 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreening AI Inference with Accuracy and Latency-aware User Incentives
May 26, 2026The widespread use of AI services has raised concerns for its environmental sustainability, towards which recent studies have identified carbon emissions of AI inference as the major contributor. This paper introduces a framework for designing AI inference incentives based on the users' valuation for inference quality and latency, together with their environmental consciousness, while accounting for the tradeoff between carbon emissions and the two QoE parameters. Our approach can accommodate different tradeoffs, that depend on the size and complexity of the AI models and the allocation of resources to serve inference requests. The incentives can be offered through a practical two-tier service subscription that offers users a discount in exchange for reduced carbon emissions. The discounted service option gives the AI provider the flexibility to serve some percentage of inference requests at a lower quality and higher latency during periods of high carbon intensity.
Split Federated Learning Architectures for High-Accuracy and Low-Delay Model Training
Mar 09, 2026Can we find a network architecture for ML model training so as to optimize training loss (and thus, accuracy) in Split Federated Learning (SFL)? And can this architecture also reduce training delay and communication overhead? While accuracy is not influenced by how we split the model in ordinary, state-of-the-art SFL, in this work we answer the questions above in the affirmative. Recent Hierarchical SFL (HSFL) architectures adopt a three-tier training structure consisting of clients, (local) aggregators, and a central server. In this architecture, the model is partitioned at two partitioning layers into three sub-models, which are executed across the three tiers. Despite their merits, HSFL architectures overlook the impact of the partitioning layers and client-to-aggregator assignments on accuracy, delay, and overhead. This work explicitly captures the impact of the partitioning layers and client-to-aggregator assignments on accuracy, delay and overhead by formulating a joint optimization problem. We prove that the problem is NP-hard and propose the first accuracy-aware heuristic algorithm that explicitly accounts for model accuracy, while remaining delay-efficient. Simulation results on public datasets show that our approach can improve accuracy by 3%, while reducing delay by 20% and overhead by 50%, compared to state-of-the-art SFL and HSFL schemes.
Cells on Autopilot: Adaptive Cell (Re)Selection via Reinforcement Learning
Jan 08, 2026The widespread deployment of 5G networks, together with the coexistence of 4G/LTE networks, provides mobile devices a diverse set of candidate cells to connect to. However, associating mobile devices to cells to maximize overall network performance, a.k.a. cell (re)selection, remains a key challenge for mobile operators. Today, cell (re)selection parameters are typically configured manually based on operator experience and rarely adapted to dynamic network conditions. In this work, we ask: Can an agent automatically learn and adapt cell (re)selection parameters to consistently improve network performance? We present a reinforcement learning (RL)-based framework called CellPilot that adaptively tunes cell (re)selection parameters by learning spatiotemporal patterns of mobile network dynamics. Our study with real-world data demonstrates that even a lightweight RL agent can outperform conventional heuristic reconfigurations by up to 167%, while generalizing effectively across different network scenarios. These results indicate that data-driven approaches can significantly improve cell (re)selection configurations and enhance mobile network performance.
Large Language Model Partitioning for Low-Latency Inference at the Edge
May 05, 2025Large Language Models (LLMs) based on autoregressive, decoder-only Transformers generate text one token at a time, where a token represents a discrete unit of text. As each newly produced token is appended to the partial output sequence, the length grows and so does the memory and compute load, due to the expanding key-value caches, which store intermediate representations of all previously generated tokens in the multi-head attention (MHA) layer. As this iterative process steadily increases memory and compute demands, layer-based partitioning in resource-constrained edge environments often results in memory overload or high inference latency. To address this and reduce inference latency, we propose a resource-aware Transformer architecture partitioning algorithm, where the partitioning decision is updated at regular intervals during token generation. The approach is myopic in that it is based on instantaneous information about device resource availability and network link bandwidths. When first executed, the algorithm places blocks on devices, and in later executions, it migrates these blocks among devices so that the sum of migration delay and inference delay remains low. Our approach partitions the decoder at the attention head level, co-locating each attention head with its key-value cache and allowing dynamic migrations whenever resources become tight. By allocating different attention heads to different devices, we exploit parallel execution of attention heads and thus achieve substantial reductions in inference delays. Our experiments show that in small-scale settings (3-5 devices), the proposed method achieves within 15 to 20 percent of an exact optimal solver's latency, while in larger-scale tests it achieves notable improvements in inference speed and memory usage compared to state-of-the-art layer-based partitioning approaches.
