 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCo-FL: Communication- and Computation-Aware Federated Learning via Partial NN Freezing and Quantization
Paper and Code
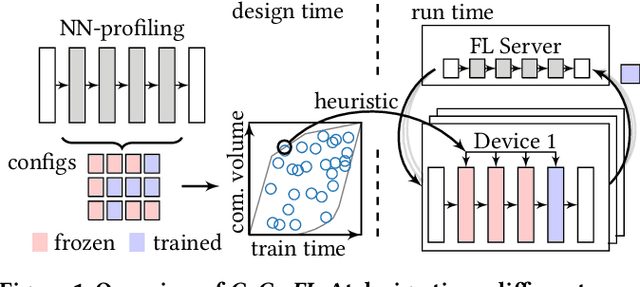
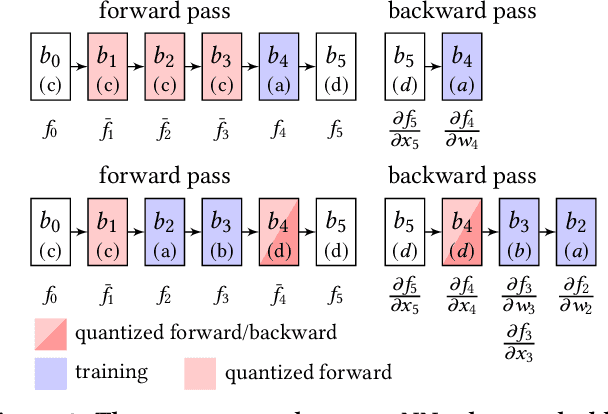
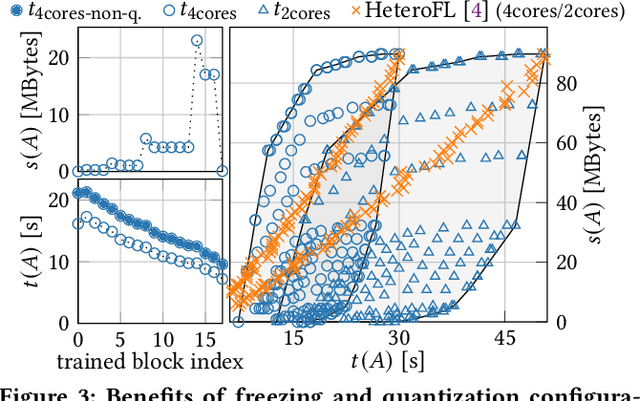
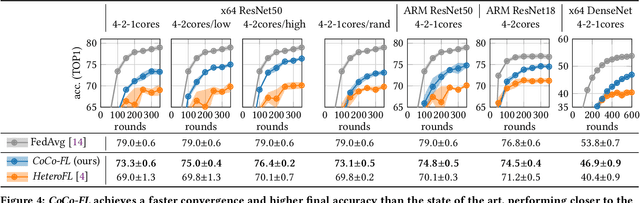
Devices participating in federated learning (FL) typically have heterogeneous communication and computation resources. However, all devices need to finish training by the same deadline dictated by the server when applying synchronous FL, as we consider in this paper. Reducing the complexity of the trained neural network (NN) at constrained devices, i.e., by dropping neurons/filters, is insufficient as it tightly couples reductions in communication and computation requirements, wasting resources. Quantization has proven effective to accelerate inference, but quantized training suffers from accuracy losses. We present a novel mechanism that quantizes during training parts of the NN to reduce the computation requirements, freezes them to reduce the communication and computation requirements, and trains the remaining parts in full precision to maintain a high convergence speed and final accuracy. Using this mechanism, we present the first FL technique that independently optimizes for specific communication and computation constraints in FL: CoCo-FL. We show that CoCo-FL reaches a much higher convergence speed than the state of the art and a significantly higher final accuracy.