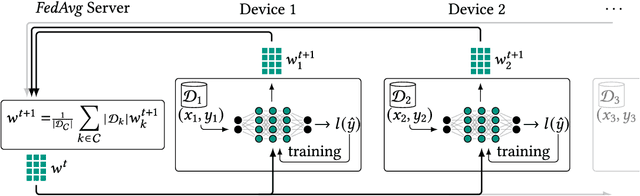
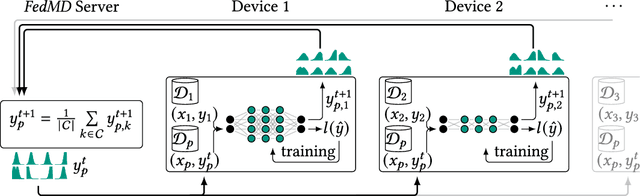

With an increasing number of smart devices like internet of things (IoT) devices deployed in the field, offloadingtraining of neural networks (NNs) to a central server becomes more and more infeasible. Recent efforts toimprove users' privacy have led to on-device learning emerging as an alternative. However, a model trainedonly on a single device, using only local data, is unlikely to reach a high accuracy. Federated learning (FL)has been introduced as a solution, offering a privacy-preserving trade-off between communication overheadand model accuracy by sharing knowledge between devices but disclosing the devices' private data. Theapplicability and the benefit of applying baseline FL are, however, limited in many relevant use cases dueto the heterogeneity present in such environments. In this survey, we outline the heterogeneity challengesFL has to overcome to be widely applicable in real-world applications. We especially focus on the aspect ofcomputation heterogeneity among the participating devices and provide a comprehensive overview of recentworks on heterogeneity-aware FL. We discuss two groups: works that adapt the NN architecture and worksthat approach heterogeneity on a system level, covering Federated Averaging (FedAvg), distillation, and splitlearning-based approaches, as well as synchronous and asynchronous aggregation schemes.
Speed-Oblivious Online Scheduling: Knowing (Precise) Speeds is not Necessary
Feb 02, 2023We consider online scheduling on unrelated (heterogeneous) machines in a speed-oblivious setting, where an algorithm is unaware of the exact job-dependent processing speeds. We show strong impossibility results for clairvoyant and non-clairvoyant algorithms and overcome them in models inspired by practical settings: (i) we provide competitive learning-augmented algorithms, assuming that (possibly erroneous) predictions on the speeds are given, and (ii) we provide competitive algorithms for the speed-ordered model, where a single global order of machines according to their unknown job-dependent speeds is known. We prove strong theoretical guarantees and evaluate our findings on a representative heterogeneous multi-core processor. These seem to be the first empirical results for algorithms with predictions that are performed in a non-synthetic environment on real hardware.
CoCo-FL: Communication- and Computation-Aware Federated Learning via Partial NN Freezing and Quantization
Mar 10, 2022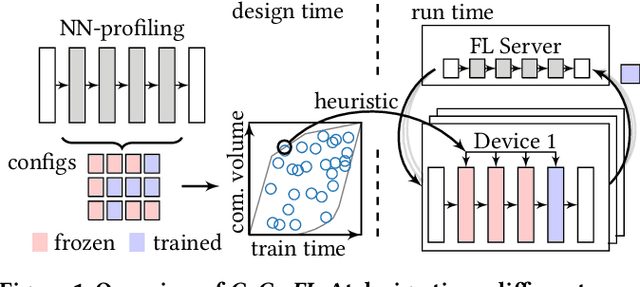
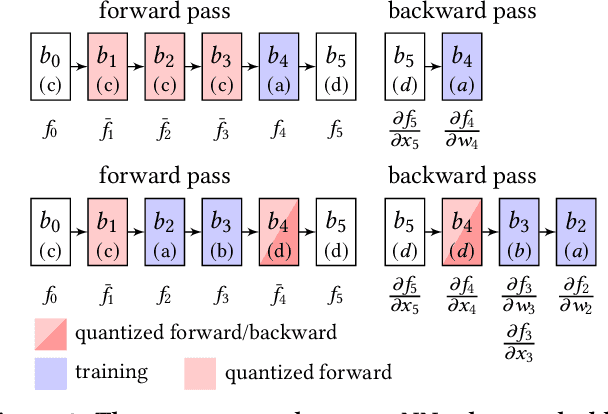
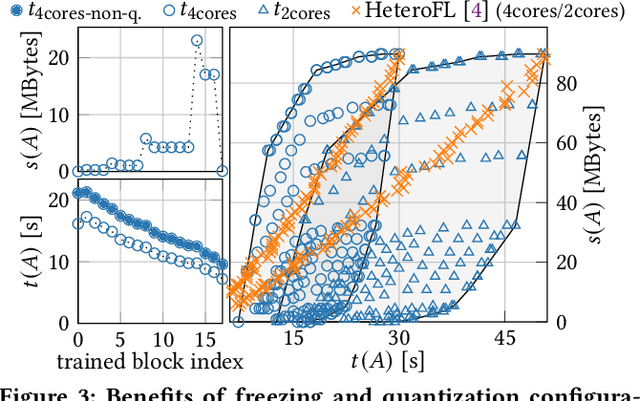
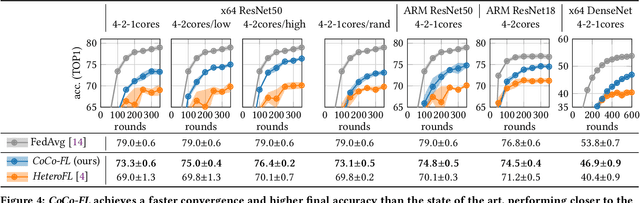
