 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Training on Low-Power Edge Devices
Feb 25, 2025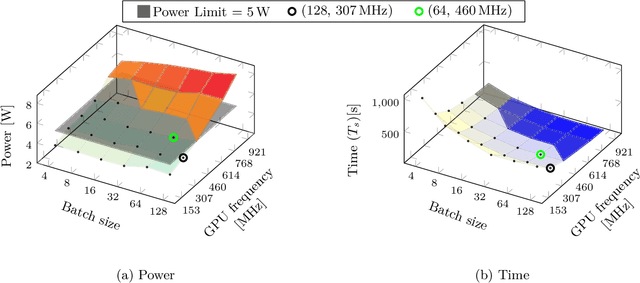
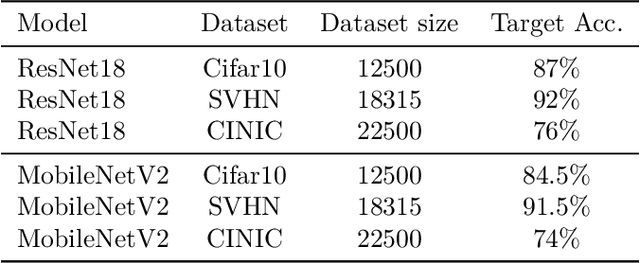
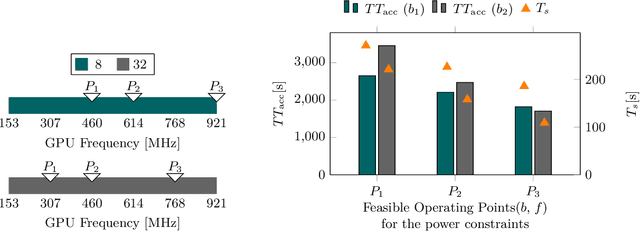
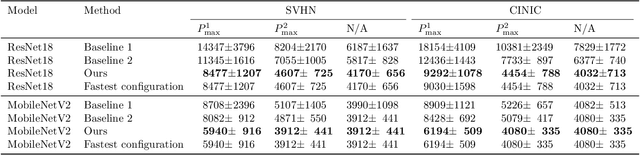
Training on edge devices poses several challenges as these devices are generally resource-constrained, especially in terms of power. State-of-the-art techniques at the device level reduce the GPU frequency to enforce power constraints, leading to a significant increase in training time. To accelerate training, we propose to jointly adjust the system and application parameters (in our case, the GPU frequency and the batch size of the training task) while adhering to the power constraints on devices. We introduce a novel cross-layer methodology that combines predictions of batch size efficiency and device profiling to achieve the desired optimization. Our evaluation on real hardware shows that our method outperforms the current baselines that depend on state of the art techniques, reducing the training time by $2.4\times$ with results very close to optimal. Our measurements also indicate a substantial reduction in the overall energy used for the training process. These gains are achieved without reduction in the performance of the trained model.
Efficient Federated Finetuning of Tiny Transformers with Resource-Constrained Devices
Nov 12, 2024



In recent years, Large Language Models (LLMs) through Transformer structures have dominated many machine learning tasks, especially text processing. However, these models require massive amounts of data for training and induce high resource requirements, particularly in terms of the large number of Floating Point Operations (FLOPs) and the high amounts of memory needed. To fine-tune such a model in a parameter-efficient way, techniques like Adapter or LoRA have been developed. However, we observe that the application of LoRA, when used in federated learning (FL), while still being parameter-efficient, is memory and FLOP inefficient. Based on that observation, we develop a novel layer finetuning scheme that allows devices in cross-device FL to make use of pretrained neural networks (NNs) while adhering to given resource constraints. We show that our presented scheme outperforms the current state of the art when dealing with homogeneous or heterogeneous computation and memory constraints and is on par with LoRA regarding limited communication, thereby achieving significantly higher accuracies in FL training.
