 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIFLE: Robust Distillation-based FL for Deep Model Deployment on Resource-Constrained IoT Networks
Feb 09, 2026Federated learning (FL) is a decentralized learning paradigm widely adopted in resource-constrained Internet of Things (IoT) environments. These devices, typically relying on TinyML models, collaboratively train global models by sharing gradients with a central server while preserving data privacy. However, as data heterogeneity and task complexity increase, TinyML models often become insufficient to capture intricate patterns, especially under extreme non-IID (non-independent and identically distributed) conditions. Moreover, ensuring robustness against malicious clients and poisoned updates remains a major challenge. Accordingly, this paper introduces RIFLE - a Robust, distillation-based Federated Learning framework that replaces gradient sharing with logit-based knowledge transfer. By leveraging a knowledge distillation aggregation scheme, RIFLE enables the training of deep models such as VGG-19 and Resnet18 within constrained IoT systems. Furthermore, a Kullback-Leibler (KL) divergence-based validation mechanism quantifies the reliability of client updates without exposing raw data, achieving high trust and privacy preservation simultaneously. Experiments on three benchmark datasets (MNIST, CIFAR-10, and CIFAR-100) under heterogeneous non-IID conditions demonstrate that RIFLE reduces false-positive detections by up to 87.5%, enhances poisoning attack mitigation by 62.5%, and achieves up to 28.3% higher accuracy compared to conventional federated learning baselines within only 10 rounds. Notably, RIFLE reduces VGG19 training time from over 600 days to just 1.39 hours on typical IoT devices (0.3 GFLOPS), making deep learning practical in resource-constrained networks.
Accelerated Training on Low-Power Edge Devices
Feb 25, 2025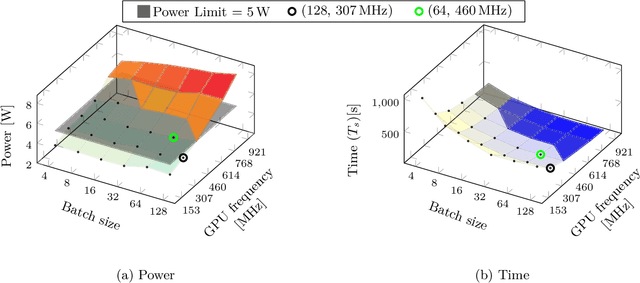
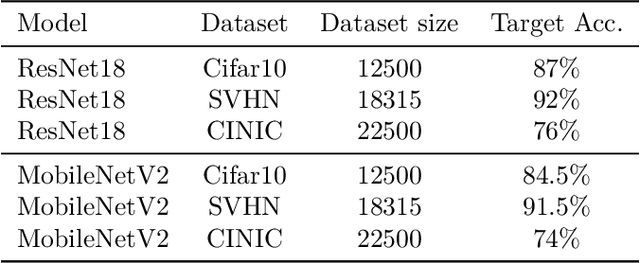
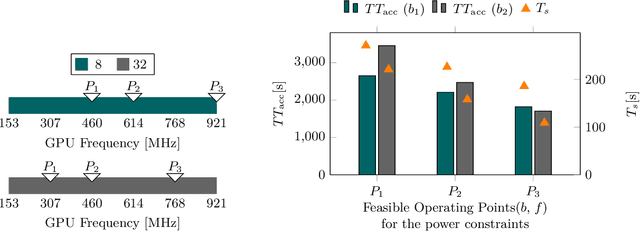
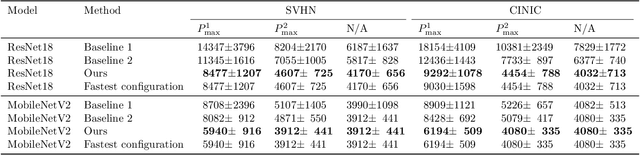
Training on edge devices poses several challenges as these devices are generally resource-constrained, especially in terms of power. State-of-the-art techniques at the device level reduce the GPU frequency to enforce power constraints, leading to a significant increase in training time. To accelerate training, we propose to jointly adjust the system and application parameters (in our case, the GPU frequency and the batch size of the training task) while adhering to the power constraints on devices. We introduce a novel cross-layer methodology that combines predictions of batch size efficiency and device profiling to achieve the desired optimization. Our evaluation on real hardware shows that our method outperforms the current baselines that depend on state of the art techniques, reducing the training time by $2.4\times$ with results very close to optimal. Our measurements also indicate a substantial reduction in the overall energy used for the training process. These gains are achieved without reduction in the performance of the trained model.
