 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSplat3D: Open-Vocabulary 3D Instance Segmentation using Gaussian Splatting
Jun 09, 20253D Gaussian Splatting (3DGS) has emerged as a powerful representation for neural scene reconstruction, offering high-quality novel view synthesis while maintaining computational efficiency. In this paper, we extend the capabilities of 3DGS beyond pure scene representation by introducing an approach for open-vocabulary 3D instance segmentation without requiring manual labeling, termed OpenSplat3D. Our method leverages feature-splatting techniques to associate semantic information with individual Gaussians, enabling fine-grained scene understanding. We incorporate Segment Anything Model instance masks with a contrastive loss formulation as guidance for the instance features to achieve accurate instance-level segmentation. Furthermore, we utilize language embeddings of a vision-language model, allowing for flexible, text-driven instance identification. This combination enables our system to identify and segment arbitrary objects in 3D scenes based on natural language descriptions. We show results on LERF-mask and LERF-OVS as well as the full ScanNet++ validation set, demonstrating the effectiveness of our approach.
How Important are Videos for Training Video LLMs?
Jun 07, 2025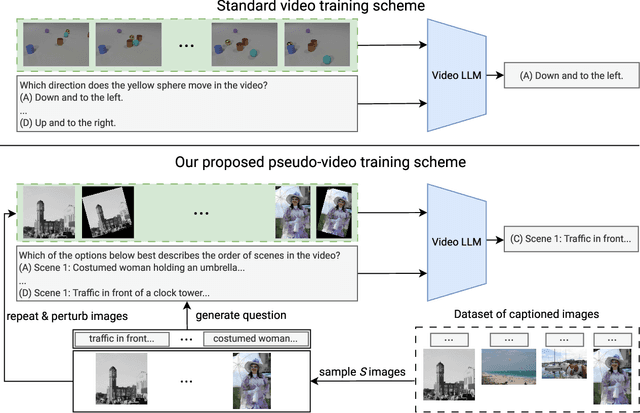

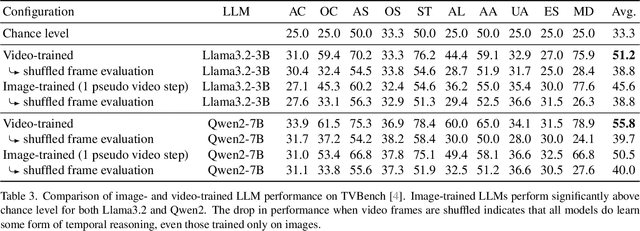
Research into Video Large Language Models (LLMs) has progressed rapidly, with numerous models and benchmarks emerging in just a few years. Typically, these models are initialized with a pretrained text-only LLM and finetuned on both image- and video-caption datasets. In this paper, we present findings indicating that Video LLMs are more capable of temporal reasoning after image-only training than one would assume, and that improvements from video-specific training are surprisingly small. Specifically, we show that image-trained versions of two LLMs trained with the recent LongVU algorithm perform significantly above chance level on TVBench, a temporal reasoning benchmark. Additionally, we introduce a simple finetuning scheme involving sequences of annotated images and questions targeting temporal capabilities. This baseline results in temporal reasoning performance close to, and occasionally higher than, what is achieved by video-trained LLMs. This suggests suboptimal utilization of rich temporal features found in real video by current models. Our analysis motivates further research into the mechanisms that allow image-trained LLMs to perform temporal reasoning, as well as into the bottlenecks that render current video training schemes inefficient.
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation
Mar 24, 2025Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D vision remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a simple yet effective approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we further propose to distill 2D foundation models into a 3D backbone as a pretraining task. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets.
