 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Partitioning for Low-Latency Inference at the Edge
May 05, 2025Large Language Models (LLMs) based on autoregressive, decoder-only Transformers generate text one token at a time, where a token represents a discrete unit of text. As each newly produced token is appended to the partial output sequence, the length grows and so does the memory and compute load, due to the expanding key-value caches, which store intermediate representations of all previously generated tokens in the multi-head attention (MHA) layer. As this iterative process steadily increases memory and compute demands, layer-based partitioning in resource-constrained edge environments often results in memory overload or high inference latency. To address this and reduce inference latency, we propose a resource-aware Transformer architecture partitioning algorithm, where the partitioning decision is updated at regular intervals during token generation. The approach is myopic in that it is based on instantaneous information about device resource availability and network link bandwidths. When first executed, the algorithm places blocks on devices, and in later executions, it migrates these blocks among devices so that the sum of migration delay and inference delay remains low. Our approach partitions the decoder at the attention head level, co-locating each attention head with its key-value cache and allowing dynamic migrations whenever resources become tight. By allocating different attention heads to different devices, we exploit parallel execution of attention heads and thus achieve substantial reductions in inference delays. Our experiments show that in small-scale settings (3-5 devices), the proposed method achieves within 15 to 20 percent of an exact optimal solver's latency, while in larger-scale tests it achieves notable improvements in inference speed and memory usage compared to state-of-the-art layer-based partitioning approaches.
Collaborative Split Federated Learning with Parallel Training and Aggregation
Apr 22, 2025Federated learning (FL) operates based on model exchanges between the server and the clients, and it suffers from significant client-side computation and communication burden. Split federated learning (SFL) arises a promising solution by splitting the model into two parts, that are trained sequentially: the clients train the first part of the model (client-side model) and transmit it to the server that trains the second (server-side model). Existing SFL schemes though still exhibit long training delays and significant communication overhead, especially when clients of different computing capability participate. Thus, we propose Collaborative-Split Federated Learning~(C-SFL), a novel scheme that splits the model into three parts, namely the model parts trained at the computationally weak clients, the ones trained at the computationally strong clients, and the ones at the server. Unlike existing works, C-SFL enables parallel training and aggregation of model's parts at the clients and at the server, resulting in reduced training delays and commmunication overhead while improving the model's accuracy. Experiments verify the multiple gains of C-SFL against the existing schemes.
Explainability and Continual Learning meet Federated Learning at the Network Edge
Apr 11, 2025As edge devices become more capable and pervasive in wireless networks, there is growing interest in leveraging their collective compute power for distributed learning. However, optimizing learning at the network edge entails unique challenges, particularly when moving beyond conventional settings and objectives. While Federated Learning (FL) has emerged as a key paradigm for distributed model training, critical challenges persist. First, existing approaches often overlook the trade-off between predictive accuracy and interpretability. Second, they struggle to integrate inherently explainable models such as decision trees because their non-differentiable structure makes them not amenable to backpropagation-based training algorithms. Lastly, they lack meaningful mechanisms for continual Machine Learning (ML) model adaptation through Continual Learning (CL) in resource-limited environments. In this paper, we pave the way for a set of novel optimization problems that emerge in distributed learning at the network edge with wirelessly interconnected edge devices, and we identify key challenges and future directions. Specifically, we discuss how Multi-objective optimization (MOO) can be used to address the trade-off between predictive accuracy and explainability when using complex predictive models. Next, we discuss the implications of integrating inherently explainable tree-based models into distributed learning settings. Finally, we investigate how CL strategies can be effectively combined with FL to support adaptive, lifelong learning when limited-size buffers are used to store past data for retraining. Our approach offers a cohesive set of tools for designing privacy-preserving, adaptive, and trustworthy ML solutions tailored to the demands of edge computing and intelligent services.
Joint Explainability-Performance Optimization With Surrogate Models for AI-Driven Edge Services
Mar 10, 2025Explainable AI is a crucial component for edge services, as it ensures reliable decision making based on complex AI models. Surrogate models are a prominent approach of XAI where human-interpretable models, such as a linear regression model, are trained to approximate a complex (black-box) model's predictions. This paper delves into the balance between the predictive accuracy of complex AI models and their approximation by surrogate ones, advocating that both these models benefit from being learned simultaneously. We derive a joint (bi-level) training scheme for both models and we introduce a new algorithm based on multi-objective optimization (MOO) to simultaneously minimize both the complex model's prediction error and the error between its outputs and those of the surrogate. Our approach leads to improvements that exceed 99% in the approximation of the black-box model through the surrogate one, as measured by the metric of Fidelity, for a compromise of less than 3% absolute reduction in the black-box model's predictive accuracy, compared to single-task and multi-task learning baselines. By improving Fidelity, we can derive more trustworthy explanations of the complex model's outcomes from the surrogate, enabling reliable AI applications for intelligent services at the network edge.
Personalized Federated Learning with Exact Stochastic Gradient Descent
Feb 20, 2022
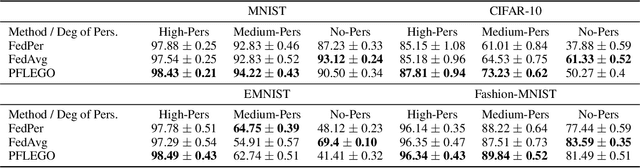


In Federated Learning (FL), datasets across clients tend to be heterogeneous or personalized, and this poses challenges to the convergence of standard FL schemes that do not account for personalization. To address this, we present a new approach for personalized FL that achieves exact stochastic gradient descent (SGD) minimization. We start from the FedPer (Arivazhagan et al., 2019) neural network (NN) architecture for personalization, whereby the NN has two types of layers: the first ones are the common layers across clients, while the few final ones are client-specific and are needed for personalization. We propose a novel SGD-type scheme where, at each optimization round, randomly selected clients perform gradient-descent updates over their client-specific weights towards optimizing the loss function on their own datasets, without updating the common weights. At the final update, each client computes the joint gradient over both client-specific and common weights and returns the gradient of common parameters to the server. This allows to perform an exact and unbiased SGD step over the full set of parameters in a distributed manner, i.e. the updates of the personalized parameters are performed by the clients and those of the common ones by the server. Our method is superior to FedAvg and FedPer baselines in multi-class classification benchmarks such as Omniglot, CIFAR-10, MNIST, Fashion-MNIST, and EMNIST and has much lower computational complexity per round.