Collaborative Split Federated Learning with Parallel Training and Aggregation
Apr 22, 2025Federated learning (FL) operates based on model exchanges between the server and the clients, and it suffers from significant client-side computation and communication burden. Split federated learning (SFL) arises a promising solution by splitting the model into two parts, that are trained sequentially: the clients train the first part of the model (client-side model) and transmit it to the server that trains the second (server-side model). Existing SFL schemes though still exhibit long training delays and significant communication overhead, especially when clients of different computing capability participate. Thus, we propose Collaborative-Split Federated Learning~(C-SFL), a novel scheme that splits the model into three parts, namely the model parts trained at the computationally weak clients, the ones trained at the computationally strong clients, and the ones at the server. Unlike existing works, C-SFL enables parallel training and aggregation of model's parts at the clients and at the server, resulting in reduced training delays and commmunication overhead while improving the model's accuracy. Experiments verify the multiple gains of C-SFL against the existing schemes.
Accelerated Training on Low-Power Edge Devices
Feb 25, 2025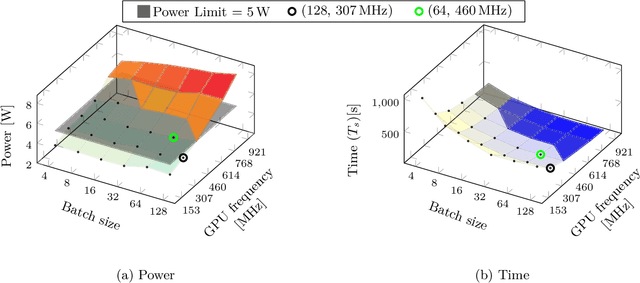
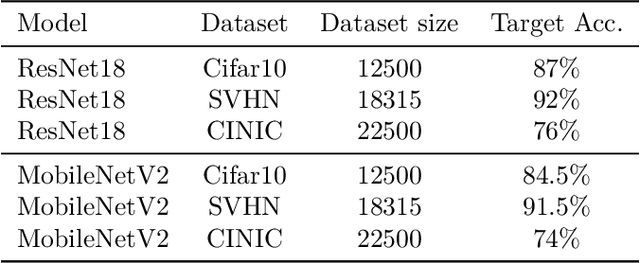
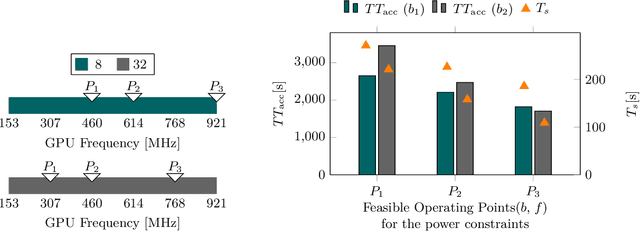
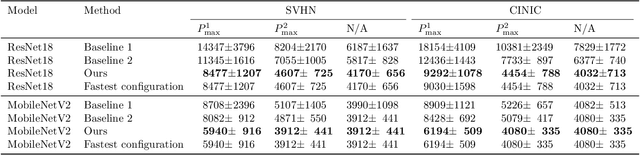
Training on edge devices poses several challenges as these devices are generally resource-constrained, especially in terms of power. State-of-the-art techniques at the device level reduce the GPU frequency to enforce power constraints, leading to a significant increase in training time. To accelerate training, we propose to jointly adjust the system and application parameters (in our case, the GPU frequency and the batch size of the training task) while adhering to the power constraints on devices. We introduce a novel cross-layer methodology that combines predictions of batch size efficiency and device profiling to achieve the desired optimization. Our evaluation on real hardware shows that our method outperforms the current baselines that depend on state of the art techniques, reducing the training time by $2.4\times$ with results very close to optimal. Our measurements also indicate a substantial reduction in the overall energy used for the training process. These gains are achieved without reduction in the performance of the trained model.