Your ViT is Secretly an Image Segmentation Model
Mar 24, 2025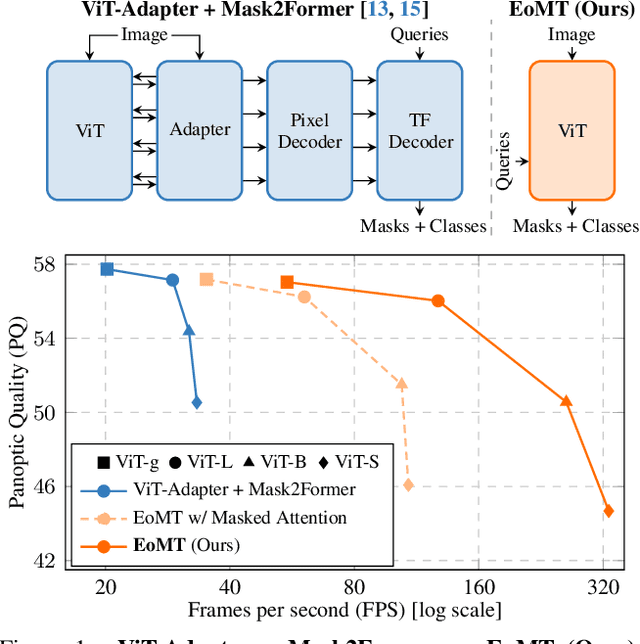
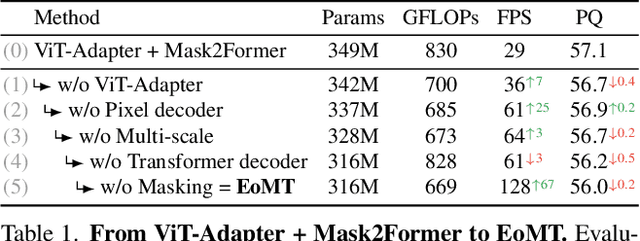
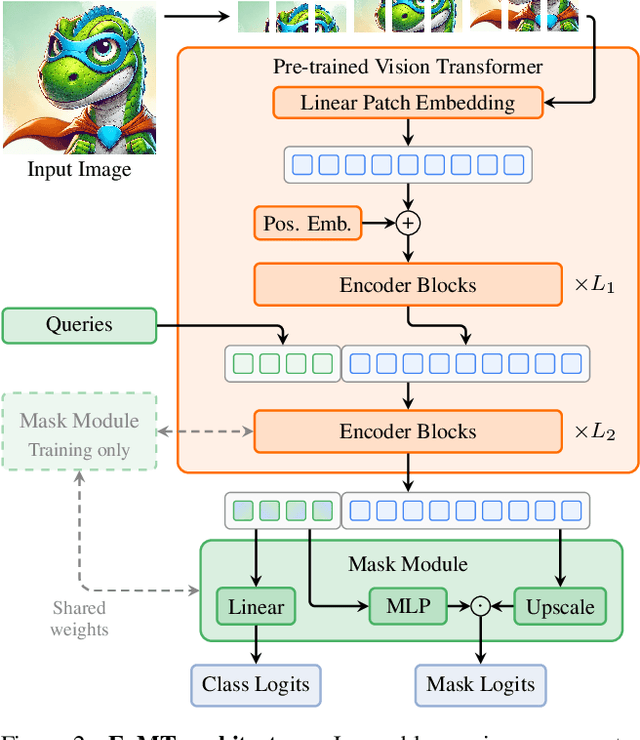
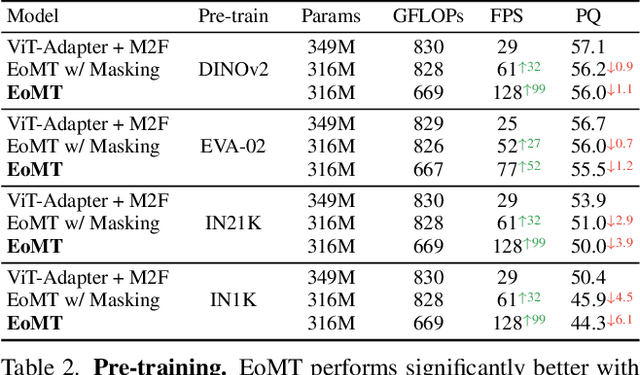
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4x faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
MaskTerial: A Foundation Model for Automated 2D Material Flake Detection
Dec 12, 2024



The detection and classification of exfoliated two-dimensional (2D) material flakes from optical microscope images can be automated using computer vision algorithms. This has the potential to increase the accuracy and objectivity of classification and the efficiency of sample fabrication, and it allows for large-scale data collection. Existing algorithms often exhibit challenges in identifying low-contrast materials and typically require large amounts of training data. Here, we present a deep learning model, called MaskTerial, that uses an instance segmentation network to reliably identify 2D material flakes. The model is extensively pre-trained using a synthetic data generator, that generates realistic microscopy images from unlabeled data. This results in a model that can to quickly adapt to new materials with as little as 5 to 10 images. Furthermore, an uncertainty estimation model is used to finally classify the predictions based on optical contrast. We evaluate our method on eight different datasets comprising five different 2D materials and demonstrate significant improvements over existing techniques in the detection of low-contrast materials such as hexagonal boron nitride.