Leveraging Highly Approximated Multipliers in DNN Inference
Dec 21, 2024



In this work, we present a control variate approximation technique that enables the exploitation of highly approximate multipliers in Deep Neural Network (DNN) accelerators. Our approach does not require retraining and significantly decreases the induced error due to approximate multiplications, improving the overall inference accuracy. As a result, our approach enables satisfying tight accuracy loss constraints while boosting the power savings. Our experimental evaluation, across six different DNNs and several approximate multipliers, demonstrates the versatility of our approach and shows that compared to the accurate design, our control variate approximation achieves the same performance, 45% power reduction, and less than 1% average accuracy loss. Compared to the corresponding approximate designs without using our technique, our approach improves the accuracy by 1.9x on average.
Efficient Federated Finetuning of Tiny Transformers with Resource-Constrained Devices
Nov 12, 2024



In recent years, Large Language Models (LLMs) through Transformer structures have dominated many machine learning tasks, especially text processing. However, these models require massive amounts of data for training and induce high resource requirements, particularly in terms of the large number of Floating Point Operations (FLOPs) and the high amounts of memory needed. To fine-tune such a model in a parameter-efficient way, techniques like Adapter or LoRA have been developed. However, we observe that the application of LoRA, when used in federated learning (FL), while still being parameter-efficient, is memory and FLOP inefficient. Based on that observation, we develop a novel layer finetuning scheme that allows devices in cross-device FL to make use of pretrained neural networks (NNs) while adhering to given resource constraints. We show that our presented scheme outperforms the current state of the art when dealing with homogeneous or heterogeneous computation and memory constraints and is on par with LoRA regarding limited communication, thereby achieving significantly higher accuracies in FL training.
A Comprehensive Survey of Convolutions in Deep Learning: Applications, Challenges, and Future Trends
Feb 28, 2024In today's digital age, Convolutional Neural Networks (CNNs), a subset of Deep Learning (DL), are widely used for various computer vision tasks such as image classification, object detection, and image segmentation. There are numerous types of CNNs designed to meet specific needs and requirements, including 1D, 2D, and 3D CNNs, as well as dilated, grouped, attention, depthwise convolutions, and NAS, among others. Each type of CNN has its unique structure and characteristics, making it suitable for specific tasks. It's crucial to gain a thorough understanding and perform a comparative analysis of these different CNN types to understand their strengths and weaknesses. Furthermore, studying the performance, limitations, and practical applications of each type of CNN can aid in the development of new and improved architectures in the future. We also dive into the platforms and frameworks that researchers utilize for their research or development from various perspectives. Additionally, we explore the main research fields of CNN like 6D vision, generative models, and meta-learning. This survey paper provides a comprehensive examination and comparison of various CNN architectures, highlighting their architectural differences and emphasizing their respective advantages, disadvantages, applications, challenges, and future trends.