Devices participating in federated learning (FL) typically have heterogeneous communication and computation resources. However, all devices need to finish training by the same deadline dictated by the server when applying synchronous FL, as we consider in this paper. Reducing the complexity of the trained neural network (NN) at constrained devices, i.e., by dropping neurons/filters, is insufficient as it tightly couples reductions in communication and computation requirements, wasting resources. Quantization has proven effective to accelerate inference, but quantized training suffers from accuracy losses. We present a novel mechanism that quantizes during training parts of the NN to reduce the computation requirements, freezes them to reduce the communication and computation requirements, and trains the remaining parts in full precision to maintain a high convergence speed and final accuracy. Using this mechanism, we present the first FL technique that independently optimizes for specific communication and computation constraints in FL: CoCo-FL. We show that CoCo-FL reaches a much higher convergence speed than the state of the art and a significantly higher final accuracy.
DISTREAL: Distributed Resource-Aware Learning in Heterogeneous Systems
Dec 16, 2021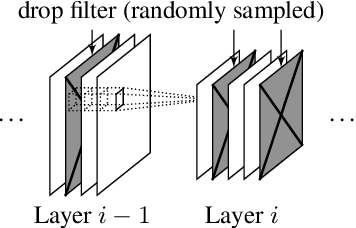
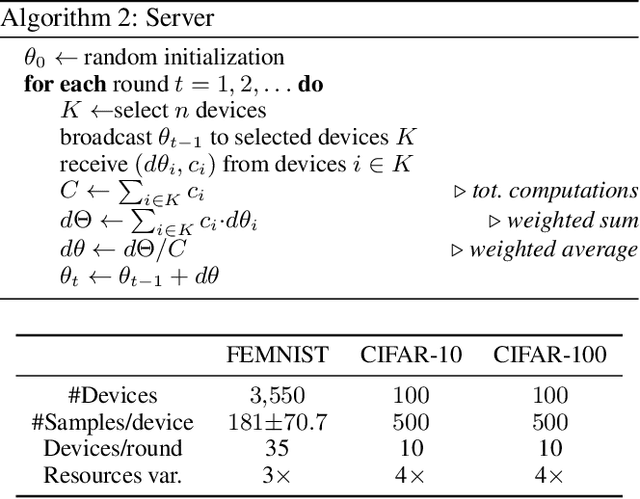
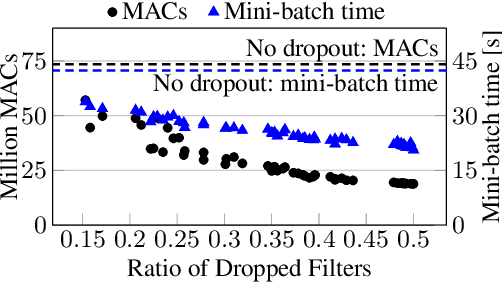

We study the problem of distributed training of neural networks (NNs) on devices with heterogeneous, limited, and time-varying availability of computational resources. We present an adaptive, resource-aware, on-device learning mechanism, DISTREAL, which is able to fully and efficiently utilize the available resources on devices in a distributed manner, increasing the convergence speed. This is achieved with a dropout mechanism that dynamically adjusts the computational complexity of training an NN by randomly dropping filters of convolutional layers of the model. Our main contribution is the introduction of a design space exploration (DSE) technique, which finds Pareto-optimal per-layer dropout vectors with respect to resource requirements and convergence speed of the training. Applying this technique, each device is able to dynamically select the dropout vector that fits its available resource without requiring any assistance from the server. We implement our solution in a federated learning (FL) system, where the availability of computational resources varies both between devices and over time, and show through extensive evaluation that we are able to significantly increase the convergence speed over the state of the art without compromising on the final accuracy.
