 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Capacity in FL through Successive Layer Training for Computationally-Constrained Devices
Paper and Code
May 26, 2023
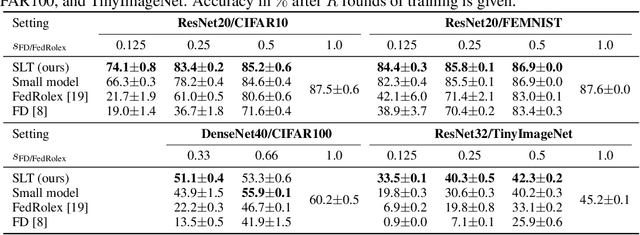

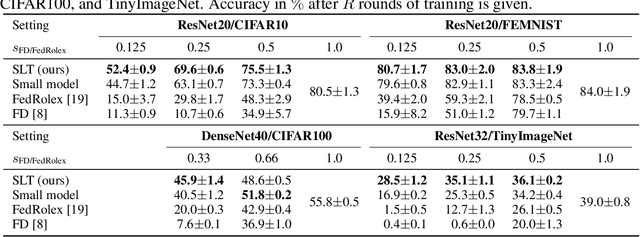
Federated learning (FL) is usually performed on resource-constrained edge devices, e.g., with limited memory for the computation. If the required memory to train a model exceeds this limit, the device will be excluded from the training. This can lead to a lower accuracy as valuable data and computation resources are excluded from training, also causing bias and unfairness. The FL training process should be adjusted to such constraints. The state-of-the-art techniques propose training subsets of the FL model at constrained devices, reducing their resource requirements for training. But these techniques largely limit the co-adaptation among parameters of the model and are highly inefficient, as we show: it is actually better to train a smaller (less accurate) model by the system where all the devices can train the model end-to-end, than applying such techniques. We propose a new method that enables successive freezing and training of the parameters of the FL model at devices, reducing the training's resource requirements at the devices, while still allowing enough co-adaptation between parameters. We show through extensive experimental evaluation that our technique greatly improves the accuracy of the trained model (by 52.4 p.p.) compared with the state of the art, efficiently aggregating the computation capacity available on distributed devices.