Federated Learning for Computationally-Constrained Heterogeneous Devices: A Survey
Jul 18, 2023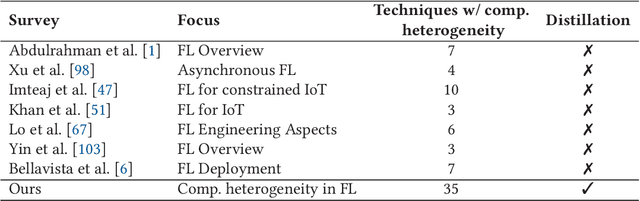
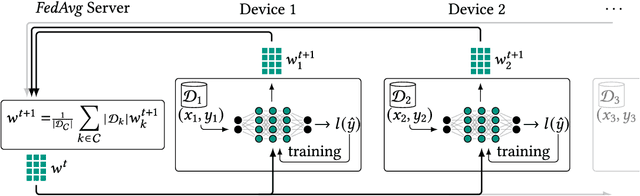
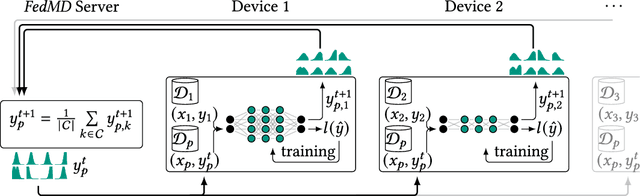

With an increasing number of smart devices like internet of things (IoT) devices deployed in the field, offloadingtraining of neural networks (NNs) to a central server becomes more and more infeasible. Recent efforts toimprove users' privacy have led to on-device learning emerging as an alternative. However, a model trainedonly on a single device, using only local data, is unlikely to reach a high accuracy. Federated learning (FL)has been introduced as a solution, offering a privacy-preserving trade-off between communication overheadand model accuracy by sharing knowledge between devices but disclosing the devices' private data. Theapplicability and the benefit of applying baseline FL are, however, limited in many relevant use cases dueto the heterogeneity present in such environments. In this survey, we outline the heterogeneity challengesFL has to overcome to be widely applicable in real-world applications. We especially focus on the aspect ofcomputation heterogeneity among the participating devices and provide a comprehensive overview of recentworks on heterogeneity-aware FL. We discuss two groups: works that adapt the NN architecture and worksthat approach heterogeneity on a system level, covering Federated Averaging (FedAvg), distillation, and splitlearning-based approaches, as well as synchronous and asynchronous aggregation schemes.
Aggregating Capacity in FL through Successive Layer Training for Computationally-Constrained Devices
May 26, 2023
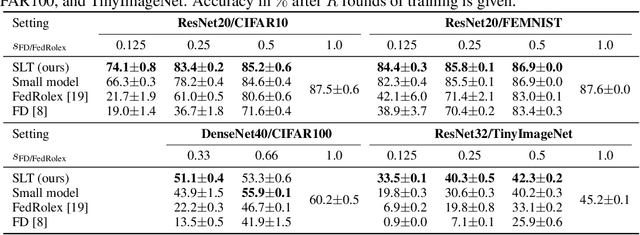

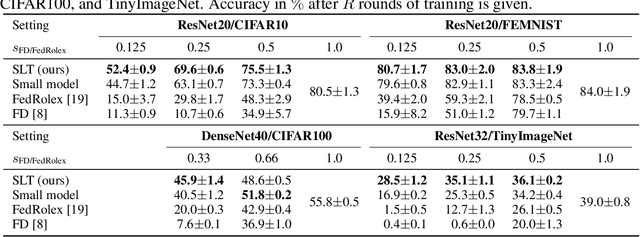
Federated learning (FL) is usually performed on resource-constrained edge devices, e.g., with limited memory for the computation. If the required memory to train a model exceeds this limit, the device will be excluded from the training. This can lead to a lower accuracy as valuable data and computation resources are excluded from training, also causing bias and unfairness. The FL training process should be adjusted to such constraints. The state-of-the-art techniques propose training subsets of the FL model at constrained devices, reducing their resource requirements for training. But these techniques largely limit the co-adaptation among parameters of the model and are highly inefficient, as we show: it is actually better to train a smaller (less accurate) model by the system where all the devices can train the model end-to-end, than applying such techniques. We propose a new method that enables successive freezing and training of the parameters of the FL model at devices, reducing the training's resource requirements at the devices, while still allowing enough co-adaptation between parameters. We show through extensive experimental evaluation that our technique greatly improves the accuracy of the trained model (by 52.4 p.p.) compared with the state of the art, efficiently aggregating the computation capacity available on distributed devices.