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
Sep 17, 2024



Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200$\times$ faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
OoDIS: Anomaly Instance Segmentation Benchmark
Jun 17, 2024



Autonomous vehicles require a precise understanding of their environment to navigate safely. Reliable identification of unknown objects, especially those that are absent during training, such as wild animals, is critical due to their potential to cause serious accidents. Significant progress in semantic segmentation of anomalies has been driven by the availability of out-of-distribution (OOD) benchmarks. However, a comprehensive understanding of scene dynamics requires the segmentation of individual objects, and thus the segmentation of instances is essential. Development in this area has been lagging, largely due to the lack of dedicated benchmarks. To address this gap, we have extended the most commonly used anomaly segmentation benchmarks to include the instance segmentation task. Our evaluation of anomaly instance segmentation methods shows that this challenge remains an unsolved problem. The benchmark website and the competition page can be found at: https://vision.rwth-aachen.de/oodis .
An Ordinal Regression Framework for a Deep Learning Based Severity Assessment for Chest Radiographs
Feb 08, 2024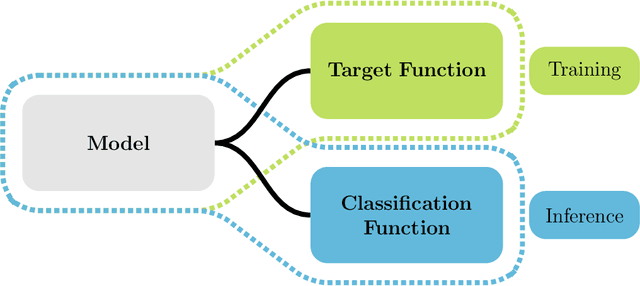
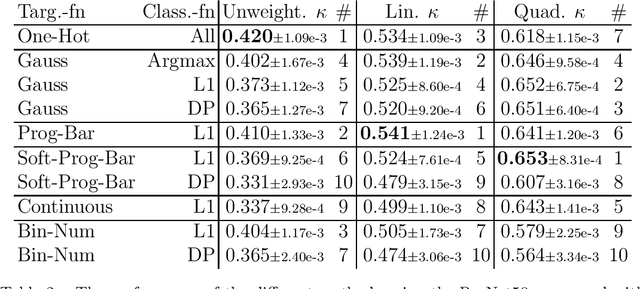
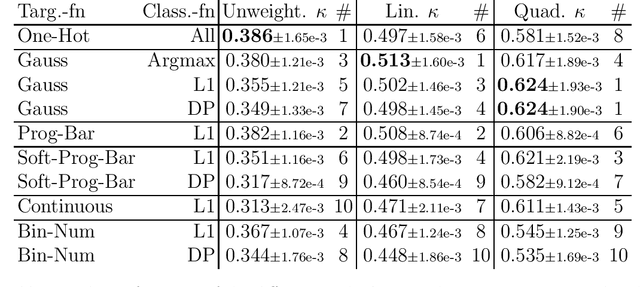
This study investigates the application of ordinal regression methods for categorizing disease severity in chest radiographs. We propose a framework that divides the ordinal regression problem into three parts: a model, a target function, and a classification function. Different encoding methods, including one-hot, Gaussian, progress-bar, and our soft-progress-bar, are applied using ResNet50 and ViT-B-16 deep learning models. We show that the choice of encoding has a strong impact on performance and that the best encoding depends on the chosen weighting of Cohen's kappa and also on the model architecture used. We make our code publicly available on GitHub.