TransAxx: Efficient Transformers with Approximate Computing
Feb 12, 2024Vision Transformer (ViT) models which were recently introduced by the transformer architecture have shown to be very competitive and often become a popular alternative to Convolutional Neural Networks (CNNs). However, the high computational requirements of these models limit their practical applicability especially on low-power devices. Current state-of-the-art employs approximate multipliers to address the highly increased compute demands of DNN accelerators but no prior research has explored their use on ViT models. In this work we propose TransAxx, a framework based on the popular PyTorch library that enables fast inherent support for approximate arithmetic to seamlessly evaluate the impact of approximate computing on DNNs such as ViT models. Using TransAxx we analyze the sensitivity of transformer models on the ImageNet dataset to approximate multiplications and perform approximate-aware finetuning to regain accuracy. Furthermore, we propose a methodology to generate approximate accelerators for ViT models. Our approach uses a Monte Carlo Tree Search (MCTS) algorithm to efficiently search the space of possible configurations using a hardware-driven hand-crafted policy. Our evaluation demonstrates the efficacy of our methodology in achieving significant trade-offs between accuracy and power, resulting in substantial gains without compromising on performance.
Hardware-Aware DNN Compression via Diverse Pruning and Mixed-Precision Quantization
Dec 23, 2023



Deep Neural Networks (DNNs) have shown significant advantages in a wide variety of domains. However, DNNs are becoming computationally intensive and energy hungry at an exponential pace, while at the same time, there is a vast demand for running sophisticated DNN-based services on resource constrained embedded devices. In this paper, we target energy-efficient inference on embedded DNN accelerators. To that end, we propose an automated framework to compress DNNs in a hardware-aware manner by jointly employing pruning and quantization. We explore, for the first time, per-layer fine- and coarse-grained pruning, in the same DNN architecture, in addition to low bit-width mixed-precision quantization for weights and activations. Reinforcement Learning (RL) is used to explore the associated design space and identify the pruning-quantization configuration so that the energy consumption is minimized whilst the prediction accuracy loss is retained at acceptable levels. Using our novel composite RL agent we are able to extract energy-efficient solutions without requiring retraining and/or fine tuning. Our extensive experimental evaluation over widely used DNNs and the CIFAR-10/100 and ImageNet datasets demonstrates that our framework achieves $39\%$ average energy reduction for $1.7\%$ average accuracy loss and outperforms significantly the state-of-the-art approaches.
Federated Learning for Computationally-Constrained Heterogeneous Devices: A Survey
Jul 18, 2023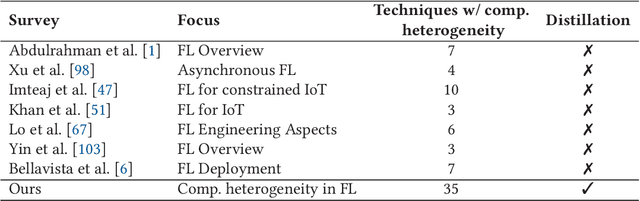
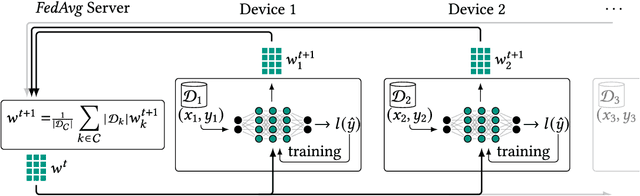
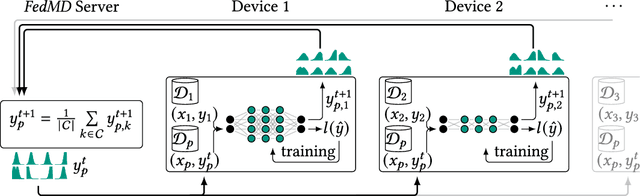

With an increasing number of smart devices like internet of things (IoT) devices deployed in the field, offloadingtraining of neural networks (NNs) to a central server becomes more and more infeasible. Recent efforts toimprove users' privacy have led to on-device learning emerging as an alternative. However, a model trainedonly on a single device, using only local data, is unlikely to reach a high accuracy. Federated learning (FL)has been introduced as a solution, offering a privacy-preserving trade-off between communication overheadand model accuracy by sharing knowledge between devices but disclosing the devices' private data. Theapplicability and the benefit of applying baseline FL are, however, limited in many relevant use cases dueto the heterogeneity present in such environments. In this survey, we outline the heterogeneity challengesFL has to overcome to be widely applicable in real-world applications. We especially focus on the aspect ofcomputation heterogeneity among the participating devices and provide a comprehensive overview of recentworks on heterogeneity-aware FL. We discuss two groups: works that adapt the NN architecture and worksthat approach heterogeneity on a system level, covering Federated Averaging (FedAvg), distillation, and splitlearning-based approaches, as well as synchronous and asynchronous aggregation schemes.