CoCo-FL: Communication- and Computation-Aware Federated Learning via Partial NN Freezing and Quantization
Mar 10, 2022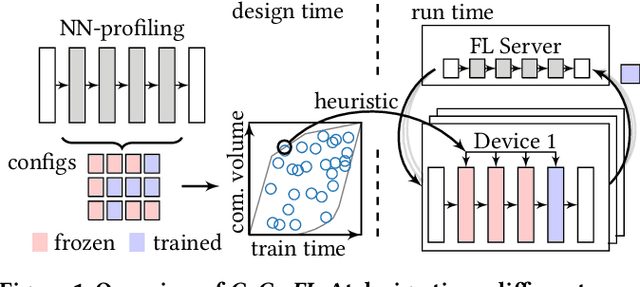
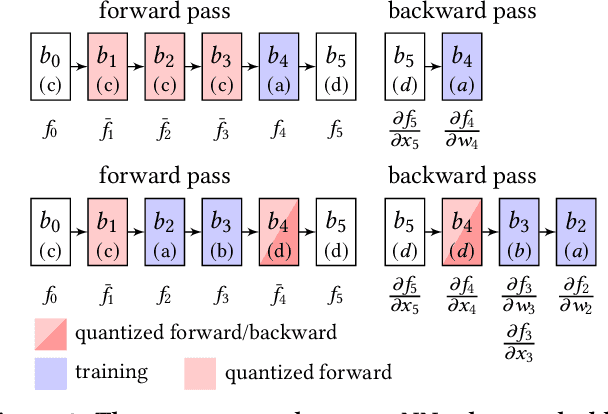
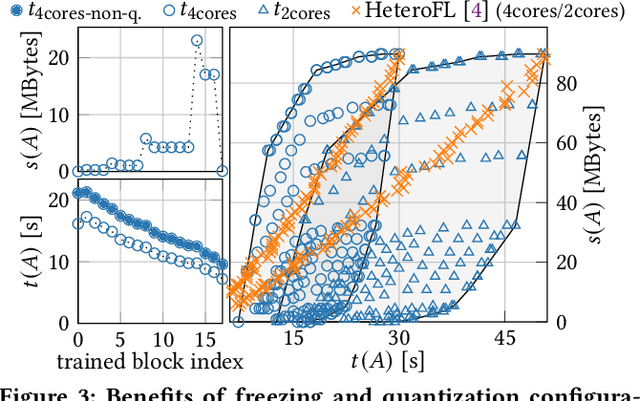
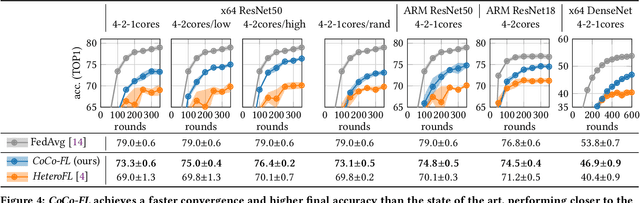
Devices participating in federated learning (FL) typically have heterogeneous communication and computation resources. However, all devices need to finish training by the same deadline dictated by the server when applying synchronous FL, as we consider in this paper. Reducing the complexity of the trained neural network (NN) at constrained devices, i.e., by dropping neurons/filters, is insufficient as it tightly couples reductions in communication and computation requirements, wasting resources. Quantization has proven effective to accelerate inference, but quantized training suffers from accuracy losses. We present a novel mechanism that quantizes during training parts of the NN to reduce the computation requirements, freezes them to reduce the communication and computation requirements, and trains the remaining parts in full precision to maintain a high convergence speed and final accuracy. Using this mechanism, we present the first FL technique that independently optimizes for specific communication and computation constraints in FL: CoCo-FL. We show that CoCo-FL reaches a much higher convergence speed than the state of the art and a significantly higher final accuracy.
