 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Federated Learning with Exact Stochastic Gradient Descent
Feb 20, 2022
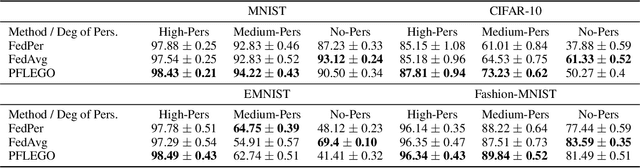


In Federated Learning (FL), datasets across clients tend to be heterogeneous or personalized, and this poses challenges to the convergence of standard FL schemes that do not account for personalization. To address this, we present a new approach for personalized FL that achieves exact stochastic gradient descent (SGD) minimization. We start from the FedPer (Arivazhagan et al., 2019) neural network (NN) architecture for personalization, whereby the NN has two types of layers: the first ones are the common layers across clients, while the few final ones are client-specific and are needed for personalization. We propose a novel SGD-type scheme where, at each optimization round, randomly selected clients perform gradient-descent updates over their client-specific weights towards optimizing the loss function on their own datasets, without updating the common weights. At the final update, each client computes the joint gradient over both client-specific and common weights and returns the gradient of common parameters to the server. This allows to perform an exact and unbiased SGD step over the full set of parameters in a distributed manner, i.e. the updates of the personalized parameters are performed by the clients and those of the common ones by the server. Our method is superior to FedAvg and FedPer baselines in multi-class classification benchmarks such as Omniglot, CIFAR-10, MNIST, Fashion-MNIST, and EMNIST and has much lower computational complexity per round.
Information Theoretic Meta Learning with Gaussian Processes
Oct 05, 2020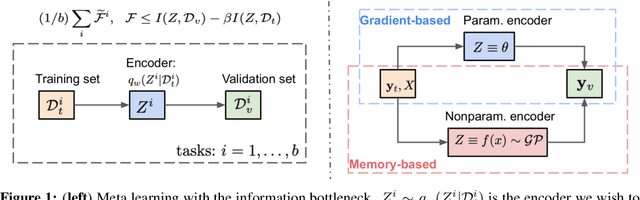

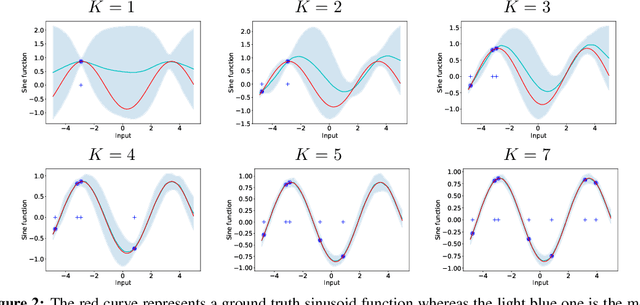
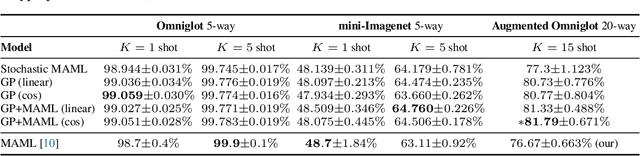
We formulate meta learning using information theoretic concepts such as mutual information and the information bottleneck. The idea is to learn a stochastic representation or encoding of the task description, given by a training or support set, that is highly informative about predicting the validation set. By making use of variational approximations to the mutual information, we derive a general and tractable framework for meta learning. We particularly develop new memory-based meta learning algorithms based on Gaussian processes and derive extensions that combine memory and gradient-based meta learning. We demonstrate our method on few-shot regression and classification by using standard benchmarks such as Omniglot, mini-Imagenet and Augmented Omniglot.
Bayesian Transfer Reinforcement Learning with Prior Knowledge Rules
Sep 30, 2018
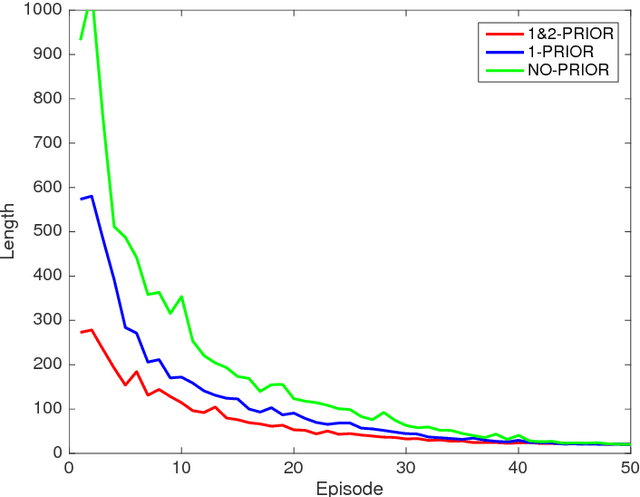
We propose a probabilistic framework to directly insert prior knowledge in reinforcement learning (RL) algorithms by defining the behaviour policy as a Bayesian posterior distribution. Such a posterior combines task specific information with prior knowledge, thus allowing to achieve transfer learning across tasks. The resulting method is flexible and it can be easily incorporated to any standard off-policy and on-policy algorithms, such as those based on temporal differences and policy gradients. We develop a specific instance of this Bayesian transfer RL framework by expressing prior knowledge as general deterministic rules that can be useful in a large variety of tasks, such as navigation tasks. Also, we elaborate more on recent probabilistic and entropy-regularised RL by developing a novel temporal learning algorithm and show how to combine it with Bayesian transfer RL. Finally, we demonstrate our method for solving mazes and show that significant speed ups can be obtained.