Distributed Learning on Heterogeneous Resource-Constrained Devices
Jun 09, 2020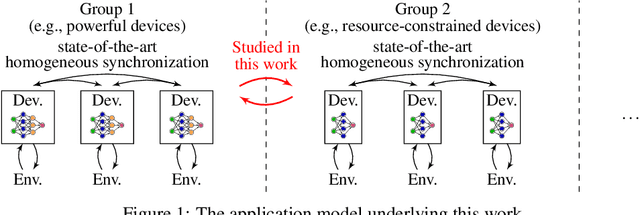
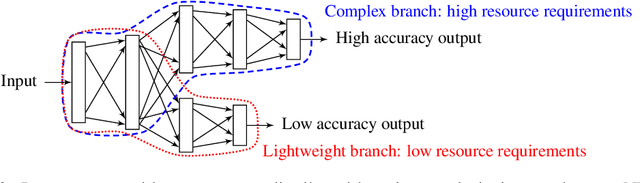
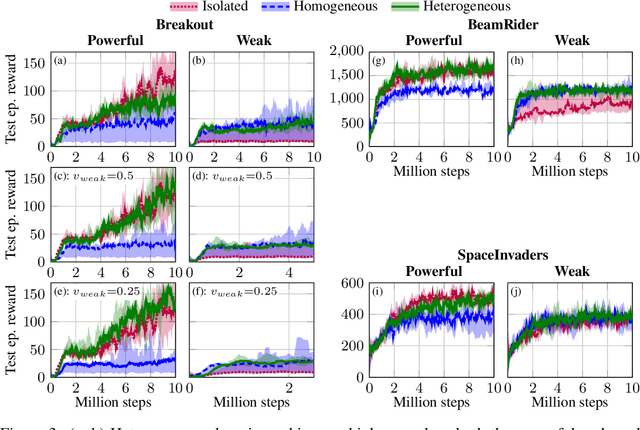
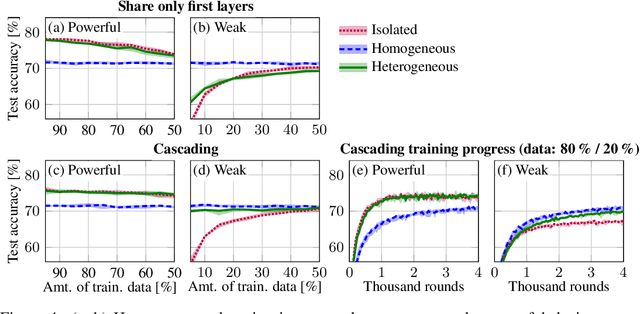
We consider a distributed system, consisting of a heterogeneous set of devices, ranging from low-end to high-end. These devices have different profiles, e.g., different energy budgets, or different hardware specifications, determining their capabilities on performing certain learning tasks. We propose the first approach that enables distributed learning in such a heterogeneous system. Applying our approach, each device employs a neural network (NN) with a topology that fits its capabilities; however, part of these NNs share the same topology, so that their parameters can be jointly learned. This differs from current approaches, such as federated learning, which require all devices to employ the same NN, enforcing a trade-off between achievable accuracy and computational overhead of training. We evaluate heterogeneous distributed learning for reinforcement learning (RL) and observe that it greatly improves the achievable reward on more powerful devices, compared to current approaches, while still maintaining a high reward on the weaker devices. We also explore supervised learning, observing similar gains.