Cyto R-CNN and CytoNuke Dataset: Towards reliable whole-cell segmentation in bright-field histological images
Feb 04, 2024Background: Cell segmentation in bright-field histological slides is a crucial topic in medical image analysis. Having access to accurate segmentation allows researchers to examine the relationship between cellular morphology and clinical observations. Unfortunately, most segmentation methods known today are limited to nuclei and cannot segmentate the cytoplasm. Material & Methods: We present a new network architecture Cyto R-CNN that is able to accurately segment whole cells (with both the nucleus and the cytoplasm) in bright-field images. We also present a new dataset CytoNuke, consisting of multiple thousand manual annotations of head and neck squamous cell carcinoma cells. Utilizing this dataset, we compared the performance of Cyto R-CNN to other popular cell segmentation algorithms, including QuPath's built-in algorithm, StarDist and Cellpose. To evaluate segmentation performance, we calculated AP50, AP75 and measured 17 morphological and staining-related features for all detected cells. We compared these measurements to the gold standard of manual segmentation using the Kolmogorov-Smirnov test. Results: Cyto R-CNN achieved an AP50 of 58.65% and an AP75 of 11.56% in whole-cell segmentation, outperforming all other methods (QuPath $19.46/0.91\%$; StarDist $45.33/2.32\%$; Cellpose $31.85/5.61\%$). Cell features derived from Cyto R-CNN showed the best agreement to the gold standard ($\bar{D} = 0.15$) outperforming QuPath ($\bar{D} = 0.22$), StarDist ($\bar{D} = 0.25$) and Cellpose ($\bar{D} = 0.23$). Conclusion: Our newly proposed Cyto R-CNN architecture outperforms current algorithms in whole-cell segmentation while providing more reliable cell measurements than any other model. This could improve digital pathology workflows, potentially leading to improved diagnosis. Moreover, our published dataset can be used to develop further models in the future.
UGainS: Uncertainty Guided Anomaly Instance Segmentation
Aug 03, 2023
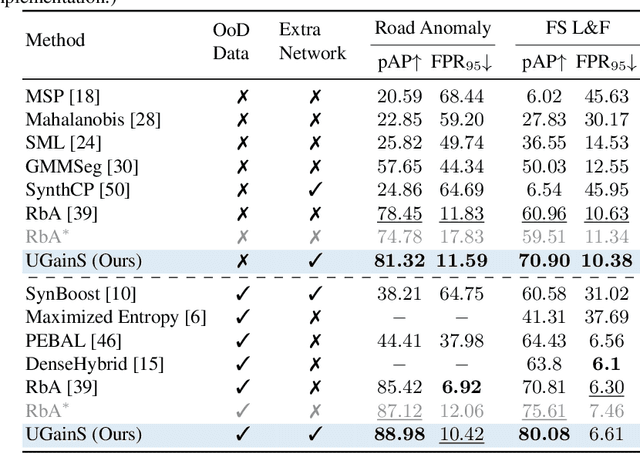
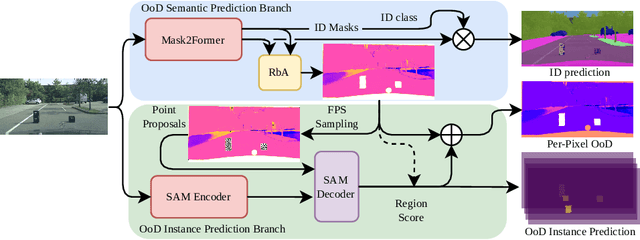
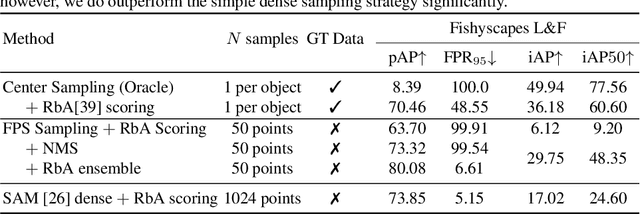
A single unexpected object on the road can cause an accident or may lead to injuries. To prevent this, we need a reliable mechanism for finding anomalous objects on the road. This task, called anomaly segmentation, can be a stepping stone to safe and reliable autonomous driving. Current approaches tackle anomaly segmentation by assigning an anomaly score to each pixel and by grouping anomalous regions using simple heuristics. However, pixel grouping is a limiting factor when it comes to evaluating the segmentation performance of individual anomalous objects. To address the issue of grouping multiple anomaly instances into one, we propose an approach that produces accurate anomaly instance masks. Our approach centers on an out-of-distribution segmentation model for identifying uncertain regions and a strong generalist segmentation model for anomaly instances segmentation. We investigate ways to use uncertain regions to guide such a segmentation model to perform segmentation of anomalous instances. By incorporating strong object priors from a generalist model we additionally improve the per-pixel anomaly segmentation performance. Our approach outperforms current pixel-level anomaly segmentation methods, achieving an AP of 80.08% and 88.98% on the Fishyscapes Lost and Found and the RoadAnomaly validation sets respectively. Project page: https://vision.rwth-aachen.de/ugains