DISTREAL: Distributed Resource-Aware Learning in Heterogeneous Systems
Dec 16, 2021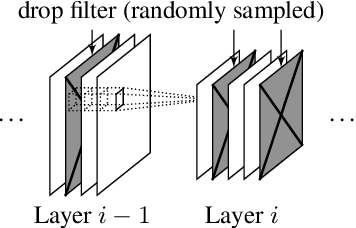
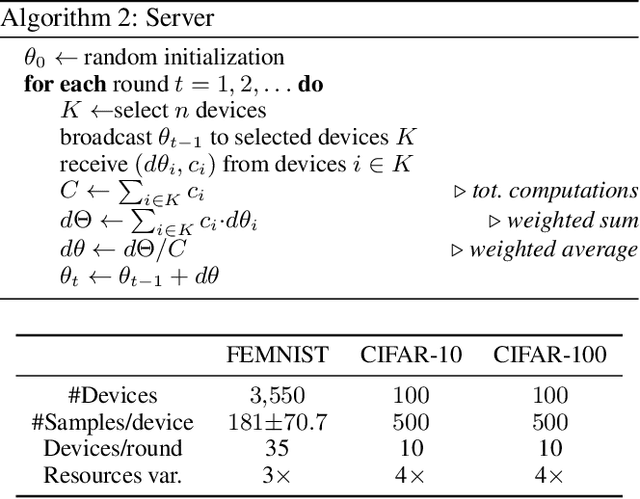
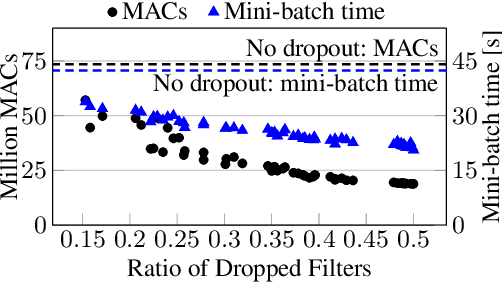

We study the problem of distributed training of neural networks (NNs) on devices with heterogeneous, limited, and time-varying availability of computational resources. We present an adaptive, resource-aware, on-device learning mechanism, DISTREAL, which is able to fully and efficiently utilize the available resources on devices in a distributed manner, increasing the convergence speed. This is achieved with a dropout mechanism that dynamically adjusts the computational complexity of training an NN by randomly dropping filters of convolutional layers of the model. Our main contribution is the introduction of a design space exploration (DSE) technique, which finds Pareto-optimal per-layer dropout vectors with respect to resource requirements and convergence speed of the training. Applying this technique, each device is able to dynamically select the dropout vector that fits its available resource without requiring any assistance from the server. We implement our solution in a federated learning (FL) system, where the availability of computational resources varies both between devices and over time, and show through extensive evaluation that we are able to significantly increase the convergence speed over the state of the art without compromising on the final accuracy.
Visual Person Understanding through Multi-Task and Multi-Dataset Learning
Jun 07, 2019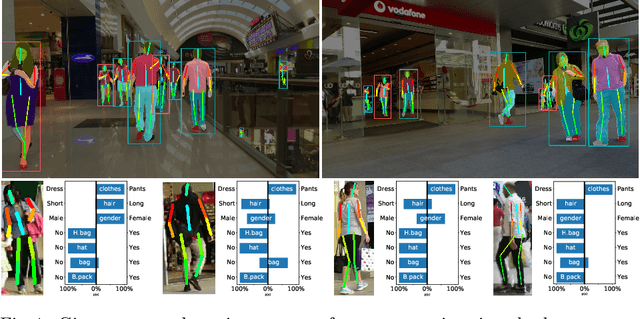
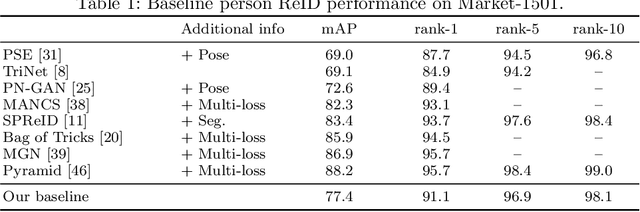
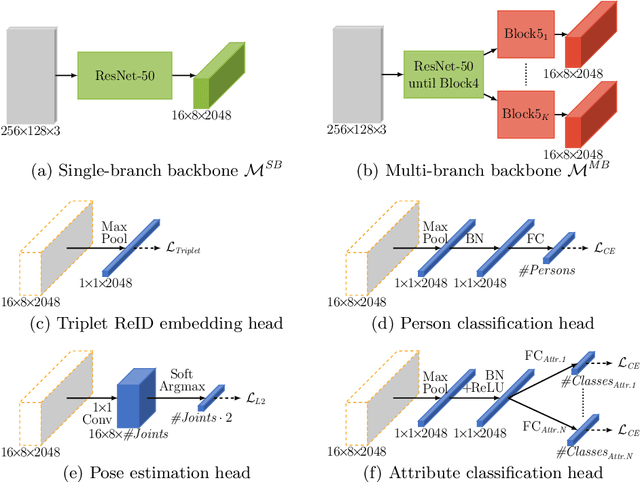

We address the problem of learning a single model for person re-identification, attribute classification, body part segmentation, and pose estimation. With predictions for these tasks we gain a more holistic understanding of persons, which is valuable for many applications. This is a classical multi-task learning problem. However, no dataset exists that these tasks could be jointly learned from. Hence several datasets need to be combined during training, which in other contexts has often led to reduced performance in the past. We extensively evaluate how the different task and datasets influence each other and how different degrees of parameter sharing between the tasks affect performance. Our final model matches or outperforms its single-task counterparts without creating significant computational overhead, rendering it highly interesting for resource-constrained scenarios such as mobile robotics.