Aggregating Capacity in FL through Successive Layer Training for Computationally-Constrained Devices
May 26, 2023
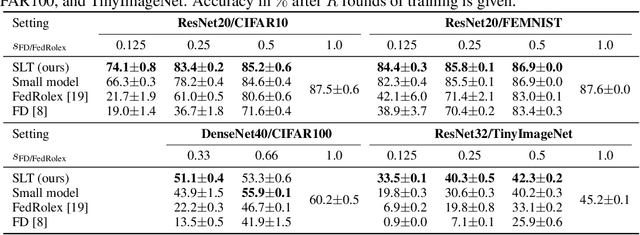

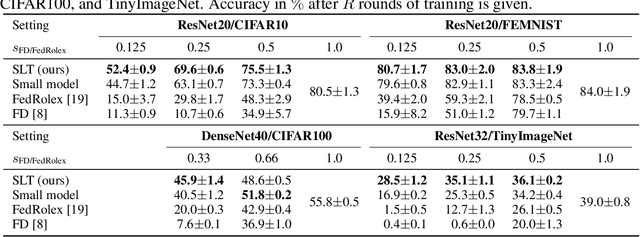
Federated learning (FL) is usually performed on resource-constrained edge devices, e.g., with limited memory for the computation. If the required memory to train a model exceeds this limit, the device will be excluded from the training. This can lead to a lower accuracy as valuable data and computation resources are excluded from training, also causing bias and unfairness. The FL training process should be adjusted to such constraints. The state-of-the-art techniques propose training subsets of the FL model at constrained devices, reducing their resource requirements for training. But these techniques largely limit the co-adaptation among parameters of the model and are highly inefficient, as we show: it is actually better to train a smaller (less accurate) model by the system where all the devices can train the model end-to-end, than applying such techniques. We propose a new method that enables successive freezing and training of the parameters of the FL model at devices, reducing the training's resource requirements at the devices, while still allowing enough co-adaptation between parameters. We show through extensive experimental evaluation that our technique greatly improves the accuracy of the trained model (by 52.4 p.p.) compared with the state of the art, efficiently aggregating the computation capacity available on distributed devices.
Model-to-Circuit Cross-Approximation For Printed Machine Learning Classifiers
Mar 14, 2023



Printed electronics (PE) promises on-demand fabrication, low non-recurring engineering costs, and sub-cent fabrication costs. It also allows for high customization that would be infeasible in silicon, and bespoke architectures prevail to improve the efficiency of emerging PE machine learning (ML) applications. Nevertheless, large feature sizes in PE prohibit the realization of complex ML models in PE, even with bespoke architectures. In this work, we present an automated, cross-layer approximation framework tailored to bespoke architectures that enable complex ML models, such as Multi-Layer Perceptrons (MLPs) and Support Vector Machines (SVMs), in PE. Our framework adopts cooperatively a hardware-driven coefficient approximation of the ML model at algorithmic level, a netlist pruning at logic level, and a voltage over-scaling at the circuit level. Extensive experimental evaluation on 12 MLPs and 12 SVMs and more than 6000 approximate and exact designs demonstrates that our model-to-circuit cross-approximation delivers power and area optimal designs that, compared to the state-of-the-art exact designs, feature on average 51% and 66% area and power reduction, respectively, for less than 5% accuracy loss. Finally, we demonstrate that our framework enables 80% of the examined classifiers to be battery-powered with almost identical accuracy with the exact designs, paving thus the way towards smart complex printed applications.