Efficient Federated Finetuning of Tiny Transformers with Resource-Constrained Devices
Nov 12, 2024



In recent years, Large Language Models (LLMs) through Transformer structures have dominated many machine learning tasks, especially text processing. However, these models require massive amounts of data for training and induce high resource requirements, particularly in terms of the large number of Floating Point Operations (FLOPs) and the high amounts of memory needed. To fine-tune such a model in a parameter-efficient way, techniques like Adapter or LoRA have been developed. However, we observe that the application of LoRA, when used in federated learning (FL), while still being parameter-efficient, is memory and FLOP inefficient. Based on that observation, we develop a novel layer finetuning scheme that allows devices in cross-device FL to make use of pretrained neural networks (NNs) while adhering to given resource constraints. We show that our presented scheme outperforms the current state of the art when dealing with homogeneous or heterogeneous computation and memory constraints and is on par with LoRA regarding limited communication, thereby achieving significantly higher accuracies in FL training.
Multi-Objective Optimization Using Adaptive Distributed Reinforcement Learning
Mar 13, 2024



The Intelligent Transportation System (ITS) environment is known to be dynamic and distributed, where participants (vehicle users, operators, etc.) have multiple, changing and possibly conflicting objectives. Although Reinforcement Learning (RL) algorithms are commonly applied to optimize ITS applications such as resource management and offloading, most RL algorithms focus on single objectives. In many situations, converting a multi-objective problem into a single-objective one is impossible, intractable or insufficient, making such RL algorithms inapplicable. We propose a multi-objective, multi-agent reinforcement learning (MARL) algorithm with high learning efficiency and low computational requirements, which automatically triggers adaptive few-shot learning in a dynamic, distributed and noisy environment with sparse and delayed reward. We test our algorithm in an ITS environment with edge cloud computing. Empirical results show that the algorithm is quick to adapt to new environments and performs better in all individual and system metrics compared to the state-of-the-art benchmark. Our algorithm also addresses various practical concerns with its modularized and asynchronous online training method. In addition to the cloud simulation, we test our algorithm on a single-board computer and show that it can make inference in 6 milliseconds.
DISTINQT: A Distributed Privacy Aware Learning Framework for QoS Prediction for Future Mobile and Wireless Networks
Jan 15, 2024



Beyond 5G and 6G networks are expected to support new and challenging use cases and applications that depend on a certain level of Quality of Service (QoS) to operate smoothly. Predicting the QoS in a timely manner is of high importance, especially for safety-critical applications as in the case of vehicular communications. Although until recent years the QoS prediction has been carried out by centralized Artificial Intelligence (AI) solutions, a number of privacy, computational, and operational concerns have emerged. Alternative solutions have been surfaced (e.g. Split Learning, Federated Learning), distributing AI tasks of reduced complexity across nodes, while preserving the privacy of the data. However, new challenges rise when it comes to scalable distributed learning approaches, taking into account the heterogeneous nature of future wireless networks. The current work proposes DISTINQT, a privacy-aware distributed learning framework for QoS prediction. Our framework supports multiple heterogeneous nodes, in terms of data types and model architectures, by sharing computations across them. This, enables the incorporation of diverse knowledge into a sole learning process that will enhance the robustness and generalization capabilities of the final QoS prediction model. DISTINQT also contributes to data privacy preservation by encoding any raw input data into a non-linear latent representation before any transmission. Evaluation results showcase that our framework achieves a statistically identical performance compared to its centralized version and an average performance improvement of up to 65% against six state-of-the-art centralized baseline solutions in the Tele-Operated Driving use case.
A Safe Deep Reinforcement Learning Approach for Energy Efficient Federated Learning in Wireless Communication Networks
Aug 21, 2023Progressing towards a new era of Artificial Intelligence (AI) - enabled wireless networks, concerns regarding the environmental impact of AI have been raised both in industry and academia. Federated Learning (FL) has emerged as a key privacy preserving decentralized AI technique. Despite efforts currently being made in FL, its environmental impact is still an open problem. Targeting the minimization of the overall energy consumption of an FL process, we propose the orchestration of computational and communication resources of the involved devices to minimize the total energy required, while guaranteeing a certain performance of the model. To this end, we propose a Soft Actor Critic Deep Reinforcement Learning (DRL) solution, where a penalty function is introduced during training, penalizing the strategies that violate the constraints of the environment, and ensuring a safe RL process. A device level synchronization method, along with a computationally cost effective FL environment are proposed, with the goal of further reducing the energy consumption and communication overhead. Evaluation results show the effectiveness of the proposed scheme compared to four state-of-the-art baseline solutions in both static and dynamic environments, achieving a decrease of up to 94% in the total energy consumption.